PAXOS: libevent_paxos
来源:互联网 发布:js 冒号语法 编辑:程序博客网 时间:2024/06/01 07:11
PAXOS实现 —— libevent_paxos
该文章是项目的一部分,主要讲PAXOS算法的实现。
Qiushan, Shandong University
Part I Start
Part II PAXOS
Part III Architecture
Part IV Performance
Part V Skills
Part I Generated on November 15, 2014 (Start)
The libevent_paxos ensures that all replicas of an application(e.g., apache) receive a consistent total order of requests(i.e., socket operations) despite of a small number of replicas fail. That's why we used paxos.

To begin with, let's read Paxos Made Practical carefully. Below is a figure in it:
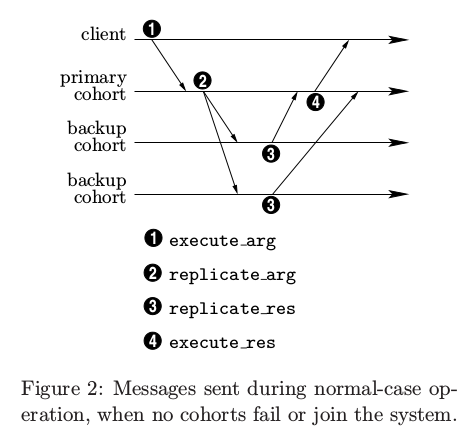
1) In libevent_paxos, when a client connects with a PROXY via socket, then it sends a message ‘clientx:send’ to the proxy. When the connection is established, it will trigger a listener callback function called proxy_on_accept. Then when the message arrives at the proxy, it will trigger another listener callback function called client_side_on_read, the function will handle the message. Then client_process_data will be called, and in the function build_req_sub_msg will be invoked, it is responsible for building formal message (REQUEST_SUBMIT). Then the message will be sent to &proxy->sys_addr.c_addr,in another word, the corresponding consensus, the message will be sent to127.0.0.1:8000. And then the consensus will handle the coming message with handle_request_submit,handle_request_sumbit will invoke consensus_submit_request, if the current node is the leader, consensus_submit_request will use leader_handle_submit_req to combine the request message from the client with a view_stamp which is generated by function get_next_view_stamp. And then in leader_handle_submit_req, the new request message with type ACCEPT_REQ will be built by function build_accept_req, and then the message will be broadcasted to the other replicas via function uc (i.e.send_for_consensus_comp). In fact the process is just like the phase 1-2 of the following figure which cited from the paper Paxos Made Practical.
2) In the figure, 3 is replicate_res which is the acknowledge that backups make after receiving the request information from the primary.In libevent_paxos, it should correspond to
handle_accept_req (src/consensus/consensus.c)
// build the reply to the leader accept_ack* reply = build_accept_ack(comp,&msg->msg_vs);
After seeing build_accept_ack, we can find that what backups deliver to the primary is:
msg->node_id = comp->node_id;
msg->msg_vs = *vs;
msg->header.msg_type = ACCEPT_ACK;
which is similar to replicate_res in the paper:

So libevent_paxos also follows what Paxos Made Practical said.
Next for libevent_paxos should be execute the request after receiving a majority of replicas' acknowledge. The execution should be
handle_accept_ack
try_to_execute
leader_try_to_execute
And how to send the ack to the primary, it is the function uc (a.k.a send_for_consensus_comp), let's see it.
// consensus partstatic void send_for_consensus_comp(node* my_node,size_t data_size,void* data,int target){ consensus_msg* msg = build_consensus_msg(data_size,data); if(NULL==msg){ goto send_for_consensus_comp_exit; } // means send to every node except me if(target<0){ for(uint32_t i=0;i<my_node->group_size;i++){ if(i!=my_node->node_id && my_node->peer_pool[i].active){ struct bufferevent* buff = my_node->peer_pool[i].my_buff_event; bufferevent_write(buff,msg,CONSENSUS_MSG_SIZE(msg)); SYS_LOG(my_node, "Send Consensus Msg To Node %u\n",i); } } }else{ if(target!=(int)my_node->node_id&&my_node->peer_pool[target].active){ struct bufferevent* buff = my_node->peer_pool[target].my_buff_event; bufferevent_write(buff,msg,CONSENSUS_MSG_SIZE(msg)); SYS_LOG(my_node, "Send Consensus Msg To Node %u.\n",target); } }send_for_consensus_comp_exit: if(msg!=NULL){ free(msg); } return;}So, uc sees to delivering the message between the primary and the backups. For the same reason, when a client request arrives at the primary, the primary also uses uc (a.k.a send_for_consensus_comp) to broadcast the request information to backups.
3) Next there is 4 left to be explained.
group_size = 3;
leader_try_to_execute{ if(reached_quorum(record_data,comp->group_size)) { SYS_LOG(comp,"Node %d : View Stamp%u : %u Has Reached Quorum.\n",…) SYS_LOG(comp,"Before Node %d IncExecute %u : %u.\n",…) SYS_LOG(comp,"After Node %d Inc Execute %u : %u.\n",…) }} static int reached_quorum(request_record*record,int group_size){ // this may be compatibility issue if(__builtin_popcountl(record->bit_map)>=((group_size/2)+1)){ return 1; }else{ return 0; }}__builtin_popcountl which comes from GCC can calculate the number of 1 accurately.
So next we should pay attention to the data structure record->bit_map.
In concensus.c
typedef struct request_record_t{ struct timeval created_time; // data created timestamp char is_closed; uint64_t bit_map; // now we assume the maximal replica group size is 64; size_t data_size; // data size char data[0]; // real data}__attribute__((packed))request_record;
Before our further exploration, let us suppose that the leader needs to use the bit_map to record that how many replicas has accepted the request that it proposed, and iff the number reaches the quorum (i.e. majority, i.e. (group_size/2)+1),the leader can execute the request. So based on the assumption, there must be a place where recording the number of ACCEPT ACK, and it should be after the leader has received the ACCEPT ACK messages which come from the other replicas.Let’s find the place, verifying our hypothesis.
consensus_handle_msg{ case ACCEPT_ACK: handle_accept_ack(comp,data) { update_record(record_data,msg->node_id) { record->bit_map= (record->bit_map | (1<<node_id)); //debug_log("the record bit map isupdated to %x\n",record->bit_map); } }}So our assumption is correct, and meanwhile through the expression
record->bit_map | (1<<node_id)
we could see that the number of 1 in record->bit_map is the number of replicas which has sent ACCEPT_ACK.
Evaluation Framework
- Python script
./eval.py apache_ab.cfg
- DEBUG Logs: proxy-req.log | proxy-sys.log | consensus-sys.log
node-0-proxy-req.log:
1418002395 : 1418002395.415361,1418002395.415362,1418002395.416476,1418002395.416476
Operation: Connects.
1418002395 : 1418002395.415617,1418002395.415619,1418002395.416576,1418002395.416576
Operation: Sends data: (START):client0:send:(END)
1418002395 : 1418002395.416275,1418002395.416276,1418002395.417113,1418002395.417113
Operation: Closes.
About proxy-req.log, what's the meaning of 1418002395 : 1418002395.415361,1418002395.415362,1418002395.416476,1418002395.416476
fprintf(output,"%lu : %lu.%06lu,%lu.%06lu,%lu.%06lu,%lu.%06lu\n",header->connection_id,
header->received_time.tv_sec,header->received_time.tv_usec,
header->created_time.tv_sec,header->created_time.tv_usec,
endtime.tv_sec,endtime.tv_usec,endtime.tv_sec,endtime.tv_usec);
It shows the received time, created time and end time of the operation.
- Google Spreadsheets
consensus mean(us)w/ proxy
consensus s.t.d.w/ proxy
response mean(us)w/ proxy
response s.t.d.w/ proxy
throughput(Req/s)w/ proxy
server mean(us)w/ proxy
server throughput(Req/s)w/o proxy
server mean(us)w/o proxy
server throughput(Req/s)overhead
mean(us)notesMongooseAb10310100543411784.41263712137.4126711125.5760241660.0318655361.934159 MongooseAb100310100583849650.15215138.119992.33715145.302485.93616216616.6913157605.7214901 MongooseAb1003501005781217456.4117694.9318459.1617518.625127.98970611708.157448704.7464867 ApacheAb10310100557710093.315218.310359.615281.81963.4471101406.47360827713502 ApacheAb100310100574678402.19813664.708671.92513686.522624.66212967771.1614726792.5611495 ApacheAb1003501005561913596.6713676.4314492.7513680.935836.98870596708.2683286004.262268

update to Beijing Time 00:29 AM Dec. 9 2014 & New York Time 11:29 AM Dec. 8 2014
Part II Generated on November 27, 2014 (PAXOS)
PAXOS
- Prepare request -> ACK (from acceptors) ->proposal (accept request, proposal’s value comes from the value of the highest-numbered proposal among the responses from acceptor) -> ACK (from acceptor, accepting the proposal, unless it has already responded to a prepare request having a number greater than n.)
- Leader is the only proposer that tries to issue proposals.
- When the proposer receive the majority ACCEPT ACK, it can execute the request.
- To guarantee consensus, P2a focuses on acceptors, and their every higher-numbered proposal. While P2b focuses on proposer, and its every higher-numbered proposal. So P2b is more powerful than P2a.
- If a proposal with number n and value v is chosen, why should not a higher-numbered proposal arriving at and accepted by acceptors have a value which different from v? Let’s extract the answer from Paxos Made Simple.
P1. An acceptor must accept the first proposal that it receives.
P2a . If aproposal with value v is chosen,then every higher-numbered proposal accepted by any acceptor has value v.
We still maintain P1 to ensure that some proposal is chosen. Because communication is asynchronous, a proposal could be chosen with some particular acceptor c never having received any proposal. Suppose a new proposer “wakes up” and issues a higher-numbered proposal with a different value. P1 requires c to accept this proposal, violating P2a . Maintaining both P1 and P2a requires strengthening P2a to:
P2b . If aproposal with value v is chosen,then every higher-numbered proposal issued by any proposer has value v.
Libevent_PAXOS
- Libevent_paxos removes PREPARE
- There are still some concepts about view_stamp need to be figured out:
msg->msg_vs
msg->req_canbe_exed
comp->highest_committed_vs
comp->highest_seen_vs
comp->highest_to_commit_vs

highest_to_commit_vs indicates which operation should be delivered next time.
highest_committed_vs indicates which operation has been delivered recently.
highest_seen_vs indicates which operations have been marked and stored in db.
update to Beijing Time 2015/02/01
Part III Generated on November 30, 2014 (Architecture)
Firstly, please see the chain:
SIGUSR2(consensus side) -> proxy_singnal_handler(proxy side) -> real_do_action -> do_action_to_server -> do_action_send -> Apache server(server side)
Next wake_up generates SIGUSR2 ?
static void wake_up(proxy_node* proxy){ //SYS_LOG(proxy,"In Wake Up,TheHighest Rec Is %lu.\n",proxy->highest_rec); PROXY_ENTER(proxy); pthread_kill(proxy->p_self,SIGUSR2); PROXY_LEAVE(proxy);}update_state (a.k.a consensus_component* comp->ucb)-> wake_up
leader_try_to_execute-> deliver_msg_data -> update_state
try_to_execute -> deliver_msg_data -> update_state
Raw socket operation -> ACCEPT_REQ -> ACCEPT_ACK -> handle_accept_ack -> try_to_execute -> leader_try_to_execute

update to Beijing Time 2015/02/01
Part IV Generated on December 9, 2014 (Performance)
- Run python scripts and watch logs
- What's the root cause of performance issue?
- Another blog tells the root cause: VENUS
- Serialization: avoid or necessary?

2) But when I do this setting in apache_ab.cfg:
SERVER_COUNT=1
CLIENT_COUNT=1
CLIENT_PROGRAM=$MSMR_ROOT/apps/apache/install/bin/ab
CLIENT_INPUT=-n 100 -c 5
The client time is always less than the send time, just like this:

3) And when I do this setting:
SERVER_COUNT=1
CLIENT_COUNT=1
CLIENT_PROGRAM=$MSMR_ROOT/apps/apache/install/bin/ab
CLIENT_INPUT=-n 100 -c 10
The client time is unpredictable, sometimes like this:

but sometimes is this:

So I think "closing each socket connection" is not the root cause of the performance issue. When I increase the concurrency, all kinds of times has increased, and only when the number of concurrency comes to some value(such as the -c 10 in above test), the client time becomes unpredictable. I think only reduce the client time is not enough, because the send time and the connect time are also large when the number of concurrency becomes large.
So I think the root cause should be related to concurrency
B) Why do close operation spend so much time in n500c10 ?





Only the last one shows the good performance.
C) Serialization in Consensus
First, let's see the following data which generated by apache_ab.cfg server_count=3, client_count=1, ab -n800 -c1
Concensus Time====Overall(4795):
mean:693.13894596 us
std:167.788062686
Concensus Time====from proxy to consensus(4795): (A)
mean:218.529795705 us
std:111.518391506
Concensus Time====ACCEPT_REQ from leader to node_1(4795): (B)
mean:137.031911188 us
std:49.7794872016
Concensus Time====ACCEPT_ACK from node_1 to leader(4795): (C)
mean:326.110473887 us
std:62.0525281375
B represents the best performance when data is sent from a port to another port by bufferevent: 137us.
Then, apache_ab.cfg server_count=3, client_count=1, ab -n800 -c3
Concensus Time====Overall(4875):
mean:832.699359992 us
std:462.180223423
Concensus Time====from proxy to consensus(4875):(A')
mean:280.891858614 us
std:343.641828574
Concensus Time====ACCEPT_REQ from leader to node_1(4875):(B')
mean:183.160488422 us
std:96.299732673
Concensus Time====ACCEPT_ACK from node_1 to leader(4875): (C')
mean:358.694761227 us
std:186.921091169
B' also should represent the best performance when data is sent from a port to another port by bufferevent: 183us.
While, on bug02 (Columbia machine), the same setting apache_ab.cfg server_count=3, client_count=1, ab -n800 -c3
Concensus Time====Overall(4763):
mean:1182.11145139 us
std:346.426714509
Concensus Time====from proxy to consensus(4763):(A')
mean:367.019698571 us
std:243.390116677
Concensus Time====ACCEPT_REQ from leader to node_1(4763):(B')
mean:274.938969409 us
std:102.669241168
Concensus Time====ACCEPT_ACK from node_1 to leader(4763):(C')
mean:528.355343563 us
std:159.393544771
when concurrency is 1:
Concensus Time====Overall(4798):
mean:695.450646821 us
std:161.193978342
Concensus Time====from proxy to consensus(4798):(A)
mean:222.806833147 us
std:94.8671650196
Concensus Time====ACCEPT_REQ from leader to node_1(4798):(B)
mean:136.120461483 us
std:52.0170946117
Concensus Time====ACCEPT_ACK from node_1 to leader(4798):(C)
mean:325.121647023 us
std:60.4248984616
B' is a little high. But I think its level of anomaly should not bring us restlessness.
Either my PC(RMB <4000) or bug02(24-core) have the similar performance, showing the same best performance when data is sent from a port to another port by bufferevent: about 130us. The reason why I regard it as the best performance is that one don't need to wait for the over of the former in the process. But with the concurrency increasing, there will also be waiting (or congestion) coming out. So both machines show that the part time also increases with the concurrency increasing.
The interpretation also applies to other part time, especially Part C and Part C'.
In part C or C', a.k.a, ACCEPT_ACK from node_1 to leader. There is only one input evbuffer receiving all kinds of data: REQUEST_SUBMIT(Part A and A'), ACCEPT_ACK. And the leader may receives the ACK from other replicas at the same time which will aggravates the congestion in the only input buffer shared by two kinds of data.
D) Serialization in Proxy
When proxy receives the signal from consensus, it will finish doing the real action quickly, within about 80us on my PC and 160us on bug02. If many guys kill the signal almost simultaneously, then the last one will be handled at last, so maybe its time usage is about 240us (on PC, concurrency 3) or 480us on bug02.
On PC | concurrency 3
Response Time====from the end of consensus time to wake up including lock(5220):
mean:88.9552507364 us
std:153.436981763
Response Time====from wake up to Cheng end time(5220):
mean:12.87976444 us
std:60.5492724851
On bug02 | concurrency 3
Response Time====from the end of consensus time to wake up including lock(4740):
mean:314.900442518 us
std:419.220028888
Response Time====from wake up to Cheng end time(4740):
mean:21.7045912763 us
std:51.4035536109
The data can verify our thinking in some level.
Similar with consensus time part, I also suggest that 80us on my PC and 160us on bug02 represent the best performance (which tested under concurrency is 1).
On more thing, the process about signal sending, receiving and calling the func only cost several microseconds, about 2us.
update to Beijing Time 2015/02/02
Part V Generated on December 30, 2014 (Skills)
- To help us analyze the source code, let's remember several important arguments.
comp->deliver_mode = 0 <=>proxy->fake = 0
view_stamp_comp(op1, op2)
if op1 > op2 return 1
if op1 < op2 return -1
if op1 = op2 return 0
comp->ucb <=> update_state
my_node->msg_cb <=> handle_msg
cur_node->my_address <=> my_node->my_address
my_address is the corresponding consensus address of the node (i.e. if the node is node 0, then my_address is the IP address of consensus 0)
- Use skills to read source code, here is my own created marks which help me read the codes clearly and efficiently.


update to Beijing Time 2015/02/01
REFERENCE
分布式系统文档
http://dsdoc.net/
阿里中间件团队博客
http://jm-blog.aliapp.com/?tag=paxos
- PAXOS: libevent_paxos
- paxos
- Paxos
- paxos
- paxos
- paxos之Multi-Paxos
- Paxos算法
- Paxos算法
- Paxos算法
- paxos 实现
- Paxos小议
- Fast Paxos
- paxos 实现
- paxos算法
- Paxos算法
- Paxos算法
- Fast Paxos
- paxos 实现
- git 学习教程
- CCCamera
- 我的 新站 SEO 之路
- 站长之家及google IP
- 不产生新变量交换两个变量的值
- PAXOS: libevent_paxos
- 策略模式总结
- hpp和cpp
- php连接数据库读取数据并输入到页面中的3种方法。
- Bug-iOS: Collection <__NSArrayM: 0x> was mutated while being enumerated.
- JavaScript中的函数hasOwnProperty()和isPrototypeOf()的一些理解
- UltraTree的使用(Infragistics.Win.UltraWinTree.UltraTree)
- 编辑 XSD 文件时错误提示 components from this namespace are not referenceable from schema document 解决方法
- 关于求余数的思考


