如何实现降维处理(R语言)
来源:互联网 发布:java嵌套异常 编辑:程序博客网 时间:2024/04/27 13:41
转载自:http://f.dataguru.cn/thread-303589-1-1.html
现实世界中数据一般都是复杂和高维的,比如描述一个人,有姓名、年龄、性别、受教育程度、收入、地址、电话等等几十种属性,如此多的属性对于数据分析是一个严重的挑战,除了极大增加建模的成本和模型的复杂度,往往也会导致过拟合问题,因此在实际处理过程中,一些降维的方法是必不可少,其中用的比较多的有主成分分析(PCA)、奇异值分解(SVD)、特征选择(Feature Select),本文将对PCA和SVD作简单的介绍,并力图通过案例加深对这两种降维方法的理解。
1 主成分分析PCA
1.1 R语言案例
在R语言中PCA对应函数是princomp,来自stats包。以美国的各州犯罪数据为对象进行分析,数据集USArrests在graphics包中。
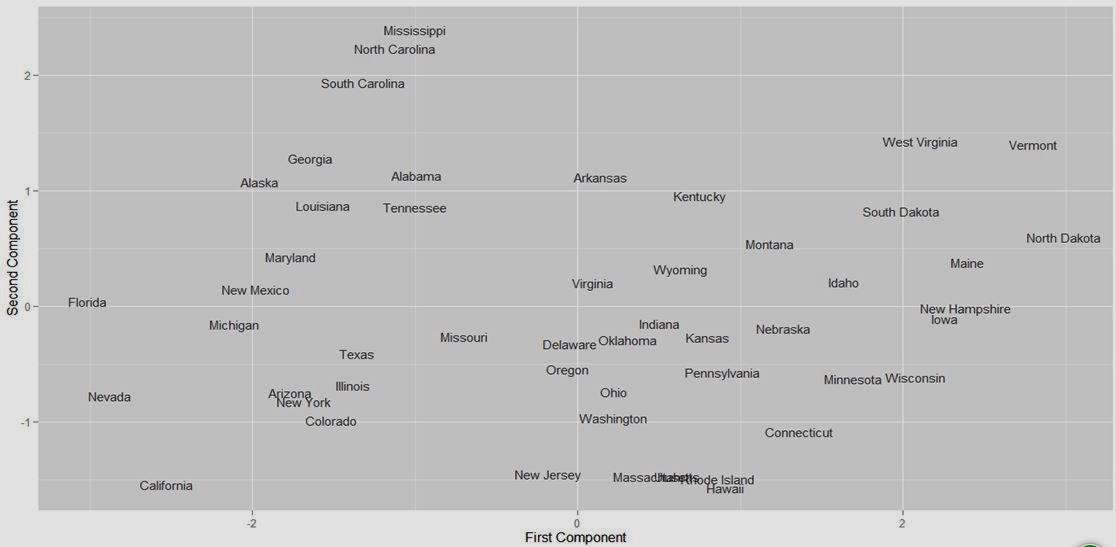
有兴趣的同学还可以,分析南北各州在犯罪数据上的迥异。
1.2 PCA理论基础
经过上一小节对PCA的简单应用,应该可以体会到PCA在降维处理上的魅力,下面简单介绍PCA的理论基础,对于更好的理解和应用PCA会非常有帮助。
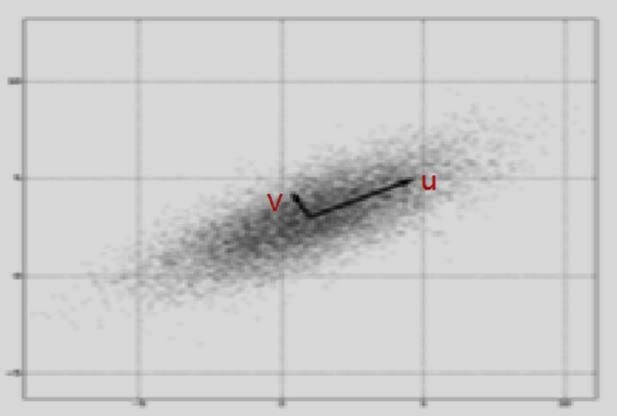
PCA本质就是将数据投影在众多正交向量上,根据投影后数据的方差大小,说明向量解释数据的程度,方差越大,解释的程度越大。以下图为例,数据投影在向量u的方差明显最大,因此u向量作为第一主成分,与u向量正交的v向量,作为第二主成分。
Nd = dim(data) 代表数据的维数, Sc = num(Comp)代表主成分的个数(Nd = Sc ),在实际情况中,往往取前k << Nd个主成分便能解释数据的方差程度超过90%,因此能够在只丢失少量消息的情况,达到大规模减少数据维度的效果,无论对于建立模型、提升性能、减少成本都有很大的意义。
从某种意义上讲,PCA只是将很多相互间存在线性关系的特征,转换成新的、相互独立的特征,从而减少特征数量。对此,它需要借助特征值来找到方差最大的主成分,每一个特征值对应一个特征向量,特征值越大,特征向量解释数据矩阵的方差的程度越高。因此,只需要将特征值从大到小排列,取出前k个特征向量,便能确定k个最重要的主成分。
PCA算法通常包括如下5个步骤:
A 平均值归一化,减去每个特征的平均值,保证归一化后的数据平均值为0
B 计算协方差矩阵,每两个特征之间的协方差
C 计算协方差矩阵的特征向量和特征值
D 将特征向量根据对应的特征值大小降序排列,特征向量按列组成FeatureVector = (eig_1, eig_2, …,eig_n)
E RowFeatureVector = t(FeatureVector) (转置),eig_1变为第一行,RowDataAdjusted = t(DataAdjusted), 特征行变为列,得到最终的数据。
FinalData = RowFeatureVector X RowDataAdjusted
从维度变化的角度出发
协方差矩阵:n x n , FeatureVector: n x n,RowFeatureVector:n x n, n为特征数量
DataAdjusted:m x n, RowDataAdjusted: n x m
取前k个特征向量, RowFeatureVector:k x n
那么FinalData: k x m, 这样便实现维度的降低。
2 奇异值分解(SVD)
2.1 案例研究
我们通过一张图片的处理来展示奇异值分解的魅力所在,对于图片的处理会用到R语言中raster和jpeg两个包。


取前五十个奇异值进行模拟,基本能还原成最初的模样,如上右图
当我们尝试用更多的奇异值模拟时,会发现效果越来来越好,这就是SVD的魅力,对于降低数据规模、提高运算效率、节省存储空间有着非常棒的效果。原本一张图片需要288 X 196的存储空间,经过SVD处理后,在保证图片质量的前提下,只需288 X 50 + 50 X 50 + 196 X 50的存储空间仅为原来的一半。
2.1 SVD理论基础
SVD算法通过发现重要维度的特征,帮助更好的理解数据,从而在数据处理过程中减少不必要的属性和特征,PCA(主成分分析)只是SVD的一个特例。PCA针对的正方矩阵(协方差矩阵),而SVD可用于任何矩阵的分解。
对于任意m x n矩阵A,都有这样一个等式
Am x n = Um x r Sr x r VTn x r
U的列称为左奇异向量,V的列称为右奇异向量,S是一个对角线矩阵,对角线上的值称为奇异值, r = min(n, m)。U的列对应AAT的特征向量,V的列则是ATA的特征向量,奇异值是AAT和ATA共有特征值的开方。由于A可能不是正方矩阵,因此无法利用得到特征值和特征向量,因此需要进行变换,即AAT(m x m)和ATA(n x n),这样就可以计算特征向量和特征值了。
A = USVT AT = VSUT
AAT = USVT VSUT = US2UT
AAT U = U S2
同样可以推导出: ATA V = V S2
总结下来,SVD算法主要有六步:
A 、计算出AAT
B 、计算出AAT的特征向量和特征值
C、计算出ATA
D 、计算出ATA的特征向量和特征值
E、计算ATA和ATA共有特征值的开方
F、计算出U、 S、 V
3 参考资料
[1] http://www.di.fc.ul.pt/~jpn/r/svd/svd.html
[2] http://www.puffinwarellc.com/index.php/news-and-articles/articles/30-singular-value-decomposition-tutorial.html
[3] http://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Dimensionality_Reduction
[4] http://en.wikipedia.org/wiki/Principal_component_analysis
转自:http://futureindata.blogspot.com/2014/02/r.html
0 0
- 如何实现降维处理(R语言)
- 如何利用R语言怎样处理百分数
- R语言处理字符串
- R语言图像处理
- R语言 并行处理
- 【R语言】字符串处理
- [R语言]字符串处理
- R语言时间处理
- R语言-图像处理
- R语言-字符串处理
- R语言时间处理
- 【R语言】问题处理
- R语言处理金农网爬取
- R语言处理QQ群消息案例实现
- 如何学习R语言?
- R语言实现聚类分析
- R语言实现神经网络
- R语言实现汉诺塔
- 一步一步学zedboard之一zedboard启动设置
- 圣诞节覅斯洛克
- 微软平台开发工具下载,包含key
- 实习周记(一)
- 啊上课看完了辛苦费睡觉啊
- 如何实现降维处理(R语言)
- 摘取自cocoaChina问答 ----退至指定的模态控制器解决方案
- 如何判断android的activity是否运行
- 识破欺骗教你一招快速搞定黑客老巢
- 因式分解
- 空间数据挖掘常用方法及举例
- “开源代码”亦享著作权保护
- Matlab中addpath的使用
- 软件工程导论学习-总体设计


