impala同步hive数据
来源:互联网 发布:结构体包含数组memset 编辑:程序博客网 时间:2024/05/17 03:30
参考链接
Impala与HBase整合实践
我们知道,HBase是一个基于列的NoSQL数据库,它可以实现的数据的灵活存储。它本身是一个大表,在一些应用中,通过设计RowKey,可以实现对海量数据的快速存储和访问。但是,对于复杂的查询统计类需求,如果直接基于HBase API来实现,性能非常差,或者,可以通过实现MapReduce程序来进行查询分析,这也继承了MapReduce所具备的延迟性。
实现Impala与HBase整合,我们能够获得的好处有如下几个:
- 可以使用我们熟悉的SQL,像操作传统关系型数据库一样,很容易给出复杂查询、统计分析的SQL设计
- Impala查询统计分析,比原生的MapReduce以及Hive的执行速度快很多
Impala与HBase整合,需要将HBase的RowKey和列映射到Impala的Table字段中。Impala使用Hive的Metastore来存储元数据信息,与Hive类似,在于HBase进行整合时,也是通过外部表(EXTERNAL)的方式来实现。
准备工作
首先,我们需要做如下准备工作:
- 安装配置Hadoop集群(http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Installation-Guide/cdh4ig_topic_4_4.html)
- 安装配置HBase集群(http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Installation-Guide/cdh4ig_topic_20.html)
- 安装配置Hive(http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Installation-Guide/cdh4ig_topic_18.html)
- 安装配置Impala(http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/ciiu_noncm_installation.html?scroll=noncm_installation)
涉及到相关系统的安装配置,可以参考相关文档和资料。
下面,我们通过一个示例表test_info来说明,Impala与HBase整合的步骤:
整合过程
- 在HBase中创建表
首先,我们使用HBase Shell创建一个表,如下所示:
1create 'test_info', 'info'表名为test_info,只有一个名称为info的列簇(Column Family),我们计划该列簇中存在4个列,分别为info:user_id、info:user_type、info:gender、info:birthday。
- 在Hive中创建外部表
创建外部表,对应的DDL如下所示:
1CREATE EXTERNAL TABLE sho.test_info(2 user_id string,3 user_type tinyint,4 gender string,5 birthday string)6ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'7STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'8WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, info:user_type, info:gender, info:birthday")9TBLPROPERTIES("hbase.table.name" = "test_info");上面DDL语句中,在WITH SERDEPROPERTIES选项中指定Hive外部表字段到HBase列的映射,其中“:key”对应于HBase中的RowKey,名称为“user_id”,其余的就是列簇info中的列名。最后在TBLPROPERTIES中指定了HBase中要进行映射的表名。
- 在Impala中同步元数据
Impala共享Hive的Metastore,这时需要同步元数据,可以通过在Impala Shell中执行同步命令:
1INVALIDATE METADATA;然后,就可以查看到映射HBase中表的结构:
1DESC test_info;表结构如图所示: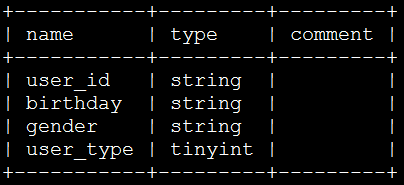
通过上面三步,我们就完成了Impala和HBase的整合配置。
验证整合
下面,我们通过实践来验证上述的配置是否生效。
我们模拟客户端插入数据到HBase表中,可以使用HBase API或者HBase Thrift来实现,这里我们使用了HBase Thrift接口来进行操作,详见文章 HBase Thrift客户端Java API实践。
然后,我们就可以通过Impala Shell进行查询分析。基于上面创建整合的示例表,插入20000000(2000万)记录,我们做一个统计分析的示例,SQL语句如下所示:
1SELECT user_type, COUNT(user_id) AS cnt FROM test_info WHERE gender='M' GROUP BY user_type ORDER BYcnt DESC LIMIT 10;运行结果信息,如下图所示: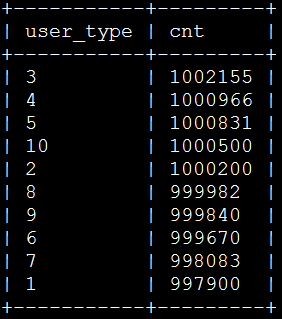
上述程序运行所在Hadoop集群共有3个Datanode,执行上述统计SQL共用时88.13s。我的Hadoop集群配置比较低,2个节点是双核CPU,另一个是4核,内存足够,大概10G左右,而且还有好多程序在共享这些节点,如数据库服务器、SOLR集群等。如果提高配置,做一些优化,针对20000000(2000万)条记录做统计分析,应该可以在5s以内出来结果。
由于测试数据是我们随机生成的,gender取值为’M’和’F’,user_type的值为1到10,经过统计分组后,数据分布还算均匀。
参考链接
- http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/ciiu_impala_hbase.html
- http://shiyanjun.cn/archives/111.html
- impala同步hive数据
- impala两种方式同步hive元数据
- hadoop生态系统学习之路(八)hbase与hive的数据同步以及hive与impala的数据同步
- impala操作hive数据实例
- impala 刷新同步hive表命令
- 大数据提速:Impala能否取代Hive
- 大数据提速:Impala能否取代Hive
- 使用impala/hive查询hbase数据
- hive和impala查询数据对比
- Impala实践之二:Hive元数据
- 数据分析:Hive、Pig和Impala
- impala如何出现hive表的数据
- impala刷新hive数据shell脚本
- 将hbase中的表同步到hive和impala中
- Hive 同步数据
- Parquet_2. 在 Impala/Hive 中使用 Parquet 格式存储数据
- Hive和Impala加载和存储数据功能曝光
- 在Impala 和Hive里进行数据分区(1)
- iOS开发之单例
- 以hdu3480为例学会斜率优化&&四边形优化
- CoAP协议学习——CoAP基础
- 【项目管理和构建】——Maven简介(一)
- 为什么很多的 iOS app 都有秒退现象?有什么好方法避免它?
- impala同步hive数据
- ubuntu下 截图工具
- uvaoj 10192 - Vacation 最长公共子序列(LCS)
- IT忍者神龟之有关struts.xml中用到chain和redirectAction编译报错Undefined actionnamespace parameter
- socket通信简介
- java 单例模式(双重检查锁)
- 关于两个Activity之间切换的情况
- C# DateTime 转文本,例如:1年前,3个月前,3周前,6天前,15小时前,35分钟前
- GlusterFS数据恢复机制AFR


