ICCV 2013 Results (29 Aug, 2013)
Papers submitted: 1629
Withdrawals and administrative rejections: 128
Accepted as Orals: 41 (2.52% oral acceptance rate)
Accepted as Posters: 413 (27.87% total acceptance rate)
Basic Review Statistics
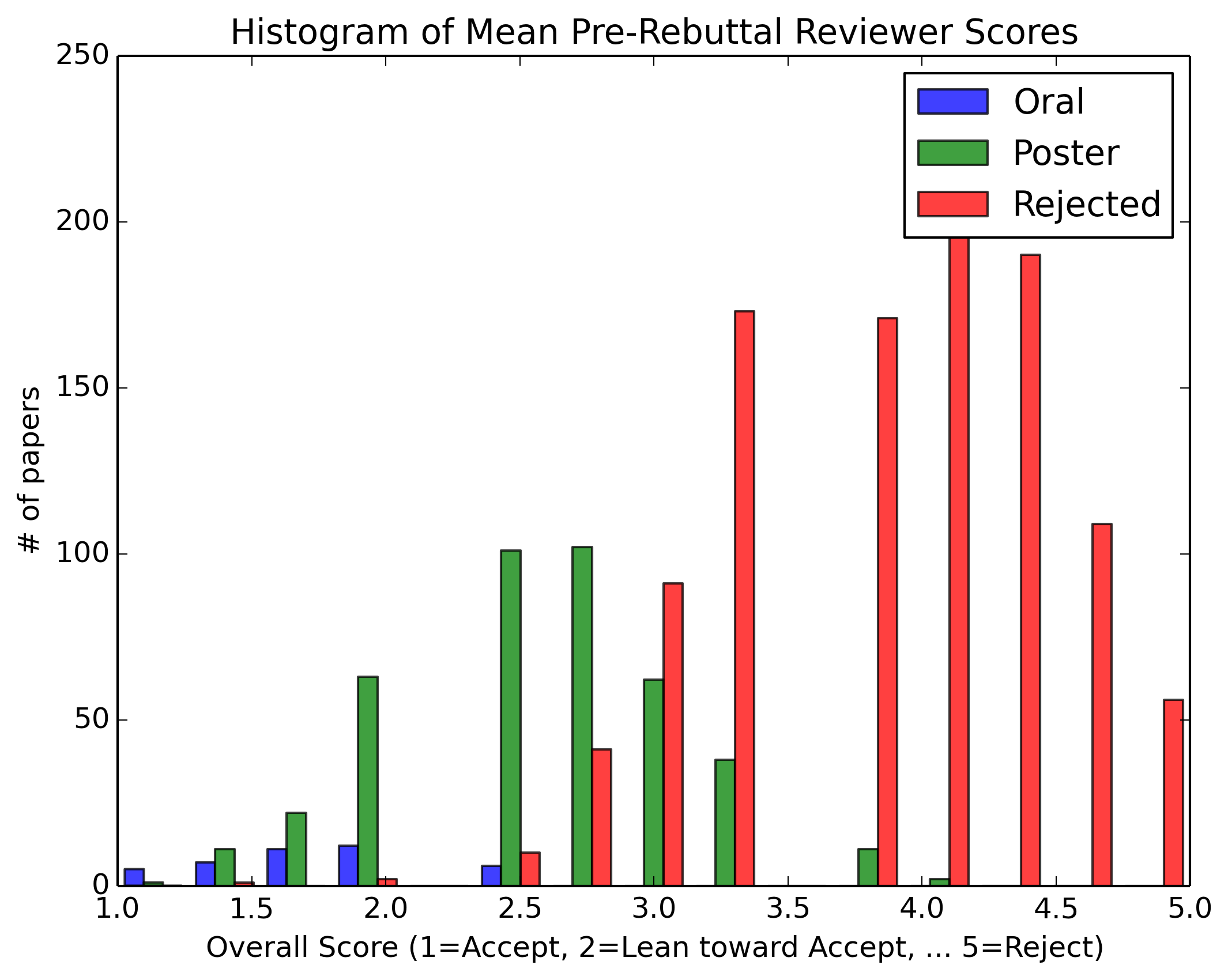
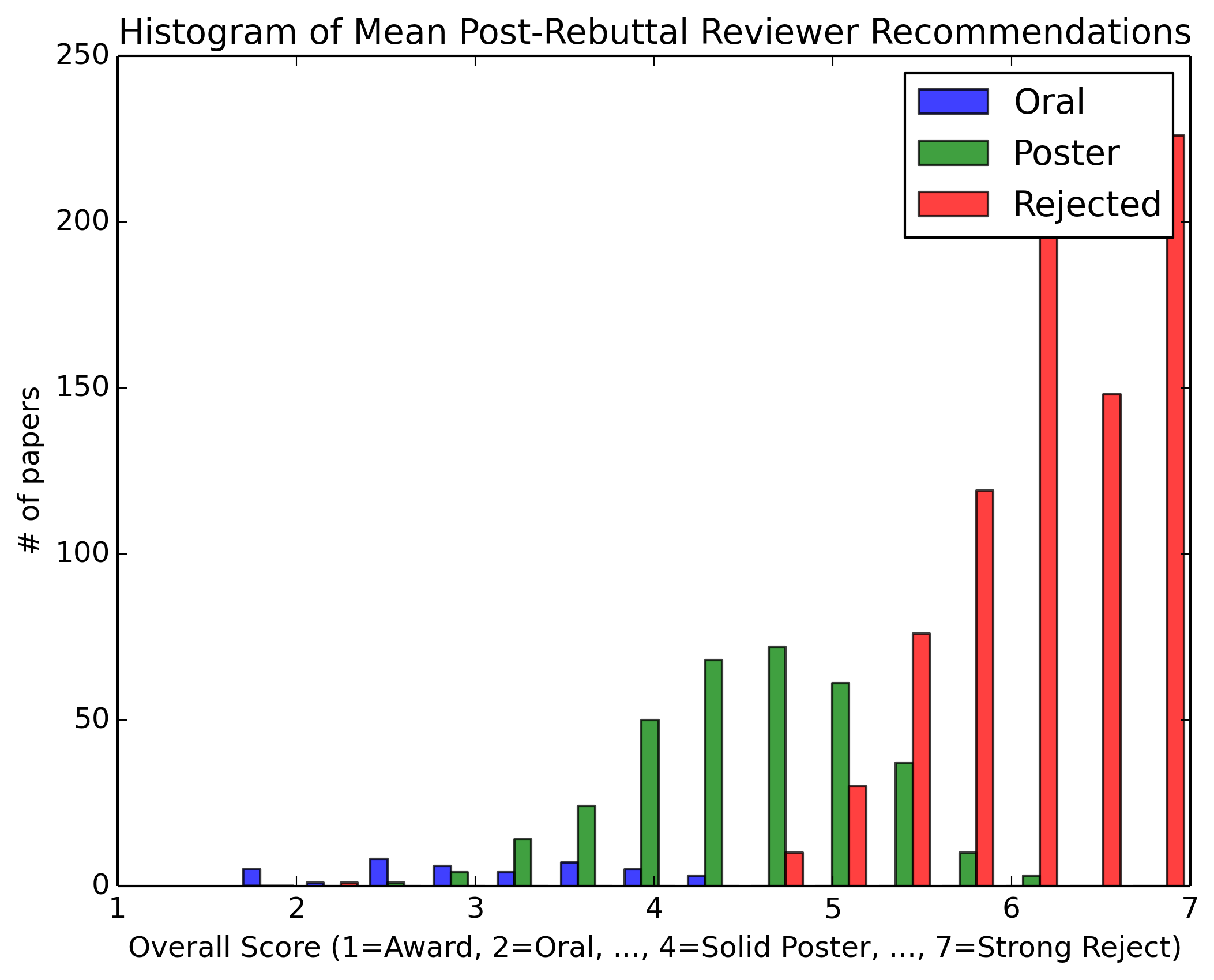
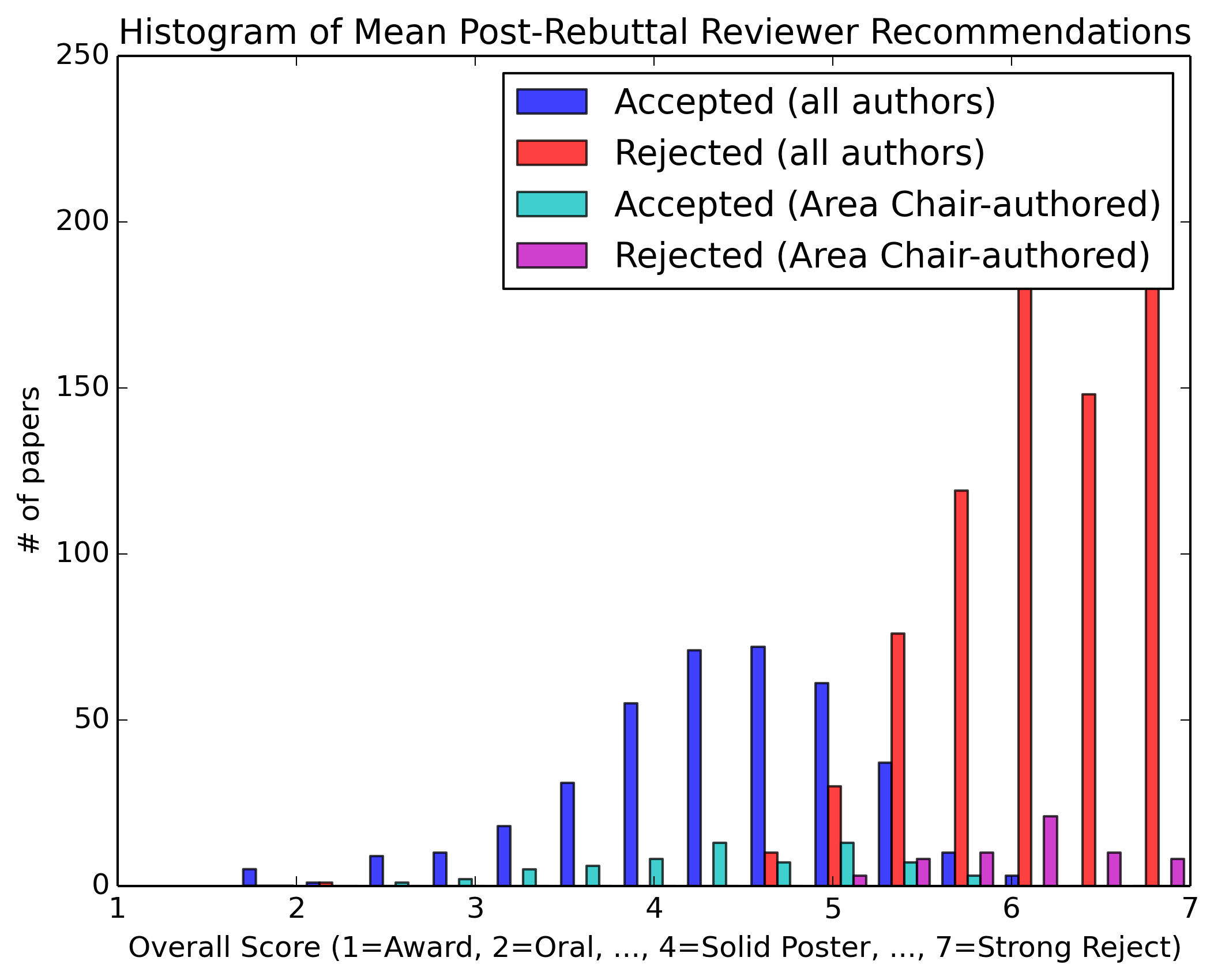
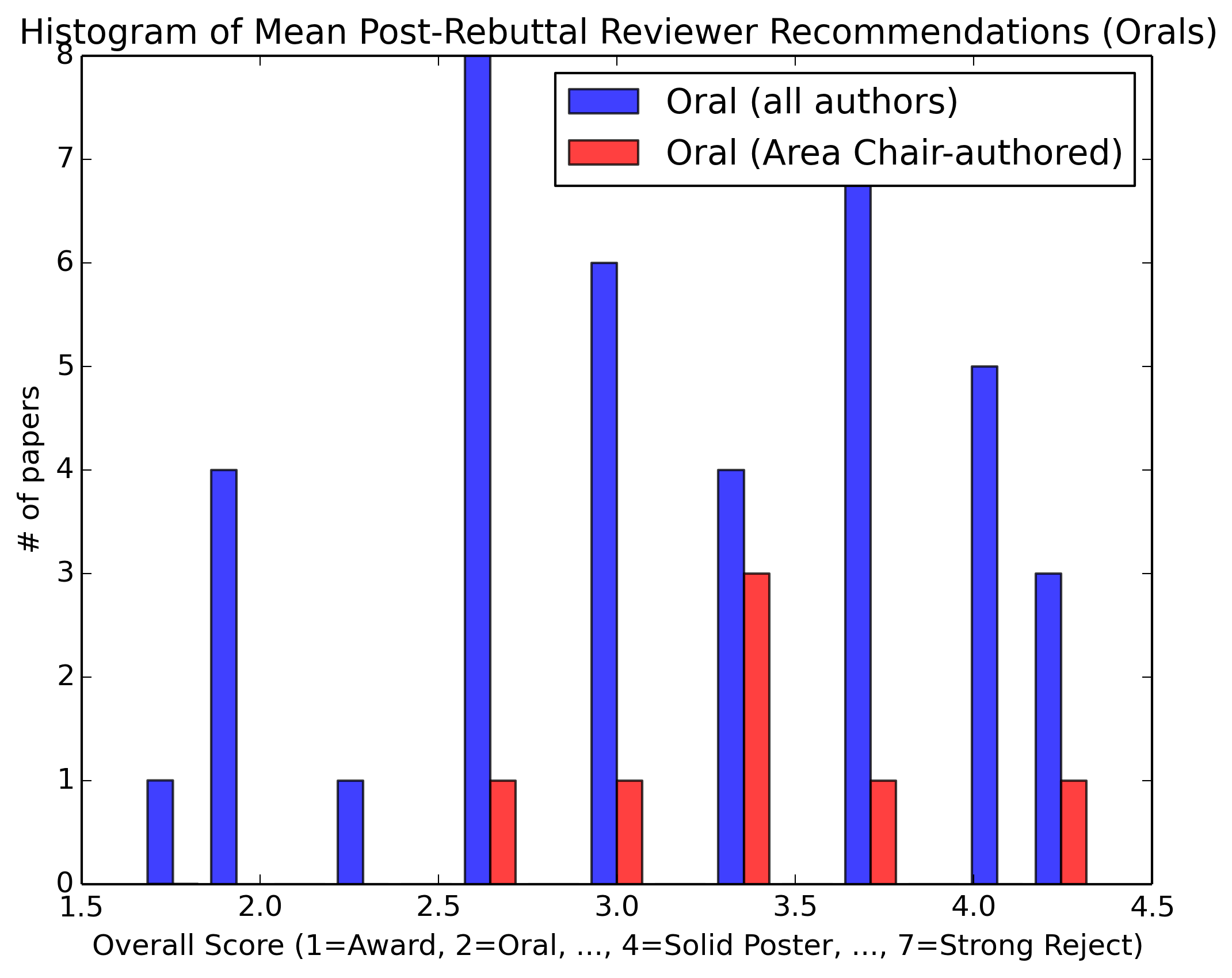
In the interest of transparency, we present aggregate review statistics for oral, poster and rejected papers. We also compare the statistics for papers authored by Area Chairs vs. the complete author population.
Acceptances per Primary Subject Area
| # Papers Submitted | # Papers Accepted | Acceptance rate | Primary Subject Area | | | | Recognition: detection, categorization, classification, indexing, matching | 44413831.0810813D computer vision | 1534126.797386Motion and tracking | 1483825.675676Video: events, activities & surveillance | 1464228.767123Face and gesture | 1434027.972028Low-level vision and image processing | 1322821.212121Segmentation, grouping and shape representation | 1223125.409836Statistical methods and learning | 912224.175824Computational photography, sensing and display | 872326.436782Optimization methods | 632438.095238Physics-based vision and Shape-from-X | 29931.034483Medical and biological image analysis | 25416.000000Performance evaluation | 14428.571429Vision for the web | 11218.181818Vision for graphics | 9555.555556Document analysis | 6350.000000Robotics | 600.000000Orals
| | Title | Authors | Primary Subject Area | | | | 3D computer vision | 39 | Elastic Fragments for Dense Scene ReconstructionQian-Yi Zhou*, Stanford University; Stephen Miller, Stanford University; Vladlen Koltun, Stanford University702 | A Global Linear Method for Camera Pose RegistrationNianjuan Jiang*, ADSC; Zhaopeng Cui, NUS; Ping Tan,748 | A Rotational Stereo Model Based On XSlit ImagingJinwei Ye*, University of Delaware; Yu Ji, University of Delaware; Jingyi Yu, University of Delaware1177 | Lifting 3D Manhattan Lines from a Single ImageSrikumar Ramalingam*, MERL; Matthew Brand, MERL1588 | Rolling Shutter StereoOlivier Saurer*, ETH Zurich; Kevin Koeser, ; Jean-Yves Bouguet, Google ; Marc Pollefeys, ETHComputational photography, sensing and display | 845 | Nonparametric Blind Super-ResolutionTomer Michaeli*, Weizmann Institute of Science; Michal Irani, Weizmann Institute, Israel1696 | Scene Intensity and Depth Acquisition from One Detected Photon per PixelAhmed Kirmani*, MIT; Dongeek Shin, MIT; Dheera Venkatraman, MIT; Franco Wong, MIT; Vivek Goyal, MITFace and gesture | 1680 | A Practical Transfer Learning Algorithm for Face VerificationXudong Cao*, Microsoft Research Asia; David Wipf,Low-level vision and image processing | 178 | Benchmarking Computational Model of Visual SaliencyAli Borji*, ; Dicky Sihite, University of Southern California (USC); Hamed Rezazadegan Tavakoli, University of Oulu; Laurent Itti, University of Southern California (USC)389 | A Color Constancy Model with Double-Opponency MechanismsShaobing Gao, UESTC; Kaifu Yang, UESTC; Yongjie Li*, UESTC436 | Estimating Human Scanpath Using Hidden Markov ModelHuiying Liu*, Institute of Computing Technol; Dong Xu, "NTU, Singapore"; Qingming Huang, Graduate Univ of Chinese Academy of Sciences; Wen LI, NTU; Stephen Lin, Microsoft Research Asia547 | Structured Forests for Fast Edge DetectionPiotr Dollar*, ; Larry Zitnick, "Microsoft Research, USA"Motion and tracking | 307 | Hierarchical Data-driven Descent for Efficient Optimal Deformation EstimationYuandong Tian*, Carnegie Mellon University; Srinivas Narasimhan, Carnegie Mellon University319 | Perspective Motion Segmentation via Collaborative ClusteringZhuwen Li*, NUS; Jiaming Guo, NUS; Loong-Fah Cheong, NUS; Zhiying Zhou, NUS1036 | Piecewise Rigid Scene FlowChristoph Vogel*, ETH Zurich; Konrad Schindler, ETH Zurich; Stefan Roth, "TU Darmstadt, Germany"1095 | Large displacement optical flow with deep matchingPhilippe Weinzaepfel*, INRIA; Jerome Revaud, ; Zaid Harchaoui, INRIA; Cordelia Schmid, "INRIA, France"1530 | Orderless Tracking through Model-Averaged Density EstimationSeunghoon Hong*, POSTECH; Suha Kwak, POSTECH; Bohyung Han, POSTECH1911 | The Way They Move: Tracking Multiple Targets with Similar AppearanceCaglayan Dicle, neu.edu; Octavia Camps*, ; Mario Sznaier, Northeastern UniversityOptimization methods | 68 | Active MAP Inference in CRFs for Efficient Semantic SegmentationGemma Roig, ETH; Xavier Boix*, ETH; Roderick De Nijs, TUM; Sebastian Ramos, Computer Vision Center (CVC); Luc Van Gool, ETH1031 | Potts model, parametric maxflow and k-submodular functionsIgor Gridchyn, IST Austria; Vladimir Kolmogorov*, "IST, Austria"1739 | Proportion Priors for Image Sequence SegmentationClaudia Nieuwenhuis*, ; Evgeny Strekalovskiy, TU Munich; Daniel Cremers, Technische Universitt Mnchen1900 | Coarse-to-fine Semantic Video Segmentation using Supervoxel TreesRene Vidal*, Johns Hopkins University; Aastha Jain, LinkedinPerformance evaluation | 1055 | Finding the Best from the Second Bests -- Inhibiting Subjective Bias in Evaluation of Visual Tracking AlgorithmsYU PANG*, Temple univeristy; Haibin Ling,Physics-based vision and Shape-from-X | 523 | Towards Guaranteed Illumination Models for Non-Convex ObjectsYuqian Zhang*, Columbia University; Cun Mu, Columbia University; Han-wen Kuo, Columbia University; John Wright,740 | Separating Reflective and Fluorescent Components using High Frequency Illumination in the Spectral DomainYing Fu*, The University of Tokyo; Antony Lam, National Institute of Informatics; Imari Sato, ; Takahiro Okabe, ; Yoichi Sato, The University of Tokyo, Japan"Recognition: detection, categorization, classification, indexing, matching | 52 | HOGgles: Visualizing Object Detection FeaturesCarl Vondrick*, MIT; Aditya Khosla, ; Tomasz Malisiewicz, ; Antonio Torralba, MIT81 | Regionlets for Generic Object DetectionXiaoyu Wang*, NEC Labs America; Ming Yang, NEC Labs America; Shenghuo Zhu, ; Yuanqing Lin,189 | How Do You Tell a Blackbird from a Crow?Thomas Berg*, Columbia University; Peter Belhumeur, "Columbia University, USA"454 | Learning to predict gaze in egocentric videoYin Li*, Georgia Institute of Technolog; Alireza Fathi, Georgia Institute of Technology; James Rehg, Georgia Institute of Technology569 | From Large Scale Image Categorization to Entry-Level CategoriesVicente Ordonez*, Stony Brook University; Jia Deng, Stanford University; Yejin Choi, Stony Brook University; Alexander Berg, Stony Brook University; Tamara Berg, "Stony Brook University, USA"738 | Style-aware Mid-level Representation for Discovering Visual Connections in Space and TimeYong Jae Lee*, Robotics Institute, Carnegie Mellon University; Alexei (Alyosha) Efros, CMU; Martial Hebert, "CMU, USA"884 | Shufflets: shiftable shared parts for multi-category detectionIasonas Kokkinos*, "Ecole Centrale Paris, France"965 | To aggregate or not to aggregate: Selective match kernels for image searchGiorgos Tolias, ; Yannis Avrithis, NTUA; Herv Jgou*, INRIA1173 | NEIL: Extracting Visual Knowledge from Web DataXinlei Chen, CMU; Abhinav Shrivastava, Carnegie Mellon University; Abhinav Gupta*,1546 | Learning Graphs to MatchMinsu Cho*, ; Karteek Alahari, ENS-Willow; Jean Ponce, "ENS, France"1649 | Beyond Hard Negative Mining: Efficient Detector Learning via Block-Circulant DecompositionJoo Henriques, Institute of Systems and Robotics - University of Coimbra; Rui Caseiro*, Institute of Systems and Robotics - University of Coimbra; Joao Carreira, University of Coimbra; Jorge Batista, ISR1685 | Real-time Articulated Hand Pose Estimation using Semi-supervised Transductive Regression ForestsDanhang Tang*, Imperial College London1788 | Holistic Scene Understanding for 3D Object Detection with RGBD camerasDahua Lin*, TTIC; Sanja Fidler, TTI Chicago ; Raquel Urtasun, Toyota Technological Institute at Chicago1965 | Fast Subspace Search via Grassmannian Based HashingXu Wang*, University of Minnesota; Stefan Atev, ; John Wright, ; Gilad Lerman, University of MinnesotaSegmentation, grouping and shape representation | 1151 | Tree Shape Priors with Connectivity Constraints using Convex Relaxation on General GraphsJan Sthmer*, TU Munich; Peter Schrder, Caltech; Daniel Cremers, Technische Universitt Mnchen1500 | Weakly supervised learning of image partitioning using decision trees with structured split criteriaChristoph Straehle*, HCI, University of Heidelberg; Ullrich Koethe, ; Fred Hamprecht, HCI, University of HeidelbergPosters
| | Title | Authors | Primary Subject Area | | | | 3D computer vision | 79 | Shape Anchors for Data-driven Multi-view ReconstructionAndrew Owens, MIT; Jianxiong Xiao*, MIT; Antonio Torralba, MIT; Bill Freeman, "MIT, USA"198 | Dynamic Probabilistic Volumetric ModelsAli Ulusoy*, Brown University; Joseph Mundy, Brown University309 | Street View Structure-from-MotionBryan Klingner*, Google; David Martin, Google; James Roseborough, Google396 | 3D Scene Understanding by Voxel-CRFByung-soo Kim*, ; Pushmeet Kohli, "Microsoft Research, UK"; Silvio Savarese, "University of Michigan, USA"400 | 3DNN: Viewpoint Invariant 3D Geometry Matching for Scene UnderstandingScott Satkin*, Carnegie Mellon University; Martial Hebert, "CMU, USA"418 | Revisiting the P\(n\)P Problem: A Fast, General and Optimal SolutionYinqiang Zheng*, Tokyo Institute of Technology; Yubin Kuang, Lund University; shigeki Sugimoto, Tokyo Institute of Technology; Kalle Astrom, Lund University ; Masatoshi Okutomi, Tokyo Institute of Technology462 | Line Assisted Light Field Triangulation and Stereo MatchingZhan Yu*, University of Delaware; Xinqing Guo, University of Delaware; Jingyi Yu, University of Delaware473 | Enhanced Continuous Tabu Search for Parameter Estimation in Multiview GeometryGuoqing Zhou, Northwestern Polytechnical University; Qing Wang*, Northwestern Polytechnical Uni509 | Deterministic Fitting of Multiple Structures using Iterative MaxFS with Inlier Scale EstimationKwang Hee Lee*, Sogang University; Sang Lee, "Sogang University, Korea"535 | Network Principles for SfM: Disambiguating Repeated Structures with Local ContextKyle Wilson*, Cornell University; Noah Snavely, "Cornell, USA"541 | A Robust Analytical Solution to Isometric Non-Rigid Pose with Focal Length CalibrationAdrien Bartoli*, Universit?d'Auvergne; Daniel Pizarro, ALCoV-ISIT; Toby Collins, ALCoV-ISIT582 | Complex 3D General Object Reconstruction from Line DrawingsLinjie Yang*, CUHK; Jianzhuang Liu, CUHK; Xiaoou Tang, Chinese University of Hong Kong668 | Local Signal Equalization for Correspondence MatchingDerek Bradley*, Disney Research Zurich; Thabo Beeler, Disney Research Zurich682 | Direct Optimization of Frame-to-Frame RotationLaurent Kneip*, ETH Zurich; Simon Lynen, ETH Zurich813 | A Flexible Scene Representation for 3D Reconstruction Using RGB-D CameraDiego Thomas*, National Institute of Informat; Akihiro Sugimoto,889 | Global Fusion of Relative Motions for Robust, Accurate and Scalable Structure from Motion.Pierre Moulon*, Imagine; Pascal Monasse, ; Renaud Marlet,897 | Constant Time Weighted Median Filtering for Stereo Matching and BeyondZiyang Ma*, Institute of Software, CAS; Kaiming He, Mirosoft Research Asia; Yichen Wei, ; Jian Sun, "Microsoft Research, China"; Enhua Wu, Faculty of Science and Technology, University of Macau902 | Efficient and Robust Large-Scale Rotation AveragingAvishek Chatterjee, Indian Institute of Science; Venu Madhav Govindu*, Indian Institute of Science905 | Point-Based 3D Reconstruction of Thin ObjectsBenjamin Ummenhofer*, University of Freiburg; Thomas Brox,934 | Subpixel scanning invariant to indirect lighting using quadratic code lengthNicolas Martin*, ; Vincent Couture, ; Sebastien Roy,975 | Monocular Image 3D Human Pose Estimation under Self-OcclusionIbrahim Radwan*, University of Canberra; Abhinav Dhall, Australian National University; Roland Goecke,1121 | PM-Huber: PatchMatch with Huber Regularization for Stereo MatchingPhilipp Heise*, TU Mnchen; Sebastian Klose, TU Mnchen; Brian Jensen, TU Mnchen; Alois Knoll, TU Mnchen1158 | Image Aided Automatic Registration of Laser Scans via Salient DirectionsBernhard Zeisl*, ETH; Kevin Koeser, ; Marc Pollefeys, ETH1241 | Internet-based morphable modelIra Kemelmacher*, University of Washington1348 | Refractive Structure-from-Motion on Underwater ImagesAnne Jordt-Sedlazeck*, Kiel University; Reinhard Koch, Christian-Albrechts-Universitat Kiel1394 | Pose Estimation with Unknown Focal Length using Points, Directions and LinesYubin Kuang*, Lund University; Kalle Astrom, Lund University1535 | Space-Time Tradeoffs in Photo SequencingTali Basha Dekel*, TAU; Shai Avidan, Tel-Aviv University; Yael Moses,1567 | Real-Time Semi-Dense Monocular SLAM: A Statistical ApproachJakob Engel*, Technical University Munich; Juergen Sturm, TU Munich; Daniel Cremers, Technische Universitt Mnchen1584 | Multi-View 3D Reconstruction from Uncalibrated Radially-Symmetric CamerasJae-Hak Kim*, ANU; Yuchao Dai, Australian National University; Du Xin, ; Hongdong Li, Australia National University; Jonghyuk Kim, ANU1632 | Extrinsic Camera Calibration Without A Direct View Using Spherical MirrorAmit Agrawal*, MERL1657 | Real-time solution to the absolute pose problem with unknown radial distortion and focal lengthZuzana Kukelova*, ; Martin Bujnak, Bzovicka 24, 85107, Bratislava, Slovakia; Tomas Pajdla, Czech Technical University1688 | Large-Scale Multi-Resolution Surface Reconstruction from RGB-D SequencesFrank Steinbrcker*, Technical University of Munich; Christian Kerl, in.tum.de; Juergen Sturm, TU Munich; Daniel Cremers, in.tum.de1725 | Live Metric 3D Reconstruction on Mobile PhonesPetri Tanskanen, ETH Zurich; Kalin Kolev*, ETH Zurich; Lorenz Meier, ETH Zurich; Federico Camposeco Paulsen, ETH Zurich; Olivier Saurer, ETH Zurich; Marc Pollefeys, ETH1729 | Unsupervised intrinsic calibration from a single frame using a "plumb-line" approachRui Melo*, ISR-Coimbra; Michel Antunes, ; Joao Barreto, ; Gabriel Falco, ; Nuno Gonalves,1800 | An Enhanced Structure-from-Motion Paradigm based on the Absolute Dual Quadric and Images of Circular PointsLilian Calvet*, University of Toulouse; Pierre Gurdjos, IRIT1859 | Globally-Optimal ICP : Solving the 3D Registration Problem Efficiently and Globally OptimallyJiaolong Yang, Beijing Inst. of Tech.; Hongdong Li*, Australia National University; Yunde Jia,Computational photography, sensing and display | 54 | Joint Subspace Stabilization for Stereoscopic VideoFeng Liu*, Portland State University; Yuzhen Niu, ; Hailin Jin,100 | Structured Light in SunlightQi Yin*, Columbia University; Mohit Gupta, ; Shree Nayar, Columbia University122 | Image Guided Depth Upsampling using Anisotropic Total Generalized VariationDavid Ferstl*, Graz University of Technology; Christian Reinbacher, ; Matthias Rther, ; Horst Bischof, Graz University of Technology239 | Forward Motion DeblurringShicheng Zheng*, CUHK; Li Xu, CUHK; Jiaya Jia, Chinese University of Hong Kong249 | Corrected-Moment Illuminant EstimationGraham Finlayson*, University of East Anglia375 | Robust non-parametric Correspondence FittingWen-Yan Lin*, Oxford Brookes; Ming Ming Chen, ; Kyle Zheng, ; Jiangbo Lu, Advanced Digital Sciences Cent; Crook Nigel,409 | Rectangling Stereographic Projection for Wide-Angle Image VisualizationChe-Han Chang*, National Taiwan University; Yung-Yu Chuang, National Taiwan University424 | Dynamic Scene DeblurringTae Hyun Kim, Seoul National Univ.; Byeongjoo Ahn, Seoul National University; Kyoung Mu Lee*, Seoul National University514 | Video Synopsis by Heterogeneous Multi-Source CorrelationXiatian Zhu*, Queen Mary, Univ. of London; Chen Change Loy, CUHK; Shaogang Gong, EECS, QMUL644 | Content-Aware RotationKaiming He*, Mirosoft Research Asia; Huiwen Chang, Tsinghua University; Jian Sun, "Microsoft Research, China"710 | Fluttering Pattern Generation using Modified Legendre Sequence for Coded Exposure ImagingHae-Gon Jeon, KAIST; Joon-Young Lee, KAIST; Yudeog Han, KAIST; Seon Joo Kim, Yonsei University; Inso Kweon*, "KAIST, Korea"714 | Fibonacci Exposure Bracketing for High Dynamic Range ImagingMohit Gupta*, ; Daisuke Iso, Columbia University; Shree Nayar, Columbia University741 | Target-Driven Moire Pattern Synthesis by Phase ModulationPei-Hen Tsai, National Taiwan University; Yung-Yu Chuang*, National Taiwan University924 | Deblurring by Example using Dense CorrespondenceYoav HaCohen*, Hebrew University; Eli Shechtman, ; Dani Lischinski,935 | Accurate Blur Models vs. Image Priors in Super-ResolutionNetalee Efrat*, Weizmann institute; Daniel Glasner, Weizmann Institute; sasha Apartsin, weizmann institute; Boaz Nadler, weizmann institute; Anat Levin, Weizmann Institute, Israel1085 | Modeling the calibration pipeline of the Lytro camera and its application in high quality light-field image reconstructiondonghyeon Cho*, KAIST; Minhaeng Lee, KAIST; Sunyeong Kim, KAIST; Yu-Wing Tai, "KAIST, Korea"1298 | DCSH - Matching Patches in RGBD ImagesYaron Eshet, ; Simon Korman*, Tel-Aviv University; Eyal Ofek, Microsoft; Shai Avidan, Tel-Aviv University1360 | Fast Direct Super-Resolution by Simple FunctionsChih-Yuan Yang*, UC Merced; Ming-Hsuan Yang, "UC Merced, USA"1408 | Towards Motion-Aware Light Field Video for Dynamic ScenesSalil Tambe, Rice University; Ashok Veeraraghavan*, Rice University; Amit Agrawal, MERL1445 | Compensating for Motion During Direct-Global SeparationSupreeth Achar*, Carnegie Mellon University; Stephen Nuske, Carnegie Mellon University; Srinivas Narasimhan, Carnegie Mellon University1774 | Anchored Neighborhood Regression for Fast Example-Based Super-ResolutionRadu Timofte*, KU Leuven; Vincent De Smet, KU Leuven; Luc Van Gool, KU LeuvenDocument analysis | 150 | Scene Text Localization and Recognition with Oriented Stroke DetectionLukas Neumann*, ; Jiri Matas, Czech Technical University696 | Recognizing Text with Perspective Distortion in Natural ScenesTrung Quy Phan*, National University of Singapore; Palaiahnakote Shivakumara, University of Malaya; Shangxuan Tian, National University of Singapore; Chew Lim Tan, National University of Singapore1336 | Handwritten Word Spotting with Corrected AttributesJon Almazn*, Computer Vision Center; Albert Gordo, INRIA (?); Alicia Forns, Computer Vision Center; Ernest Valveny, Computer Vision CenterFace and gesture | 93 | Adapting Classification Cascades to New Domainsvidit Jain*, ; Sachin Farfade,99 | Rank Minimization across Appearance and Shape for AAM Ensemble FittingXin Cheng*, Queensland U of Tech; Sridharan Sridha, Queenland U of Tech; Jason Saragih, Queenland U of Tech; Simon Lucey,212 | Exemplar-based Graph Matching for Robust Facial Landmark LocalizationFeng Zhou*, Carnegie Mellon University; Jonathan Brandt, Adobe; Zhe Lin, Adobe Research254 | Hybrid Deep Learning for Computing Face SimilaritiesYi Sun*, CUHK; Xiaogang Wang, "The Chinese University of Hong Kong, Hongkong"316 | Multi-Scale Topological Features for Hand Posture Representation and AnalysisKaoning Hu*, SUNY - Binghamton; Lijun Yin, Binghamton University State University of New York403 | On One-Shot Kernels: explicit feature maps and propertiesStefanos Zafeiriou*, Imperial; Irene Kotsia, Imperial College London/Middlesex University404 | Learning Slow Features for Behavior AnalysisLazaros Zafeiriou, Imperial College London; Mihalis Nicolaou, Imperial College London; Stefanos Zafeiriou*, Imperial; Symeon Nikitidis, Imperial College London; Maja Pantic, Imperial College520 | Face Recognition via Random Path Measure Over Face Patch NetworkChaochao Lu*, CUHK; Deli Zhao, The Chinese University of Hong Kong598 | Learning Identity-Preserving FeaturesZhenyao Zhu*, CUHK; Ping Luo, CUHK601 | Face Recognition via Ranking over An Archetype HullYuanjun Xiong*, The Chinese University of Hong Kong; Wei Liu, Columbia University; Deli Zhao, The Chinese University of Hong Kong660 | Cascaded Shape Space Pruning for Robust Facial Landmark DetectionXiaowei Zhao*, ICT,CAS; Shiguang Shan, "Chinese Academy of Sciences, China"; Xiujuan Chai, jdl; Xilin Chen,695 | Like Father, Like Son: Facial Expression Dynamics for Kinship VerificationHamdi Dibeklioglu*, University of Amsterdam; Albert Salah, Bogazici University; Theo Gevers, University of Amsterdam705 | Sieving Regression Forest Votes for Facial Feature Detection in the WildHeng Yang*, Queen Mary Uni. of London ; Ioannis Patras,712 | Facial Action Unit Event Detection by Cascade of TasksXiaoyu Ding*, Carnegie Mellon University; Wen-Sheng Chu, Carnegie Mellon University; Fernando de la Torre, Carnegie Mellon University ; Jeffrey Cohn, ; Qiao Wang, Southeast University716 | Fast Face Detector Training Using Tailored ViewsKristina Scherbaum*, MMCI; Rogerio Feris, ; James Petterson, ; Volker Blanz , University of Siegen; Hans-Peter Seidel, MPI Saarland736 | Coupling Alignments with Recognition for Still-to-Video Face RecognitionZhiwu Huang*, ICT, CAS; Xiaowei Zhao, ICT,CAS; Shiguang Shan, "Chinese Academy of Sciences, China"; Ruiping Wang, Institute of Computing Technology, Chinese Academy of Sciences; Xilin Chen,757 | A Cascaded Deep Learning Architecture for Pedestrian DetectionXingyu ZENG*, The Chinese University of HK; Wanli Ouyang, The Chinese University of HK; Xiaogang Wang, "The Chinese University of Hong Kong, Hongkong"916 | Optimization problems for fast AAM fitting in-the-wildGeorgios Tzimiropoulos*, University of Lincoln/Imperial College London; Maja Pantic, Imperial College932 | Two-Point Gait: Decoupling Gait from Body ShapeStephen Lombardi*, Drexel Unversity; Ko Nishino, "Drexel University, USA"; Yasushi Makihara, Osaka university; Yasushi Yagi,963 | Handling Occlusions with Franken-classifiersMarkus Mathias*, KU Leuven; Rodrigo Benenson, MPI-Inf; Radu Timofte, KU Leuven; Luc Van Gool, KU Leuven972 | Pose-free Facial Landmark Fitting via Optimized Part Mixtures and Cascaded Deformable Shape ModelXiang Yu*, Rutgers University; Junzhou Huang, University of Texas at Arlington; Shaoting Zhang, Rutgers University; Wang Yan, Rutgers University; Dimitris Metaxas, Rutgers University1040 | Similarity Metric Learning for Face RecognitionQiong Cao, University of Exeter; Yiming Ying*, University of Exeter; Peng Li, University of Bristol1071 | Simultaneous Clustering and Tracklet Linking for Multi-Face Tracking in VideosBaoyuan Wu*, CASIA & RPI; Siwei Lyu, SUNY Albany; Baogang Hu, CASIA; Qiang Ji,1074 | Capturing Global Semantic Relationships for Facial Action Unit RecognitionZiheng Wang*, RPI; Yongqiang Li, Harbin Institute of Technology; SHANGFEI WANG, USTC; Qiang Ji,1075 | Unsupervised Random Forest Manifold Alignment for LipreadingYuru PEI*, Peking University; Tae-Kyun Kim, ; Hongbin Zha, "Peking University, China"1133 | Robust Feature Set Matching for Partial Face RecognitionRENLIANG WENG*, Nanyang Technological Universi; Jiwen Lu, Advanced Digital Sciences Center, Singapore; Junlin Hu, NTU; Gao Yang, Nanyang Technological University; Yap-Peng Tan,1178 | Learning People Detectors for Tracking in Crowded ScenesSiyu Tang*, Max planck institute ; Mykhaylo Andriluka, Max Planck Institute for Informatics; Anton Milan, TU Darmstadt; Konrad Schindler, ETH Zurich; Stefan Roth, "TU Darmstadt, Germany"; Bernt Schiele, "MPI Informatics, Germany"1239 | Robust face landmark estimation under occlusionXavier Burgos Artizzu*, Caltech; Pietro Perona, "Caltech, USA"; Piotr Dollar,1252 | Markov Network-based Unified Classifier for Face IdentificationWonjun Hwang*, Samsung AIT; Kyungshik Roh, ; Junmo Kim, KAIST1377 | Random Faces Guided Sparse Many-to-One Encoder for Pose-Invariant Face RecognitionYizhe Zhang*, ; Ming Shao, Northeastern University; Edward Wong, Polytechnic Institute of NYU; Yun Fu, Northeastern University1487 | A Deep Sum-Product Architecture for Robust Facial Attributes AnalysisPing Luo*, CUHK1489 | Estimating Human Pose with Flowing PuppetsSilvia Zuffi*, ; Javier Romero, MPI PS; Cordelia Schmid, "INRIA, France"; Michael Black, "Max Planck Institute for Intelligent Systems, Germany"1563 | Calibration-free Gaze Estimation using Human Gaze PatternsFares Alnajar*, University of Amsterdam; Theo Gevers, University of Amsterdam; Roberto Valenti, ; Sennay Ghebreab, University of Amsterdam1579 | Cross-view Action Recognition over Heterogeneous Feature SpacesXinxiao Wu*, ; Han Wang, Beijing Insititute of technolo; Cuiwei Liu, ; Yunde Jia,1624 | Efficient pedestrian detection by directly optimizing the partial area under the ROC curveSakrapee Paisitkriangkrai*, The University of Adelaide; Chunhua Shen, The University of Adelaide; Anton Van den Hengel, University of Adelaide1728 | Fingerspelling recognition with semi-Markov conditional random fieldsTaehwan Kim, TTIC; Gregory Shakhnarovich, TTIC; Karen Livescu*, TTIC1804 | Supervised and Unsupervised Within Class Covariance Normalization for Efficient Face RecognitionOren Barkan*, Tel Aviv University; Jonathan Weill, Tel Aviv University; Lior Wolf, "Tel Aviv University, Israel"; Hagai Aronowitz, IBM Research; Amir Averbuch, Tel Aviv University1839 | Breaking the chain: liberation from the temporal Markov assumption for tracking human posesryan Tokola*, ; Wongun Choi, University of Michigan; Silvio Savarese, "University of Michigan, USA"1930 | Hidden Factor Analysis for Age Invariant Face RecognitionDihong GONG, SIAT; Zhifeng LI*, SIAT; Dahua Lin, TTIC; Jianzhuang Liu, CUHK; Xiaoou Tang, Chinese University of Hong KongLow-level vision and image processing | 185 | Partial Sum Minimization of Singular Values in RPCA for Low-Level VisionTae-Hyun Oh, KAIST; Hyeongwoo Kim, KAIST; Yu-Wing Tai, "KAIST, Korea"; Jean-Charles Bazin, ETH-Z; In So Kweon*, KAIST205 | Efficient Image Dehazing with Boundary Constraint and Contextual RegularizationGaofeng MENG*, Chinese Academy of Sciences; Ying WANG, ; Jiangyong DUAN, ; Shiming Xiang, NLPR, CASIA; Chunhong Pan, NLPR, CASIA233 | Example-based Facade Texture SynthesisDengxin Dai*, CVL, ETH Zurich; Hayko Riemenschneider, CVL, ETH Zurich; Luc Van Gool, ETH; gerhard Schmitt, ETH Zurich266 | Efficient Salient Region Detection with Soft Image AbstractionMing-Ming Cheng*, Oxford Brookes University; Shuai Zheng, Oxford Brookes University; Jonathan Warrell, Oxford Brookes University; Vibhav Vineet, Oxford Brookes University; Wenyan Lin, Oxford Brookes University292 | A Generalized Low-Rank Appearance Model for Spatio-Temporally Correlated Rain StreaksYi-Lei Chen*, NTHU, Taiwan; Chiou-Ting Hsu, NTHU, Taiwan320 | Exploiting Reflection Change for Automatic Reflection RemovalYu Li*, NUS; Michael Brown, National University of Singapore328 | A Learning-Based Approach to Reduce JPEG Artifacts in Image MattingInchang Choi, ; Sunyeong Kim, KAIST; Michael Brown, National University of Singapore; Yu-Wing Tai*, "KAIST, Korea"340 | Illuminant Chromaticity from Image SequencesVeronique Prinet*, Hebrew University of Jerusalem; Dani Lischinski, ; Michael Werman,537 | Saliency Detection: A Boolean Map ApproachJianming Zhang*, Boston University; Stan Sclaroff, Boston University546 | From Where and How to What We SeeKarthikeyan Shanmuga Vadivel*, UCSB; Vignesh Jagadeesh, UCSB; Renuka Shenoy, UCSB; Miguel Eckstein, UCSB; B.S. Manjunath, UCSB661 | Single-patch low-rank prior for non-pointwise impulse noise removalRuixuan Wang*, University of Dundee; Emanuele Trucco, University of Dundee664 | Cross-Field Joint Image Restoration via Scale MapQiong Yan*, CUHK; Xiaoyong Shen, CUHK; Li Xu, CUHK; Shaojie Zhuo, qualcomm.com; Xiaopeng Zhang, ; Liang Shen, ; Jiaya Jia, Chinese University of Hong Kong840 | Salient Region Detection by UFO: Uniqueness, Focusness and ObjectnessPeng Jiang*, Shandong University; Jingliang Peng, cs.sdu.edu.cn; Haibin Ling,849 | Shape Index Descriptors Applied to Texture-Based Galaxy AnalysisKim Pedersen*, diku.dk; Kristoffer Stensbo-Smidt, DIKU; Andrew Zirm, NBI KU; Christian Igel, DIKU1101 | A New Image Quality Metric for Image Auto-DenoisingXiangfei Kong*, City University of Hong Kong; Kuan Li, NUDT; Qingxiong Yang, City University of Hong Kong; Ming-Hsuan Yang, "UC Merced, USA"; Liu Wenyin, Shanghai University of Electronic Power1186 | Contextual Hypergraph Modeling for Salient Object DetectionXi Li*, University of Adelaide; Yao Li, University of Adelaide; Chunhua Shen, The University of Adelaide; Anthony Dick, University of Adelaide ; Anton Van den Hengel, University of Adelaide1322 | EVSAC: Accelerating Hypotheses Generation by Modeling Matching Scores with Extreme Value TheoryVictor Fragoso*, UCSB; Pradeep Sen, UCSB; Sergio Rodriguez, UCSB; Matthew Turk, "UC Santa Barbara, USA"1342 | Restoring An Image Taken Through a Window Covered with Dirt or RainDavid Eigen*, Courant Institute, NYU; Dilip Krishnan, NYU; Rob Fergus, New York University1525 | SGTD: Structure Gradient and Texture Decorrelating Regularization for Image DecompositionQiegen Liu, ; Jianbo Liu, ; Pei Dong, ; Dong Liang*, Shenzhen Institutes of Advance1614 | A Joint Intensity and Depth Co-Sparse Analysis Model for Depth Map Super-ResolutionMartin Kiechle*, Technische Universitt Mnchen; Simon Hawe, Technische Universitt Mnchen; Martin Kleinsteuber, Technische Universitt Mnchen1719 | Estimating the Material Properties of Fabric Through Observation of MotionKatherine Bouman*, Massachusetts Institute of Tec; Bill Freeman, "MIT, USA"; Bei Xiao, ; Peter Battaglia, ; Wojciech Matusik, ; John Fisher, MIT1767 | Robust Tucker Tensor Decomposition for Efficient Image StorageMiao Zhang*, University of Texas at Arlingt; Chris Ding,1787 | Joint Noise Level Estimation from Personal Photo CollectionsYiChang Shih*, M.I.T.; Vivek Kwatra, ; Sergey Ioffe, ; Hui Fang, ; Troy Chinen,1898 | Super-resolution via Transform-invariant Group-sparse RegularizationCarlos Fernandez-Granda*, Stanford UniversityMedical and biological image analysis | 1215 | Tissue Classification via Unsupervised Feature Learning and Spatial Pyramid MatchingHang Chang*, Lawrence Berkeley National Lab; Nandita Nayak, ; Paul Spellman, ; Bahram Parvin,1317 | Uncertainty-driven Efficiently-Sampled Sparse Graphical Models for Concurrent Tumor Segmentation and Atlas RegistrationSarah Parisot*, Ecole Centrale Paris; William Wells, Surgical Planning Laboratory, Harvard Medical School; Stphane Chemouny, Intrasense SA; Hugues Duffau, Hpital Gui de Chauliac; Nikos Paragios, Ecole Centrale de Paris1550 | Drosophila Embryo Stage Annotation using Label PropagationTomas Kazmar*, IMP/ISTA; Evgeny Kvon, IMP; Alexander Stark, IMP; Christoph Lampert, Institute of Science and Technology Austria1893 | Detecting Irregular Curvilinear Structures in Gray Scale and Color Imagery using Multi-Directional Oriented FluxEngin Turetken*, EPFL; Carlos Becker, EPFL; Przemyslaw Glowacki, EPFL; fethallah Benmansour, ; Pascal Fua, "EPFL, Switzerland"Motion and tracking | 260 | Higher Order Matching for Consistent Multiple Target TrackingChetan Arora*, ; Amir Globerson,261 | Tracking via Robust Multi-Task Multi-View Joint Sparse RepresentationZhibin Hong*, University of Technology, Sydney; Xue Mei, Future Mobility Research department, Toyota Research Institute, North America; Danil Prokhorov, TTC; Dacheng Tao, University of Technology, Sydney263 | Measuring Flow Complexity in VideosSaad Ali*,282 | STAR3D: Simultaneous Tracking And Reconstruction of 3D Objects Using RGB-D DataYuheng(Carl) Ren*, Oxford University; Victor Prisacariu, Oxford ; David Murray, Oxford ; Ian Reid, University of Adelaide286 | Multiple Non-Rigid Surface Detection and RegistrationYi Wu*, UC Merced; Yoshihisa Ijiri, OMRON; Ming-Hsuan Yang, "UC Merced, USA"335 | Interactive Markerless Articulated Hand Motion Tracking Using RGB and Depth DataSrinath Sridhar*, Max-Planck-Institut Informatik; Antti Oulasvirta, Max-Planck-Institut Informatik; Christian Theobalt, MPI fuer Informatik336 | Latent Data Association: Bayesian Model Selection for Multitarget TrackingAleksandr Segal*, Oxford University Robotics Lab; Ian Reid, University of Adelaide423 | Optical Flow via Locally Adaptive Fusion of Complementary Data CostsTae Hyun Kim, Seoul National Univ.; Heeseok Lee, Seoul National University; Kyoung Mu Lee*, Seoul National University506 | Image Matching: a General Framework Combining Direct and Feature-based CostsJim Braux-Zin*, CEA, LIST; Adrien Bartoli, Universit?d'Auvergne; Romain Dupont, CEA, LIST516 | Online Robust Non-negative Dictionary Learning for Visual TrackingNaiyan Wang*, HKUST; Jingdong Wang, Microsoft Research Asia; Dit-Yan Yeung, HKUST651 | Real-time Body Tracking with One Depth Camera and Inertial SensorsThomas Helten*, MPI Informatik; Meinard Mller, International Audio Laboratories Erlangen; Hans-Peter Seidel, MPI Informatik; Christian Theobalt, MPI fuer Informatik655 | Discriminant Tracking Using Tensor Representation with Semi-supervised ImprovementJin Gao*, Institute of Automation Chinese Academy of Sciences; Weiming Hu, Institute of Automation Chinese Academy of Sciences; Junliang Xing, Institute of Automation, Chinese Academy of Sciences718 | Discriminative Label Propagation for Multi-object Tracking with Sporadic Appearance FeaturesAmit K.C.*, Universit catholique de Louva; Christophe De Vleeschouwer, UCL742 | Video Motion for Every Visible PointSusanna Ricco*, Duke University; Carlo Tomasi, Duke University825 | Initialization-Insensitive Visual Tracking Through Voting with Salient Local FeaturesKwang Yi*, Seoul National University; Hawook Jeong, Seoul National University; Byeongho Heo, Seoul National University; Hyung Jin Chang, Imperial College London; Jin Young Choi, Seoul National University832 | Optimal Orthogonal Basis and Image Assimilation: Motion ModelingIsabelle Herlin*, ; Etienne Huot, Inria; Giuseppe Papari, Lithicon921 | Revisiting Example Dependent Cost-Sensitive Learning with Decision TreesOisin Mac Aodha*, UCL; Gabriel Brostow,1007 | Robust Object Tracking with Online Multi-lifespan Dictionary LearningJunliang Xing*, Institute of Automation, Chinese Academy of Sciences; Jin Gao, Institute of Automation Chinese Academy of Sciences; Bing Li, NLPR, CASIA; Weiming Hu, Institute of Automation Chinese Academy of Sciences; Shuicheng Yan, "NUS, Singapore"1017 | Constructing Adaptive Complex Cells for Robust Visual TrackingDapeng Chen*, Xi'an Jiaotong University; Zejian Yuan, Xi'an jiaotong University; Yang Wu, Kyoto University; Geng Zhang, Xi'an Jiaotong University; Nanning Zheng, Xi'an Jiaotong University1041 | Coherent motion segmentation in moving camera videos using optical flow orientationsManjunath Narayana*, ; Erik Learned-Miller, University of Massachusetts at Amherst; Allen Hanson, University of Massachusetts Amherst1153 | Online Motion Segmentation using Dynamic Label PropagationAli Elqursh*, Rutgers University; Ahmed Elgammal,1159 | Topology-Constrained Layered Tracking with Latent FlowJason Chang*, CSAIL, MIT; John Fisher, MIT1160 | Pose-Configurable Generic Tracking of Elongated ObjectsDaniel Wesierski*, University; Patrick Horain,1278 | A Generic Deformation Model for Dense Non-Rigid Surface Registration: a Higher-Order MRF-based ApproachYun Zeng*, Harvard; Chaohui Wang, MPI ; David Gu, ; Dimitris Samaras, Stony Brook Univ.; Nikos Paragios, Ecole Centrale de Paris1345 | Modeling Self-Occlusions in Dynamic Shape and Appearance TrackingYanchao Yang, KAUST; Ganesh Sundaramoorthi*, KAUST1356 | Randomized Ensemble TrackingQinxun Bai*, Boston University; Zheng Wu, ; Stan Sclaroff, Boston University; Margrit Betke, Boston University; Camille Monnier,1400 | Camera Alignment using Trajectory Intersections in Unsynchronized VideosThomas Kuo*, UC Santa Barbara; Santhoshkumar Sunderrajan, UCSB; B.S. Manjunath, UCSB1690 | Minimal Basis Facility Location for Subspace SegmentationChoon Meng Lee*, NUS; Loong-Fah Cheong, NUS1718 | A Unified Rolling Shutter and Motion Blur Model for Dense 3D Visual TrackingMaxime Meilland*, I3S-CNRS-UNS; Andrew Comport, CNRS-I3S/UNS; Tom Drummond, Monash University1769 | PixelTrack: a fast adaptive algorithm for tracking non-rigid objectsStefan Duffner*, LIRIS, INSA de Lyon; Christophe Garcia, LIRIS, INSA de Lyon1826 | Conservation TrackingMartin Schiegg*, University of Heidelberg, HCI; Philipp Hanslovsky, Universitt Heidelberg, HCI; Bernhard Kausler, University of Heidelberg, HCI; Lars Hufnagel, EMBL, Heidelberg; Fred Hamprecht, HCI, University of Heidelberg1951 | Bayesian 3D tracking from monocular videoErnesto Brau*, ; Kobus Barnard, "University of Arizona, USA"; Jinyan Guan, University of Arizona; Kyle Simek, University of Arizona; Luca del Pero, ; Colin Dawson, University of ArizonaOptimization methods | 61 | A Convex Optimization Framework for Active LearningEhsan Elhamifar*, UC Berkeley; Guillermo Sapiro, Duke ; Shankar Sastry, UC Berkeley83 | Affine Constraint Group Sparse CodingYu-Tseh Chi*, University of Florida; Mohsen Ali, ; Muhammad Rushdi, ; Jeffrey Ho, University of Florida119 | Slice Sampling Particle Belief PropagationOliver Mller*, Leibniz Universitt Hannover; Michael Ying Yang, tnt.uni-hannover.de; Bodo Rosenhahn,141 | Non-Convex P-norm Projection for Robust SparsityMithun Das Gupta*, Ricoh Innovations Pvt. Ltd.; Sanjeev Kumar, Qualcomm232 | Shortest Paths with Curvature and TorsionPetter Strandmark*, Lund Univeristy; Johannes Uln, Lund University; Fredrik Kahl, Lund University242 | Unifying Nuclear Norm and Bilinear Factorization Approaches for Low-rank Matrix DecompositionRicardo Cabral*, Carnegie Mellon University; Fernando de la Torre, Carnegie Mellon University ; Joao Costeira, Instituto de Sistemas e Robotica; Alexandre Bernardino, Instituto de Sistemas e Robotica333 | Curvature Regularization using Partial EnumerationCarl Olsson*, ; Johannes Uln, Lund University; Yuri Boykov, "University of Western Ontario, Canada"; Vladimir Kolmogorov, "IST, Austria"342 | GOSUS: Grassmannian Online Subspace Updates with Structured-sparsityJia Xu*, UW-Madison; Vamsi Ithapu, ; Lopamudra Mukherjee, University of Wisc Whitewater; James Rehg, Georgia Institute of Technology ; Vikas Singh,369 | A Generalized Iterated Shrinkage Algorithm for Non-convex Sparse CodingWangmeng Zuo, Harbin Institute of Technology; Deyu Meng, Xi'an Jiaotong University; Lei Zhang*, The Hong Kong Polytechnic University; Xiangchu Feng, School of Science, Xidian University; David Zhang, The Hong Kong Polytechnic University466 | Sparse Variation Dictionary Learning for Face Recognition with A Single Training Sample Per PersonMeng YANG*, ETH Zuricn; Luc Van Gool, ETH; Lei Zhang, The Hong Kong Polytechnic University524 | Multi-Attributed Dictionary Learning for Sparse CodingChen-Kuo Chiang*, National Tsing Hua University; Te-Feng Su, ; Yen Chih, ; Shang-Hong Lai, NTHU1019 | Log-Euclidean Kernels for Sparse Representation and Dictionary LearningPeihua Li*, Dalian University of Technolog; Qilong Wang, ; Wangmeng Zuo, Harbin Institute of Technology; Lei Zhang, The Hong Kong Polytechnic University1179 | Bounded Labeling Function for Global Segmentation of Multi-Part Objects with Geometric ConstraintsMasoud S. Nosrati*, Simon Fraser University; Shawn Andrews, SFU; Ghassan Hamarneh, SFU1245 | Coupled Dictionary and Feature Space Learning with Applications to Cross-Domain Image Synthesis and RecognitionDe-An Huang, Academia Sinica; Yu-Chiang Frank Wang*, Academia Sinica1335 | Total Variation Regularization for Functions with Values in a ManifoldJan Lellmann*, University of Cambridge; Evgeny Strekalovskiy, TU Munich; Sabrina Koetter, TU Munich; Daniel Cremers, Technische Universitt Mnchen1486 | Fast online orthogonal dictionary learning and image restorationChenglong Bao, nus.edu.sg; Jianfeng Cai, uiowa.edu; Hui Ji*, "NUS, Singapore"1616 | Latent Space Sparse Subspace ClusteringVishal Patel*, UMIACS; Hien Nguyen , UMIACS; Rene Vidal, Johns Hopkins University1641 | On the Mean Curvature Flow on Graphs with Applications in Image and Manifold ProcessingEl chakik Abdallah*, Greyc Laboratory; abderrahim ELmoataz, ; ahcen Sadi,1779 | Semi-Supervised Robust Dictionary Learning via Efficient L2,0+-Norms MinimizationHua Wang*, Colorado School of Mines; Feiping Nie, University of Texas at Arlington; Heng Huang, UTA1825 | Large-scale Image Annotation by Efficient and Robust Kernel Metric LearningZheyun Feng*, Michigan State University; Rong Jin, Michigan State University; Anil Jain, Michigan State UniversityPerformance evaluation | 78 | Tracking Revisited using RGBD Camera: Benchmark and BaselinesShuran Song, HKUST; Jianxiong Xiao*, MIT767 | Perceptual Fidelity Aware Mean Squared ErrorWufeng Xue, Xi'an Jiaotong University; Xuanqin Mou*, Xi'an Jiaotong University; Lei Zhang, The Hong Kong Polytechnic University; Xiangchu Feng, School of Science, Xidian University1620 | Saliency and Human Fixations: State-of-the-art and Study of Comparison MetricsNicolas Riche*, UMONS; Matthieu Duvinage, UMONS; Matei Mancas, UMONS; Bernard Gosselin, UMONS; Thierry Dutoit, UMONSPhysics-based vision and Shape-from-X | 42 | A Simple Model for Intrinsic Image Decomposition with Depth CuesQifeng Chen, ; Vladlen Koltun*, Stanford University188 | Real-World Normal Map Capture for Nearly Flat Reflective SurfacesBastien Jacquet*, ETH Zurich; Christian Hne, ETH Zrich; Kevin Koeser, ; Marc Pollefeys, ETH223 | Multiview Photometric Stereo using Planar Mesh ParameterizationJaesik Park, KAIST; Sudipta Sinha, ; Yasuyuki Matsushita, Microsoft Research Asia; Yu-Wing Tai, "KAIST, Korea"; In So Kweon*, KAIST230 | High Quality Shape from a single RGB-D Image under Uncalibrated Natural IlluminationYudeog Han*, KAIST; Joon-Young Lee, KAIST; Inso Kweon, "KAIST, Korea"231 | Depth from Combining Defocus and Correspondence Using Light-Field CamerasMichael Tao*, ; Sunil Hadap, Adobe Inc.; Jitendra Malik, UC Berkeley; Ravi Ramamoorthi, U.C. Berkeley885 | Multi-View Normal Field Integration for 3D Reconstruction of Mirroring ObjectsMichael Weinmann*, University of Bonn; Aljosa Osep, University of Bonn; Roland Ruiters, University of Bonn; Reinhard Klein, University of Bonn1539 | Matching Dry to Wet MaterialsYaser Yacoob*, Univ of MarylandRecognition: detection, categorization, classification, indexing, matching | 24 | Quadruplet-wise Image Similarity LearningMarc Law*, LIP6; Nicolas Thome, LIP6; Matthieu Cord,37 | Human Attribute Recognition By Rich Appearance DictionaryJungseock Joo*, UCLA; Shuo Wang, ; Song Chun Zhu, UCLA69 | Elastic Net Constraints for Shape MatchingEmanuele Rodola*, The University of Tokyo; Andrea Torsello, ; Tatsuya Harada, University of Tokyo; Yasuo Kuniyoshi, The University of Tokyo77 | Semantic RGB-D Bundle Adjustment with Human in the LoopJianxiong Xiao*, MIT; Andrew Owens, MIT; Antonio Torralba, MIT85 | Discriminatively Trained Templates for 3D Object Detection: A Real Time Scalable ApproachReyes Rios-Cabrera*, KULeuven; Tinne Tuytelaars, KU Leuven89 | Discovering Object FunctionalityBangpeng Yao*, Stanford University; Jiayuan Ma, ; Fei-Fei Li, Stanford University96 | Unsupervised Visual Domain Adaptation Using Subspace AlignmentBasura Fernando*, KU Leuven; Amaury Habrard, University Jean Monnet of Saint-Etienne; Marc Sebban, University of Jean Monnet in Saint-Etienne, Hubert Curien Laboratory; Tinne Tuytelaars, KU Leuven97 | Data-Driven 3D Primitives for Single Image UnderstandingDavid Fouhey*, Carnegie Mellon University; Abhinav Gupta, ; Martial Hebert, "CMU, USA"110 | Complementary Projection HashingZhongming Jin*, Zhejiang University; Deng Cai, ; Yao Hu, Zhejiang university; Debing Zhang, Zhejiang university; Xuelong Li,127 | Deformable Part Descriptors for Fine-grained Recognition and Attribute PredictionNing Zhang*, EECS, UC Berkeley; Ryan Farrell, ICSI, UC Berkeley; Trevor Darrell,145 | No Matter Where You Are: Flexible Graph-guided Multi-task Learning for Multi-view Head Pose Classification Under Target MotionYan Yan*, University of Trento; Elisa Ricci, University of Perugia; Ramanathan Subramanian, Advanced Digital Sciences Center in Singapore; Oswald Lanz, FBK Fondazione Bruno Kessler; nicu Sebe, University of Trento158 | The Interestingness of ImagesMichael Gygli*, ETH Zurich; Helmut Grabner, ; Hayko Riemenschneider, CVL, ETH Zurich; Luc Van Gool, ETH170 | Joint Deep Learning for Pedestrian DetectionWanli Ouyang*, The Chinese University of HK; Xiaogang Wang, "The Chinese University of Hong Kong, Hongkong"190 | Bird Part Localization Using Exemplar-Based Models with Enforced Pose and Subcategory ConsistencyJiongxin Liu*, COLUMBIA UNIVERSITY; Peter Belhumeur, "Columbia University, USA"196 | Segmentation Driven Object Detection with Fisher VectorsRamazan Gokberk CINBIS*, INRIA Grenoble; Jakob Verbeek, "INRIA, France"; Cordelia Schmid, "INRIA, France"206 | Learning Discriminative Part Detectors for Image Classification and CosegmentationJian Sun*, Xi'an Jiaotong University; Jean Ponce, "ENS, France"224 | Find the Best Path: an Efcient and Accurate Classier for Image HierarchiesMin Sun*, ; Wan Huang, University of Michigan at Ann Arbor; Silvio Savarese, University of Michigan at Ann Arbor245 | Handling Uncertain Tags in Visual RecognitionArash Vahdat*, Simon Fraser University; Greg Mori, Simon Fraser University246 | Compositional Models for Video Event Detection: A Multiple Kernel Learning Latent Variable ApproachArash Vahdat*, Simon Fraser University; Kevin Cannons, Simon Fraser University; Greg Mori, Simon Fraser University ; Sangmin Oh, Kitware Inc.; Ilseo Kim,253 | Hierarchical Part Matching for Fine-Grained Visual CategorizationLingxi Xie*, Tsinghua University; Qi Tian, University of Texas at San Antonio; Shuicheng Yan, "NUS, Singapore"; Bo Zhang, Tsinghua University268 | Detecting avocados to zucchinis: what have we done, and where are we going?Olga Russakovsky*, ; Jia Deng, Stanford University; Zhiheng Huang, Stanford University; Alexander Berg, Stony Brook University; Fei-Fei Li, Stanford University291 | Person Re-identification by Salience MatchingRui Zhao*, CUHK; Wanli Ouyang, The Chinese University of HK; Xiaogang Wang, "The Chinese University of Hong Kong, Hongkong"294 | Saliency Detection via Dense and Sparse ReconstructionXiaohui Li*, DUT, China; huchuan Lu, DUT,China; Ming-Hsuan Yang, "UC Merced, USA"; Lihe Zhang, DUT, China; Xiang Ruan,295 | A Deformable Mixture Parsing Model with ParseletsJian Dong*, NUS; Qiang Chen, ; Wei Xia, NUS; Zhongyang Huang, ; Shuicheng Yan, "NUS, Singapore"310 | Detecting Dynamic Objects with Multi-View Background SubtractionRal Daz, University of California, Irvine; Sam Hallman, University of California, Irvine; Charless Fowlkes*, University of California, Irvine338 | Implied Feedback: Learning Nuances of User Behavior in Image SearchDevi Parikh*, Virginia Tech; Kristen Grauman, University of Texas at Austin343 | A Data Set and a Stopwatch Hidden Markov Model for Event Recognition in Photo CollectionsLukas Bossard*, ETH Zurich; Matthieu Guillaumin, ETH Zurich; Luc Van Gool, ETH350 | Joint optimization for consistent multiple graph matchingJunchi Yan*, Shanghai Jiao Tong University; Yu Tian, Shanghai Jiao Tong University; Hongyuan Zha, Georgia Tech; Xiaokang Yang, ; Ya Zhang, Shanghai Jiao Tong University376 | Ensemble Projections for Semi-supervised Image ClassificationDengxin Dai*, CVL, ETH Zurich; Luc Van Gool, ETH379 | Prime Object Proposals with Randomized Prim's AlgorithmSantiago Manen*, BIWI ETH Zurich; Hayko Riemenschneider, CVL, ETH Zurich; Matthieu Guillaumin, ETH Zurich; Luc Van Gool, ETH381 | Bayesian Joint Topic Modelling for Weakly Supervised Object LocalisationZhiyuan Shi*, Queen Mary Univ.of London; Timothy Hospedales, EECS, QMUL; Tao Xiang, EECS,QMUL411 | Joint Inverted IndexingYan Xia*, USTC; Kaiming He, Mirosoft Research Asia; Fang Wen, ; Jian Sun, "Microsoft Research, China"426 | Low-Rank Sparse Coding for Image ClassificationTianzhu Zhang*, ADSC of UIUC in Singapore; Bernard Ghanem, KAUST; Si Liu, National University of Singapore; Changsheng Xu, CASIA; Narendra Ahuja,533 | Learning Near-Optimal Cost-Sensitive Decision Policy for Object DetectionTianfu Wu*, UCLA; Song Chun Zhu, UCLA539 | Nested Shape DescriptorsJeffrey Byrne*, University of Pennsylvania540 | Unbiased Metric Learning: Utilize Biased Datasets and Web ImagesChen Fang*, Dartmouth College; Ye Xu, Dartmouth College; Daniel Rockmore, Dartmouth College542 | Latent Task Adaptation with Large-scale HierarchiesYangqing Jia*, UC Berkeley; Trevor Darrell,545 | Mining Multiple Queries for Image Retrieval: On-the-fly learning of an Object-specific Mid-level RepresentationBasura Fernando*, KU Leuven; Tinne Tuytelaars, KU Leuven549 | Parsing IKEA Objects: Fine Pose EstimationJoseph Lim*, MIT; Hamed Pirsiavash, MIT; Antonio Torralba, MIT566 | Improving Graph Matching via Density MaximizationChao Wang*, University of Wollongong ; Lei Wang, University of Wollongong607 | Allocentric Pose EstimationJos Oramas*, KULeuven - ESAT; Luc De Raedt, KUleuven - CS; Tinne Tuytelaars, KU Leuven614 | NYC3DCars: A Dataset of 3D Vehicles in Geographic ContextKevin Matzen*, Cornell University; Noah Snavely, "Cornell, USA"624 | Collaborative Active Learning of a Kernel Machine Ensemble for RecognitionGang Hua*, Stevens Institute of Technology; Chengjiang Long, Stevens Institute of Technology; Ming Yang, NEC Labs America; Yan Gao, Northwestern University632 | Saliency Detection via Absorbing Markov ChainBowen Jiang*, DUT; Lihe Zhang, DUT, China; huchuan Lu, DUT,China; Ming-Hsuan Yang, "UC Merced, USA"; Chuan Yang,683 | Learning Coupled Feature Spaces for Cross-modal MatchingKaiye Wang*, NLPR; Ran He, NLPR, CASIA; Wei Wang, NLPR; Liang Wang, unknown; Tieniu Tan, "NLPR, China"690 | A General Two-step Approach to Learning-Based HashingGuosheng Lin*, The University of Adelaide; Chunhua Shen, The University of Adelaide; Anton Van den Hengel, University of Adelaide ; David Suter,692 | Active Visual Recognition with Expertise Estimation in CrowdsourcingChengjiang Long, Stevens Institute of Technology; Gang Hua*, Stevens Institute of Technology; Ashish Kapoor, Microsoft Research719 | Attribute Adaptation for Personalized Image SearchAdriana Kovashka*, ; Kristen Grauman, University of Texas at Austin723 | Attribute Pivots for Guiding Relevance Feedback in Image SearchAdriana Kovashka*, ; Kristen Grauman, University of Texas at Austin729 | Unsupervised Domain Adaptation by Domain Invariant ProjectionMahsa Baktashmotlagh*, University of Queensland; Mehrtash Harandi, NICTA; Brian Lovell, ; Mathieu Salzmann, NICTA759 | Look Into Sparse Representation-based Classification: A Margin-based PerspectiveZhaowen Wang*, UIUC; Jianchao Yang, Adobe Systems Inc.; Nasser Nasrabadi, US Army Research Lab; Thomas Huang, University of Illinois at Urbana-Champaign770 | Semantic-aware Co-indexing for Near-duplicate Image RetrievalShiliang Zhang, UTSA; Ming Yang*, NEC Labs America; Xiaoyu Wang, NEC Labs America; Yuanqing Lin, ; Qi Tian, University of Texas at San Antonio780 | CoDeL: An Efficient Human Co-detection and Labeling FrameworkJianping Shi*, CUHK ; Renjie Liao, CUHK; Jiaya Jia, Chinese University of Hong Kong781 | Modeling Occlusion by Discriminative AND-OR StructuresBo Li*, Beijing Institute of Tech.; Wenze Hu, ; Tianfu Wu, UCLA; Song Chun Zhu, UCLA782 | A Scalable Unsupervised Feature Merging Approach to Efficient Dimensionality Reduction of High-dimensional Visual DataLingqiao Liu*, Australian National University; Lei Wang, University of Wollongong784 | Feature Weighting via Optimal Thresholding for Video AnalysisZhongwen Xu*, Zhejiang University; Yi Yang, cmu.edu; Ivor Tsang, ; nicu Sebe, University of Trento; Alexander Hauptmann, Carnegie Mellon University847 | Decomposing Bag of Words HistogramsAnkit Gandhi*, IIIT Hyderabad; Karteek Alahari, ENS-Willow; c. v. Jawahar, IIIT Hyderabad869 | SIFTpack: a compact representation for efficient SIFT matchingAlexandra Gilinsky*, Technion; Lihi Zelnik-Manor, "Technion, Israel"880 | Attribute Dominance: What Pops Out?Naman Turakhia, ; Devi Parikh*, Virginia Tech907 | Learning the Visual Interpretation of SentencesLarry Zitnick*, "Microsoft Research, USA"; Devi Parikh, Virginia Tech; Lucy Vanderwende, Microsoft Research910 | How Related Exemplars Help Complex Event Detection in Web Videos?Yi Yang*, cmu.edu; Zhigang Ma, The University of Trento; Zhongwen Xu, Carnegie Mellon University; Shuicheng Yan, "NUS, Singapore"; Alexander Hauptmann, Carnegie Mellon University915 | An Adaptive Descriptor Design for Object Recognition in the WildZhenyu Guo*, University of British Columbia; Z.Jane Wang, University of British Columbia949 | Training deformable part models with decorrelated featuresRoss Girshick*, UC Berkeley; Jitendra Malik, UC Berkeley950 | Volumetric Semantic Segmentation using Pyramid Context FeaturesJonathan Barron*, UC Berkeley; Pablo Arbelaez, ; Soile Keranen, LBL; David Knowles, LBL; Mark Biggin, LBL; Jitendra Malik, UC Berkeley973 | SYM-FISH: A Symmetry-aware Flip Invariant Sketch Histogram Shape DescriptorXiaochun Cao, Chinese Academy of Sciences; Hua Zhang*, Tju; Si Liu, National University of Singapore; Xiaojie Guo, Tianjin University978 | PhotoOCR: Reading Text in Uncontrolled ConditionsMark Cummins*, Google; Alessandro Bissacco, Google Inc.; Yuval Netzer, Google; Hartmut Neven, Google1000 | Neighbor-To-Neighbor Search for Fast Coding of Feature VectorsNakamasa Inoue*, Tokyo Institute of Technology; Koichi Shinoda, Tokyo Institute of Technology1018 | A Novel Earth Mover's Distance Methodology for Image Matching with Gaussian Mixture ModelsPeihua Li*, Dalian University of Technolog; Qilong Wang, ; Lei Zhang, The Hong Kong Polytechnic University1043 | Pose Estimation and Segmentation of People in 3D MoviesKarteek Alahari*, ENS-Willow; Guillaume Seguin, ; Josef Sivic, Ecole Normale Suprieure; Ivan Laptev, "INRIA, France"1049 | Coherent Object Detection with 3D Geometric Context from a Single ImageJiyan Pan*, Carnegie Mellon University; Takeo Kanade,1061 | Quantize and Conquer: A dimensionality-recursive solution to nearest neighbor search, clustering, and image retrievalYannis Avrithis*, NTUA1078 | Efficient Hand Pose Estimation from a Single Depth ImageChi Xu, Bioinformatics Institute; Li Cheng*, Bioinformatics Institute1132 | Symbiotic Segmentation and Part Localization for Fine-Grained CategorizationYuning Chai*, University of Oxford; Victor Lempitsky, Skolkovo Institute of Science and Technology; Andrew Zisserman, University of Oxford1137 | Probabilistic Elastic Part Model for Unsupervised Face Detector AdaptationHaoxiang Li, Stevens Institute of Technology; Gang Hua*, Stevens Institute of Technology; Zhe Lin, Adobe Research; Jonathan Brandt, Adobe; Jianchao Yang, Adobe Systems Inc.1141 | Text Localization in Natural Images using Stroke Feature Transform and Text Covariance DescriptorsWeilin Huang, Adobe Research; Zhe Lin, Adobe Research; Jianchao Yang, Adobe Systems Inc.; Jue Wang*,1187 | Hierarchical Joint Max-Margin Learning of Mid and Top Level Representations for Visual RecognitionHans Lbel*, Universidad Catlica de Chile; Rene Vidal, Johns Hopkins University; lvaro Soto, Universidad Catlica de Chile1193 | A Unified Probabilistic Approach Modeling Relationships between Attributes and ObjectsXiaoyang Wang*, RPI; Qiang Ji,1202 | Write a Classifier: Zero Shot Learning Using Purely Textual DescriptionsMohamed Elhoseiny*, Rutgers Universeity; Ahmed Elgammal, ; Babak Saleh, Rutgers University1207 | Learning Hash Codes with Listwise Supervision for Web-Scale Image SearchJun Wang*, IBM T. J. Watson Research; Wei Liu, Columbia University; Andy Sun, IBM ; Yugang Jiang, Fudan University1214 | Synergistic Clustering of Image and Segment Descriptors for Unsupervised Scene UnderstandingDaniel Steinberg*, ACFR; Oscar Pizarro, ACFR; Stefan Williams, ACFR1224 | Image Set Classification Using Holistic Multiple Order Statistics Features and Localized Multi-Kernel Metric LearningJiwen Lu*, Advanced Digital Sciences Center, Singapore; Gang Wang, NTU; Pierre Moulin, UIUC1225 | Multi-Label Image Annotations Using New Graph Structured Sparsity Modelxiao Cai, University of Texas at Arlington; Feiping Nie, University of Texas at Arlington; Heng Huang*, UTA1226 | A Framework for Shape Analysis via Hilbert Space EmbeddingSadeep Jayasumana*, ANU; Mathieu Salzmann, NICTA; Hongdong Li, Australia National University; Mehrtash Harandi, NICTA1235 | Query-adaptive asymmetrical dissimilarities for visual object retrievalCai-Zhi Zhu*, National Institute of Informatics; Herv Jgou, INRIA; shin'ichi satoh, NII1263 | Fast Neighborhood Graph Search using Cartesian ConcatenationJing Wang, Peking University; Jingdong Wang*, Microsoft Research Asia; Gang Zeng, Peking University; Shipeng Li,1274 | Random Forests of Local Experts for Pedestrian DetectionJavier Marin*, Computer Vision Center; David Vazquez, Computer Vision Center, UAB; Jaume Amores, Computer Vision Center, UAB; Antonio Lopez, Computer Vision Center, UAB; Bastian Leibe, "RWTH Aachen University, Germany"1287 | Image Retrieval using Textual CuesAnand Mishra*, IIIT Hyderabad; Karteek Alahari, ENS-Willow; c. v. Jawahar, IIIT Hyderabad1294 | Random Grids: Fast Approximate Nearest Neighbors and Range Searching for Image SearchDror Aiger*, Google; Effrosyni Kokiopoulou, Google; Ehud Rivlin, Google Research1302 | Learning a Dictionary of Shape Epitomes with Application to Semantic LabelingLiang-Chieh Chen*, UCLA; George Papandreou, UCLA; Alan Yuille, UCLA1320 | Heterogeneous Auto-Similarities of Characteristics (HASC): exploiting relational information for classificationMarco San Biagio*, IIT; Marco Crocco, IIT; Marco Cristani, IIT; Samuele Martelli, IIT; Vittorio Murino, Istituto Italiano di Tecnologia1352 | Offline Mobile Instance Retrieval with a Small Memory FootprintJayaguru Panda*, IIIT Hyderabad; Michael Brown, National University of Singapore; c. v. Jawahar, IIIT Hyderabad1354 | Fine-Grained Categorization by AlignmentsEfstratios Gavves*, University of Amsterdam; Basura Fernando, KU Leuven; Cees Snoek, University of Amsterdam; Arnold Smeulders, ; Tinne Tuytelaars, KU Leuven1359 | Codemaps Segment, Classify and Search Objects LocallyZhenyang Li*, University of Amsterdam; Efstratios Gavves, University of Amsterdam; Koen van de Sande, ; Cees Snoek, University of Amsterdam; Arnold Smeulders,1392 | Visual Reranking through Weakly Supervised Multi-Graph LearningCheng Deng*, Xidian University; Rongrong Ji, Columbia University; Wei Liu, Columbia University; Dacheng Tao, """University of Technology, Sydney"""; xinbo Gao,1411 | Scene Collaging: Analysis and Synthesis of Natural Images with Semantic LayersPhillip Isola*, MIT; Ce Liu, Microsoft Research New England1423 | Discovering Details and Scene Structure with Hierarchical Iconoid ShiftTobias Weyand*, RWTH Aachen; Bastian Leibe, RWTH Aachen1454 | Pyramid Coding for Functional Scene Element Recognition in Video ScenesEran Swears*, Kitware Inc.; Anthony Hoogs, Kitware, USA; Kim Boyer, RPI1469 | A Fully Hierarchical Approach for Finding Correspondences in Non-rigid ShapesIvan Sipiran*, University of Chile; Benjamin Bustos, University of Chile1477 | BOLD features to detect texture-less objectsFederico Tombari*, University of Bologna; Alessandro Franchi, ; Luigi Di Stefano,1479 | Locally Affine Sparse-to-Dense Matching for Motion and Occlusion EstimationMarius Leordeanu*, Institute of Mathematics of the Romanian Academy; Andrei Zanfir, ; Cristian Sminchisescu, Lund University1506 | Support surface prediction in indoor scenesRuiqi Guo*, UIUC; Derek Hoiem, University of Illinois at Urbana-Champaign1526 | Domain Adaptive ClassificationFatemeh Mirrashed*, University of Maryland; Mohammad Rastegari, University of Maryland1534 | Understanding High-Level Semantics by Modeling Traffic PatternsHongyi Zhang, Peking University; Andreas Geiger*, KIT ; Raquel Urtasun, Toyota Technological Institute at Chicago1541 | Strong Appearance and Expressive Spatial Models for Human Pose EstimationLeonid Pishchulin*, Max Planck Institute for Infor; Mykhaylo Andriluka, Max Planck Institute for Informatics; Peter Gehler, Max Planck ; Bernt Schiele, "MPI Informatics, Germany"1548 | Box In the Box: Joint 3D Layout and Object Reasoning from Single ImagesAlexander Schwing*, ETH Zurich; Sanja Fidler, TTIC; Marc Pollefeys, ETH; Raquel Urtasun, Toyota Technological Institute at Chicago1552 | Learning to Transfer Privileged InformationViktoriia Sharmanska*, IST Austria; Novi Quadrianto, University of Cambridge; Christoph Lampert, Institute of Science and Technology Austria1553 | Estimating the 3D Layout of Indoor Scenes and its Clutter from Depth SensorsJian Zhang, ; Kan Chen, ; Alexander Schwing*, ETH Zurich; Raquel Urtasun, Toyota Technological Institute at Chicago1558 | Predicting an Object Location using a Global Image RepresentationJose Rodriguez-Serrano*, ; Diane Larlus,1575 | Take Your Favorite Cloud with YouKuan-Chuan Peng*, Cornell University; Tsuhan Chen,1592 | Supervise Binary Hash Code Learning With Jensen Shannon DivergenceLixin Fan*, Nokia Research Center1603 | Efficient 3D Scene Labeling Using Fields of TreesOlaf Khler*, University of Oxford; Ian Reid, University of Adelaide1669 | 3D Sub-Query Expansion for Improving Sketch-based Multi-View Image RetrievalYenliang Lin*, National Taiwan University; Cheng Yu Huang, ; Hao Jeng Wang, ; Winston Hsu,1675 | Quasi-Unsupervised Learning for Reliably Relating Visual AttributesSukrit Shankar*, Cambridge University; Joan Lasenby, Univerity of Cambridge; Roberto Cipolla, Cambridge University1677 | Simultaneous Segmentation and Pose Tracking in Moving CameraTaegyu Lim*, Samsung; Seunghoon Hong, POSTECH; Bohyung Han, POSTECH; JoonHee Han, POSTECH1684 | A Non-parametric Bayesian Network Prior of Human PoseAndreas Lehrmann*, MPI for Intelligent Systems; Peter Gehler, Max Planck ; Sebastian Nowozin, Microsoft Research Cambridge1775 | Heterogeneous Image Feature Integration via Multi-Modal Semi-Supervised Learning for Image Categorizationxiao Cai*, University of Texas at Arlington; Feiping Nie, University of Texas at Arlington; Heng Huang, UTA1851 | Spoken Attributes: Mixing Binary and Relative Attributes to Say the Right ThingAmir Sadovnik*, Cornell University; Andrew Gallagher, ; Devi Parikh, Virginia Tech; Tsuhan Chen,1857 | Model Recommendation with Virtual Probes for Ego-Centric Hand DetectionCheng Li, Tsinghua University; Kris Kitani*, Carnegie Mellon University1862 | Multi-Channel Correlation FiltersHamed Kiani galoogahi*, NUS; Terence Sim, NUS; Simon Lucey,1863 | Predicting Primary Gaze Behavior using Social Saliency FieldsHyun Soo Park*, CMU; Eakta Jain, TI; Yaser Sheikh,1865 | From Subcategories to Visual Composites: A Multi-Level Framework for Object DetectionTian Lan*, Simon Fraser University; Leonid Sigal, ; Michalis Raptis, Disney Research Pittsburgh; Greg Mori, Simon Fraser University1874 | Characterizing Layouts of Outdoor Scenes Using Spatial Topic ProcessesDahua Lin*, TTIC; Jianxiong Xiao, MIT1902 | Pictorial Human Spaces: How Well do Humans Perceive a 3D Articulated Pose?Elisabeta Marinoiu*, Romanian Academy of Science; Dragos Papava, Institute of Mathematics of the Romanian Academy; Cristian Sminchisescu, Lund University1909 | Building Parts-based Object Detectors via 3D GeometryAbhinav Shrivastava, Carnegie Mellon University; Abhinav Gupta*,Segmentation, grouping and shape representation | 67 | Online Video Superpixels for Temporal Window ObjectnessMichael Van den Bergh, ETH; Gemma Roig, ETH; Xavier Boix*, ETH; Santiago Manen, BIWI ETH Zurich; Luc Van Gool, ETH87 | Image Co-Segmentation via Consistent Functional MapsFan Wang*, Stanford University; Qixing Huang, Stanford University; Leonidas Guibas, Stanford University102 | Co-Segmentation by CompositionAlon Faktor*, Weizmann Institute of Science; Michal Irani, Weizmann Institute, Israel148 | Detecting Curved Symmetric Parts using a Deformable Disc ModelTom Lee*, University of Toronto; Sanja Fidler, TTI Chicago ; Sven Dickinson, University of Toronto244 | Image Segmentation with Cascaded Hierarchical Models and Logistic Disjunctive Normal NetworksMojtaba Seyedhosseini*, SCI; Mehdi Sajjadi, SCI; Tolga Tasdizen, SCI311 | Geometric Registration Based on Distortion EstimationWei Zeng*, Florida International Univ.; Mayank Goswami, Stony Brook University; Feng Luo, Rutgers University; xianfeng Gu, Stony Brook University339 | Learning CRFs for Image Parsing with Adaptive Subgradient DescentHonghui Zhang*, HKUST; Long Quan, "The Hong Kong University of Science and Technology, China"; Ping Tan, ; Jingdong Wang, Microsoft Research Asia346 | Efficient Higher-Order Clustering on the Grassmann ManifoldSuraj Jain, Indian Institute of Science; Venu Madhav Govindu*, Indian Institute of Science447 | Temporally Consistent SuperpixelsMatthias Reso*, TNT LUH Hannover; Joern Jachalsky, Technicolor; Joern Ostermann, Institut fr Informationsverarbeitung / Universitt Hannover; Bodo Rosenhahn,487 | Exemplar CutJimei Yang*, UC Merced; Yi-Hsuan Tsai, UC Merced; Ming-Hsuan Yang, "UC Merced, USA"617 | Cosegmentation and Cosketch by Unsupervised LearningJifeng Dai*, Tsinghua University; UCLA; Ying Nian Wu, UCLA; Jie Zhou, Tsinghua University; Song Chun Zhu, UCLA619 | Category-Independent Object-level Saliency DetectionYangqing Jia*, UC Berkeley; Mei Han, Google Research638 | Semantic Segmentation without Annotating SegmentsWei Xia*, NUS; Csaba Domokos, NUS; Jian Dong, NUS; Loong-Fah Cheong, NUS; Shuicheng Yan, "NUS, Singapore"674 | Multi-View Object Segmentation in Space and TimeAbdelaziz Djelouah*, Technicolor; Edmond Boyer, ; Jean-Sebastien Franco, Grenoble Universities; Patrick Perez, "Technicolor, France"; Franois Le Clerc,766 | Robust Trajectory Clustering for Motion SegmentationFeng Shi, Beihang University; zhong Zhou*, ; Jiangjian Xiao, ; Wei Wu,943 | Paper Doll Parsing: Retrieving Similar Styles to Parse Clothing ItemsKota Yamaguchi*, ; M. Hadi Kiapour, Stony Brook University; Tamara Berg, "Stony Brook University, USA"983 | Semi-supervised learning for large scale image cosegmentationZhengxiang Wang*, Fujitsu R&D Center ; Rujie Liu, Fujitsu R&D Center1192 | Parallel Transport of Deformations in Shape Space of Elastic SurfacesQIAN XIE*, Florida State University; Sebastian Kurtek, Ohiao State University; Huiling Le, ; Anuj Srivastava,1391 | Predicting Sufficient Annotation Strength for Interactive Foreground SegmentationSuyog Jain*, ; Kristen Grauman, University of Texas at Austin1431 | GrabCut in One CutMeng Tang, University of Western Ontario; Lena Gorelick*, University of Western Ontario; Olga Veksler, University of Western Ontario; Yuri Boykov, "University of Western Ontario, Canada"1434 | Progressive Multigrid Eigensolvers for Multiscale Spectral SegmentationMichael Maire*, California Institute of Technology; Stella Yu, ICSI; Pietro Perona, "Caltech, USA"1485 | Pedestrian Parsing via Deep Decompositional NetworkPing Luo*, CUHK1577 | Robust Subspace Clustering via Half-Quadratic MinimizationYingya Zhang*, NLPR, CASIA; Zhenan Sun, NLPR, CASIA; Ran He, NLPR, CASIA; Tieniu Tan, "NLPR, China"1674 | A Unified Video Segmentation Benchmark: Annotation, Metrics and AnalysisFabio Galasso*, MPI Informatics; Naveen Nagaraja, University of Freiburg; Tatiana Jimenez Cardenas, University of Freiburg; Thomas Brox, ; Bernt Schiele, "MPI Informatics, Germany"1695 | Automatic Kronecker Product Model Based Detection of Repeated Patterns in 2D Urban ImagesJuan Liu, Graduate Center City University of New York; Emmanouil Psarakis, University of Patras; Ioannis Stamos*, CUNY1742 | A Method of Perceptual-based Shape DecompositionChang Ma, Peking University; Zhongqian Dong, Peking University; Tingting Jiang, Peking University; yizhou Wang*, Peking University1786 | Sequential Bayesian Model Update under Structured Scene Prior for Semantic Road Scenes LabelingEvgeny Levinkov, MPII; Mario Fritz*, MPI Informatics1966 | Fast object segmentation in unconstrained videoAnestis Papazoglou*, University of Edinburgh; Vitto Ferrari, University of Edinburgh1974 | Video Segmentation by Tracking Many Figure-Ground SegmentsFuxin Li*, Georgia Inst. of Tech.; Taeyoung Kim, Georgia Institute of Technology; Ahmad Humayun, ; Wei Cai, Georgia Institute of Technology; James Rehg, Georgia Institute of TechnologyStatistical methods and learning | 73 | Group Norm for Learning Structured SVMs with Unstructured Latent VariablesDaozheng Chen, UMD; Dhruv Batra*, Virginia Tech; Bill Freeman, "MIT, USA"94 | Curvature-aware Regularization on Riemannian SubmanifoldsKwang In Kim*, MPI for Informatics; James Tompkin, MPI Informatik; Christian Theobalt, MPI fuer Informatik258 | Learning Graph Matching for Category Modeling from Large ScenesQuanshi Zhang*, University of Tokyo; Xuan Song, University of Tokyo; Xiaowei Shao, University of Tokyo; Ryosuke Shibasaki, University of Tokyo; Huijing Zhao, Peking University306 | Bayesian Robust Matrix Factorization for Image and Video ProcessingNaiyan Wang*, HKUST; Dit-Yan Yeung, HKUST360 | Transfer Feature Learning with Joint Distribution AdaptationMingsheng Long*, Tsinghua University; Jianmin Wang, Tsinghua University; Guiguang Ding, Tsinghua University; Philip Yu, University of Illinois at Chicago442 | Dynamic Structured Model SelectionDavid Weiss*, University of Pennsylvania; Benjamin Sapp, Google; Ben Taskar, University of Washington482 | Structured learning of sum-of-submodular higher order energy functionsAlex Fix, Cornel; Thorsten Joachims, Cornell; Sam Park, Cornell; Ramin Zabih*, Cornell University484 | What Is the Most Efficient Way to Select Nearest Neighbor Candidates for Fast Approximate Nearest Neighbor Search?Masakazu Iwamura*, Osaka Prefecture University; Tomokazu Sato, Osaka Prefecture University; Koichi Kise, Osaka Prefecture University641 | Alternating Regression Forests for Object Detection and Pose EstimationSamuel Schulter*, TUGraz; Christian Leistner, Microsoft; Paul Wohlhart, TU Graz; Peter Roth, ; Horst Bischof, Graz University of Technology642 | Linear Sequence Discriminant Analysis: A Model-Based Dimensionality Reduction Method for Vector SequencesBing Su*, Tsinghua University; Xiaoqing Ding, Tsinghua University930 | Robust Matrix Factorization with Unknown NoiseDeyu Meng*, Xi'an Jiaotong University; Fernando de la Torre, Carnegie Mellon University957 | Recursive Estimation of the Stein Center of SPD Matrices and its ApplicationsHesamoddin Salehian*, University of Florida; Guang Cheng, ; Baba Vemuri, "University of Florida, USA"; Jeffrey Ho, University of Florida968 | Manifold based Image Synthesis from Sparse SamplesHongteng Xu*, Georgia Tech; Hongyuan Zha, Georgia Tech988 | From Point to Set: Extend the Learning of Distance MetricsPengfei Zhu, The Hong Kong Polytechnic University; Lei Zhang*, The Hong Kong Polytechnic University; Wangmeng Zuo, Harbin Institute of Technology; David Zhang, The Hong Kong Polytechnic University1010 | Discriminative Metric and Prototype LearningMartin Kstinger*, Graz University of Technology; Peter Roth, ; Horst Bischof, Graz University of Technology1082 | Divide-and-Conquer Subspace SegmentationAmeet Talwalkar*, UC Berkeley; Lester Mackey, Stanford University; Yadong MU, Columbia University; Shih-Fu Chang, Columbia University; Michael Jordan, Berkeley1405 | Dynamic Label Propagation for Semi-supervised Multi-class Multi-label ClassificationBo Wang*, York University; John Tsotsos, "York University, Canada"1420 | Frustratingly Easy NBNN Domain AdaptationTatiana Tommasi*, IDIAP Martigny ; Barbara Caputo,1503 | Correlation Adaptive Subspace Segmentation by Trace LassoCanyi Lu*, National University of Singapo; Jiashi Feng, NUS; Zhouchen Lin, Peking University ; Shuicheng Yan, "NUS, Singapore"1504 | Correntropy Induced L2 Graph for Robust Subspace ClusteringCanyi Lu*, National University of Singapo; Zhouchen Lin, Peking University ; Shuicheng Yan, "NUS, Singapore"1647 | Robust Dictionary Learning by Error Source DecompositionZhuoyuan Chen*, Northwestern University; Ying Wu, Northwestern University1941 | Class-Specific Simplex-Latent Dirichlet Allocation for Image ClassificationMandar Dixit*, UC San Diego; Nikhil Rasiwasia, Yahoo Research; Nuno Vasconcelos, "UC San Diego, USA"Video: events, activities & surveillance | 23 | Monte Carlo Tree Search for Scheduling Activity RecognitionMohamed Amer*, OREGON STATE UNIVERSITY; Sinisa Todorovic, "Oregon State University, USA"; Alan Fern, Oregon State University; Song Chun Zhu, UCLA183 | Video Event Understanding using Natural Language DescriptionsVignesh Ramanathan*, Stanford University; Percy Liang, Stanford University; Fei-Fei Li, Stanford University204 | Translating video into natural language descriptionsMarcus Rohrbach*, MPI Informatics; Wei Qiu, Coli.uni-saarland.de; Ivan Titov, Saarland University; Stefan Thater, ; Manfred Pinkal, Saarland University; Bernt Schiele, "MPI Informatics, Germany"219 | Group Sparsity and Geometry Constrained Dictionary Learning for Action Recognition from Depth MapsJiajia Luo*, The University of Tennessee; Wei Wang, ; Hairong Qi,308 | Inferring "Dark Matter" and "Dark Energy" from VideosDan Xie, University of California Los Angeles; Sinisa Todorovic*, "Oregon State University, USA"; Song Chun Zhu, UCLA367 | Mining Motion Atoms and Phrases for Complex Action RecognitionLiMin Wang*, CUHK; Yu Qiao, SIAT395 | View-Invariant Action Recognition via Finding Canonical Views and PartsBehrooz Mahasseni*, Oregon State Univeristy; Sinisa Todorovic, "Oregon State University, USA"433 | Action recognition with improved trajectoriesHeng Wang*, ; Cordelia Schmid, "INRIA, France"438 | Person Re-Identification Post-Rank OptimisationChunxiao Liu, Tsinghua University; Chen Change Loy, CUHK; Shaogang Gong*, EECS, QMUL; Guijin Wang, Tsinghua University456 | ACTIVE: Activity Concept Transitions in Video Event ClassificationChen Sun*, University of Southern Califor; Ram Nevatia,492 | Manipulation Pattern Discovery: A Nonparametric Bayesian ApproachBingbing NI*, """""""""""""""""""""""""""""""Advanced Digital Sciences Center (ADSC), Singapor; Pierre Moulin, UIUC522 | Action and Event Recognition with Fisher vectors on a Compact Feature SetDan Oneata*, INRIA; Jakob Verbeek, "INRIA, France"; Cordelia Schmid, "INRIA, France"584 | Video Co-segmentation for Meaningful Action ExtractionJiaming Guo*, NUS; Zhuwen Li, NUS; Loong-Fah Cheong, NUS; Zhiying Zhou, NUS611 | Learning Maximum Margin Temporal Warping for Action RecognitionJiang Wang*, Northwestern University; Ying Wu, Northwestern University680 | Concurrent Action Detection with Structural PredictionPing Wei*, Xi'an Jiaotong University,UCLA; Nanning Zheng, Xi'an Jiaotong University ; Yibiao Zhao, UCLA; Song Chun Zhu, UCLA704 | Action Recognition with ActiontonJun Zhu*, Shanghai Jiao Tong University; baoyuan Wang, ; Zhuowen Tu, UCLA; Xiaokang Yang, ; Wenjun Zhang,864 | Stable hyper-pooling and query expansion for event detectionMatthijs Douze, INRIA; Jerome Revaud, ; Cordelia Schmid, "INRIA, France"; Herv Jgou*, INRIA946 | Active Learning of an Action Detector from Untrimmed VideosSunil Bandla, University of Texas at Austin; Kristen Grauman*, University of Texas at Austin954 | Flattening Supervoxel Hierarchies by the Uniform Entropy SliceChenliang Xu*, SUNY at Buffalo; Spencer Whitt, SUNY at Buffalo; Jason Corso, "SUNY Buffalo, USA"970 | From Actemes to Action: A Strongly-supervised Representation for Detailed Action UnderstandingWeiyu Zhang*, University of Pennsylvania; Konstantinos Derpanis, University of Pennsylvania; Menglong Zhu, University of Pennsylvania976 | From Semi-Supervised to Transfer Counting of CrowdsChen Change Loy*, CUHK; Shaogang Gong, EECS, QMUL; Tao Xiang, EECS,QMUL977 | Combining the Right Features for Complex Event RecognitionKevin Tang*, Stanford U.; Bangpeng Yao, Stanford University; Fei-Fei Li, Stanford University; Daphne Koller,984 | Understanding Human-Object Interaction via Exemplar based ModellingJian-Fang Hu*, Sun yat-sen university; Wei-Shi Zheng, ; Jian-Huang Lai, Sun Yat-sen University; Shaogang Gong, EECS, QMUL; Tao Xiang, EECS,QMUL1011 | Domain Transfer Support Vector Ranking for Person Re-Identification without Target Camera Label InformationAndy Jinhua Ma, Hong Kong Baptist University; Pong Chi Yuen*, Hong Kong Baptist University; Jiawei Li,1026 | Learning to Share Latent Tasks for Action RecognitionQiang Zhou*, NUS, Singapore; Gang Wang, NTU; Qi Zhao, National Univ. of Singapore1064 | Large Scale Video Hashing via Structure LearningGuangnan Ye*, Columbia University; Dong Liu, Columbia University; Jun Wang, IBM T. J. Watson Research; Shih-Fu Chang, Columbia University1116 | Finding Actors and Actions in MoviesPiotr Bojanowski*, INRIA; Francis Bach, "ENS and INRIA, France"; Ivan Laptev, "INRIA, France"; Jean Ponce, "ENS, France"; Cordelia Schmid, "INRIA, France"; Josef Sivic, Ecole Normale Suprieure1127 | Space-Time Robust Video Representation for Action RecognitionNicolas Ballas*, CEA/Mines-ParisTech; Yi Yang, cmu.edu; Lan Zshzsh, CMU; Betrand Delezoide, CEA; Franoise Preteux, Mines ParisTech; Alexander Hauptmann, Carnegie Mellon University1218 | YouTube2Text: Recognizing and Describing Arbitrary Activities Using Semantic Hierarchies and Zero-Shoot RecognitionSergio Guadarrama*, University of California, Berk; Niveda Krishnamoorthy, UT Austin; Girish Malkarnenkar, UT Austin; Raymond Mooney, ; Trevor Darrell, ; Kate Saenko, UMass Lowell1255 | Very Fast Abnormal Event DetectionCewu Lu*, The Chinese University of Hong; Jianping Shi, CUHK ; Jiaya Jia, Chinese University of Hong Kong1273 | Human Re-identification by Matching Compositional Template with Cluster SamplingYuanlu Xu, Sun Yat-Sen University; Liang Lin*, Sun Yat-Sen University; Weishi Zheng, ; Xiaobai Liu, Ucla.edu1331 | Finding Causal Interactions in Video SequencesMustafa Ayazoglu, Notheastern University; Burak Yilmaz, Northeastern University; Mario Sznaier*, Northeastern University; Octavia Camps,1382 | Dynamic Pooling for Complex Event RecognitionWeixin Li*, UC San Diego; Qian Yu, Sarnoff; Nuno Vasconcelos, UC San Diego1442 | Relative Attributes For Large-scale Abandoned Object DetectionQuanfu Fan*, IBM; Prasad Gabbur, ; Sharath Pankanti,1457 | Action Recognition and Localization by Hierarchical Space-Time SegmentsShugao Ma*, Boston University; Stan Sclaroff, Boston University; Jianming Zhang, Boston University; nazli Ikizler-cinbis, Department of Computer Engineering, Hacettepe University1501 | The "Moving Pose": An Efficient 3D Kinematics Descriptor for Low-Latency Action Recognition and DetectionMihai Zanfir, ; Marius Leordeanu*, Institute of Mathematics of the Romanian Academy; Cristian Sminchisescu, Lund University1510 | Modeling 4D Human-Object Interactions for Event and Object RecognitionPing Wei*, Xi'an Jiaotong University,UCLA; Yibiao Zhao, UCLA; Nanning Zheng, Xi'an Jiaotong University ; Song Chun Zhu, UCLA1658 | DIRECTED ACYCLIC GRAPH KERNELS FOR ACTION RECOGNITIONLing WANG*, Telecom ParisTech; Hichem SAHBI, LTCI, CNRS, (TELECOM ParisTech)1670 | Learning View-invariant Sparse Representations for Cross-view Action RecognitionJingjing Zheng*, University of Maryland; Zhuolin Jiang, University of Maryland1709 | A New Adaptive Segmental Matching Measure for Human Activity RecognitionShahriar Shariat*, Rutgers; Vladimir Pavlovic,1841 | Event Detection in Complex Scene Using Interval Temporal ConstraintsYifan Zhang*, CASIA; Qiang Ji, ; Hanqing Lu,1978 | Towards understanding action recognitionHueihan Jhuang*, ; Juergen Gall, Max Planck Institute for Intelligent Systems; Michael Black, "Max Planck Institute for Intelligent Systems, Germany"; Cordelia Schmid, INRIAVision for graphics | 201 | Modifying the Memorability of Face PhotographsAditya Khosla*, MIT; Wilma Bainbridge, MIT; Antonio Torralba, MIT; Aude Oliva,283 | Saliency Detection in Large Point SetsElizabeth Shtrom*, Technion; George Leifman, Technion; Ayellet Tal, Technion669 | Motion-Aware KNN Laplacian for Video MattingDingzeyu Li*, Columbia University; Qifeng Chen, ; Chi-Keung Tang, "Hong Kong University of Science and Technology, Hongkong"961 | Viewing Real-World Faces in 3DTal Hassner*,1242 | Accurate and Robust 3D Facial Performance Capture using Single RGBD ImagesYen-Lin Chen, Texas A&M University; Muscle Wu, Microsoft Research Asia; Fuhao SHi, Texas A&M University; Xin Tong, Microsoft Asia; Jinxiang Chai*, TAMUVision for the web | 1304 | Visual Semantic Complex Network for Web ImagesShi Qiu*, CUHK; Xiaogang Wang, "The Chinese University of Hong Kong, Hongkong"; Xiaoou Tang, Chinese University of Hong Kong1427 | What Do You Do? Recognize Occupations in a Photo via Social ContextMing Shao*, Northeastern University; Liangyue Li, Northeastern University; Yun Fu, Northeastern University

