构建Spark集群
来源:互联网 发布:js 微信点击放大图片 编辑:程序博客网 时间:2024/06/15 12:20
第一步:Spark集群需要的软件;
在1、2讲的从零起步构建好的Hadoop集群的基础上构建Spark集群,我们这里采用2014年5月30日发布的Spark 1.0.0版本,也就是Spark的最新版本,要想基于Spark 1.0.0构建Spark集群,需要的软件如下:
1.Spark 1.0.0,笔者这里使用的是spark-1.0.0-bin-hadoop1.tgz, 具体的下载地址是http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
如下图所示:
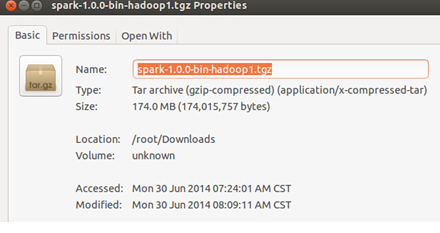
笔者是保存在了Master节点如下图所示的位置:
2.下载和Spark 1.0.0对应的Scala版本,官方要求的是Scala必须为Scala 2.10.x:
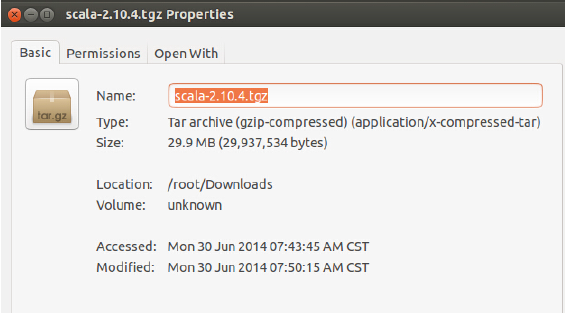
笔者下载的是“Scala 2.10.4”,具体官方下载地址为http://www.scala-lang.org/download/2.10.4.html 下载后在Master节点上保存为:
第二步:安装每个软件
安装Scala
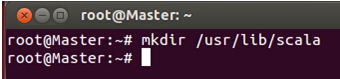
打开终端,建立新目录“/usr/lib/scala”,如下图所示:
2.解压Scala文件,如下图所示:

把解压好的Scala移到刚刚创建的“/usr/lib/scala”中,如下图所示

3.修改环境变量:

进入如下图所示的配置文件中:

按下“i”进入INSERT模式,把Scala的环境编写信息加入其中,如下图所示:

从配置文件中可以看出,我们设置了“SCALA_HOME”并把Scala的bin目录设置到了PATH中。
按下“esc“键回到正常模式,保存并退出配置文件:
执行以下命令是配置文件的修改生效:

4.在终端中显示刚刚安装的Scala版本,如下图所示

发现版本是”2.10.4”,这正是我们期望的。
当我们输入“scala”这个命令的的时候,可以直接进入Scala的命令行交互界面:

此时我们输入“9*9”这个表达式:
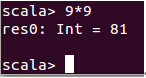
此时我们发现Scala正确的帮我们计算出了结果 。
此时我们完成了Master上Scala的安装;
由于我们的 Spark要运行在Master、Slave1、Slave2三台机器上,此时我们需要在Slave1和Slave2上安装同样的Scala,使用scp命令把Scala安装目录和“~/.bashrc”都复制到Slave1和Slave2相同的目录之之下,当然,你也可以按照Master节点的方式手动在Slave1和Slave2上安装。
在Slave1上Scala安装好后的测试效果如下:
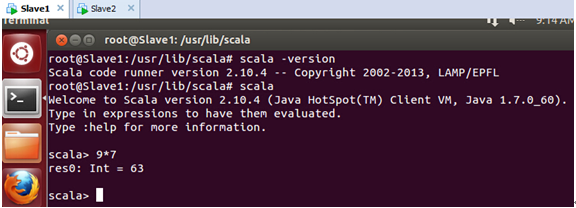
在Slave2上Scala安装好后的测试效果如下:

至此,我们在Master、Slave1、Slave2这三台机器上成功部署Scala。
安装Spark
Master、Slave1、Slave2这三台机器上均需要安装Spark。
首先在Master上安装Spark,具体步骤如下:
第一步:把Master上的Spark解压:
我们直接解压到当前目录下:

此时,我们创建Spark的目录“/usr/local/spark”:

把解压后的“spark-1.0.0-bin-hadoop1”复制到/usr/local/spark”下面:

第二步:配置环境变量
进入配置文件:

在配置文件中加入“SPARK_HOME”并把spark的bin目录加到PATH中:

配置后保存退出,然后使配置生效:

第三步:配置Spark
进入Spark的conf目录:

在配置文件中加入“SPARK_HOME”并把spark的bin目录加到PATH中:
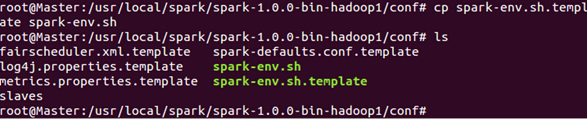
把spark-env.sh.template 拷贝到spark-env.sh:

在配置文件中添加如下配置信息:

其中:
JAVA_HOME:指定的是Java的安装目录;
SCALA_HOME:指定的是Scala的安装目录;
SPARK_MASTER_IP:指定的是Spark集群的Master节点的IP地址;
SPARK_WORKER_MEMOERY:指定的Worker节点能够最大分配给Excutors的内存大小,因为我们的三台机器配置都是2g,为了最充分的使用内存,这里设置为了2g;
HADOOP_CONF_DIR:指定的是我们原来的Hadoop集群的配置文件的目录;
保存退出。
接下来配置Spark的conf下的slaves文件,把Worker节点都添加进去:

打开后文件的内容:

我们需要把内容修改为:

可以看出我们把三台机器都设置为了Worker节点,也就是我们的主节点即是Master又是Worker节点。
保存退出。
上述就是Master上的Spark的安装。
第四步:Slave1和Slave2采用和Master完全一样的Spark安装配置,在此不再赘述。
启动并查看集群的状况
第一步:启动Hadoop集群,这个在第二讲中讲解的非常细致,在此不再赘述:
启动之后在Master这台机器上使用jps命令,可以看到如下进程信息:

在Slave1 和Slave2上使用jps会看到如下进程信息:


第二步:启动Spark集群
在Hadoop集群成功启动的基础上,启动Spark集群需要使用Spark的sbin目录下“start-all.sh”:

接下来使用“start-all.sh”来启动Spark集群!

读者必须注意的是此时必须写成“./start-all.sh”来表明是当前目录下的“start-all.sh”,因为我们在配置Hadoop的bin目录中也有一个“start-all.sh”文件!
此时使用jps发现我们在主节点正如预期一样出现了“Master”和“Worker”两个新进程!

此时的Slave1和Slave2会出现新的进程“Worker”:


此时,我们可以进入Spark集群的Web页面,访问“http://Master:8080”: 如下所示:

从页面上我们可以看到我们有三个Worker节点及这三个节点的信息。
此时,我们进入Spark的bin目录,使用“spark-shell”控制台:
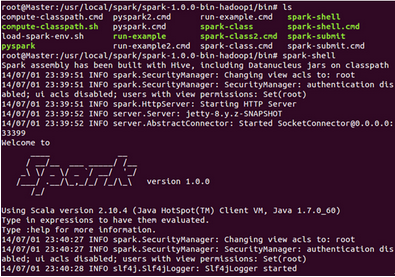

此时我们进入了Spark的shell世界,根据输出的提示信息,我们可以通过“http://Master:4040” 从Web的角度看一下SparkUI的情况,如下图所示:

当然,你也可以查看一些其它的信息,例如Environment:



同时,我们也可以看一下Executors:

可以看到对于我们的shell而言,Driver是Master:50777.
至此,我们 的Spark集群搭建成功,Congratulations!
- 构建Spark集群
- 王家林 构建spark集群
- docker 构建spark集群
- Spark API(1) 构建hadoop 集群
- 构建Spark分布式集群第一步:搭建Hadoop伪分布式环境
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(2)
- Spark视频第4期:构建商业生产环境下的Spark集群实战
- ELK结合Spark构建高可用架构及监控spark集群
- spark集群
- spark 集群
- spark集群
- spark集群
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-安装Ubuntu系统(1)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-安装Ubuntu系统(2)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-安装Ubuntu系统(3)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-运行Ubuntu系统(1)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-运行Ubuntu系统(2)
- 免费全能虚拟机VirtualBox 4.3.20官方下载
- 第十三周项目4 数组排序
- Android Secret Code
- 分页导航
- Vim配置
- 构建Spark集群
- Android上的单元测试
- [leetcode]Construct Binary Tree from Inorder and Postorder Traversal
- Photoshop脚本 > 高反差保留滤镜的使用
- 语法分析
- DOS系统功能调用(INT 21H)
- 使用SimpleAdapter加载sdcard图片
- JAVA的反射机制
- 使用spool工具导出oracle文本数据


