HTML解析利器HtmlAgilityPack
来源:互联网 发布:win7建立网络共享 编辑:程序博客网 时间:2024/05/19 19:30
转自:http://zhoufoxcn.blog.51cto.com/792419/595344/
- <?xml version="1.0" encoding="utf-8"?>
- <Articles>
- <Article>
- <Title>在ASP.NET中使用Highcharts js图表</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/537324</Url>
- <CreateAt type="en">2011-04-07</price>
- </Article>
- <Article>
- <Title lang="eng">Log4Net使用详解(续)</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2010/11/23/6029021.aspx</Url>
- <CreateAt type="zh-cn">2010年11月23日</price>
- </Article>
- <Article>
- <Title>J2ME开发的一般步骤</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2011/06/12/6540223.aspx</Url>
- <CreateAt type="zh-cn">2011年06月12日</price>
- </Article>
- <Article>
- <Title lang="eng">PowerDesign高级应用</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/166415</Url>
- <CreateAt type="zh-cn">2007-09-08</price>
- </Article>
- </Articles>
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
- namespace CrawlPageApplication
- {
- /**
- * 作者:周公
- * 日期:2011-06-23
- * Blog: http://blog.csdn.net/zhoufoxcn or http://zhoufoxcn.blog.51cto.com
- * Weibo: http://weibo.com/zhoufoxcn
- */
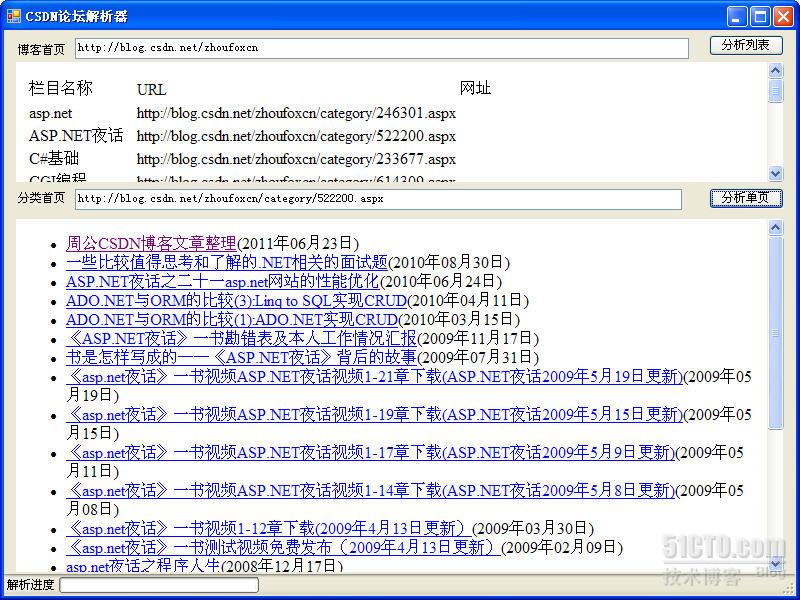
- public class CSDN_Parser
- {
- private const string CategoryListXPath = "//html[1]/body[1]/div[1]/div[1]/div[2]/div[1]/div[1]/dl[1]/dd[3]/div[1]/ul[1]/li";
- private const string CategoryNameXPath = "//li[1]/a[2]";
- /// <summary>
- /// 分析博客首页
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory=null;
- List<Category> list = new List<Category>(40);
- HtmlDocument document = new HtmlDocument();
- //注意,这里省略掉了使用本人其它类库中加载URL的类,而是直接加载本地的HTML文件
- //string html = HttpWebUtility.ReadFromUrl(url, Encoding.UTF8);
- //document.LoadHtml(html);
- document.Load("CSDN_index.html", Encoding.UTF8);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat=category.IndexUrl+"?PageNumber={0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- return list;
- }
- }
- }
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
- namespace CrawlPageApplication
- {
- /**
- * 作者:周公
- * 日期:2011-06-23
- * Blog: http://blog.csdn.net/zhoufoxcn or http://zhoufoxcn.blog.51cto.com
- * Weibo: http://weibo.com/zhoufoxcn
- */
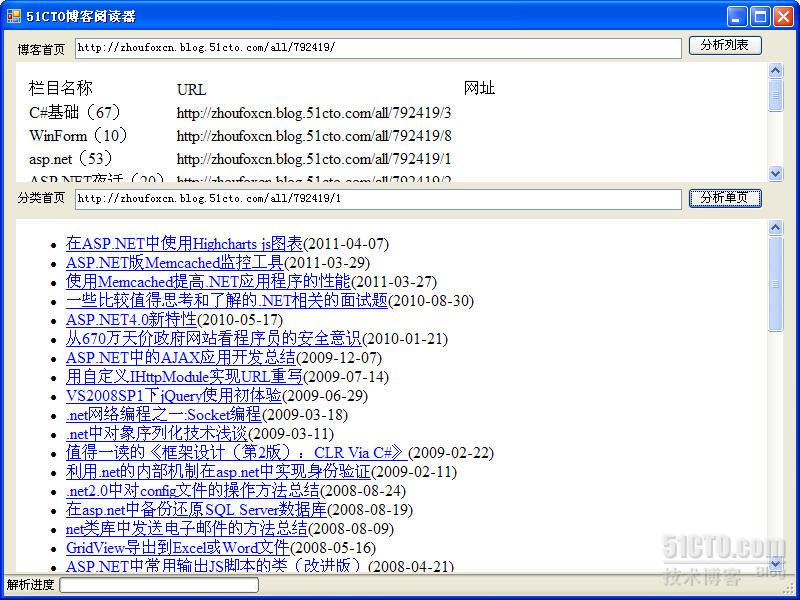
- public class CTO_Parser
- {
- private static Encoding PageEncoding = Encoding.GetEncoding("gb2312");
- private static readonly Uri UriBase = new Uri("http://zhoufoxcn.blog.51cto.com");
- private static string CategoryListXPath = "/html[1]/body[1]/div[5]/div[1]/div[1]/div[2]/ul[1]/li";
- private static string CategoryNameXPath = "/li[1]/a[1]";
- /// <summary>
- /// 分析博客首页
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory = null;
- List<Category> list = new List<Category>(40);
- HtmlDocument document = new HtmlDocument();
- //string html = HttpWebUtility.ReadFromUrl(url, PageEncoding);
- //document.LoadHtml(html);
- document.Load("51cto_index.html", PageEncoding);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- if (temp.SelectSingleNode(CategoryNameXPath).InnerText != "全部文章")
- {
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat = category.IndexUrl + "/page/{0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- }
- return list;
- }
- }
- }
0 0
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HTML解析利器HtmlAgilityPack
- HtmlAgilityPack 解析HTML利器
- C# HTML解析利器HtmlAgilityPack
- C#之HTML解析利器HtmlAgilityPack类库
- HTML解析利器HtmlAgilityPack - 小y
- c#蜘蛛程序之HTML解析利器HtmlAgilityPack
- c#蜘蛛程序之HTML解析利器HtmlAgilityPack
- htmlagilitypack解析Html
- Android 扫描音乐文件、两种方式获取文件最新修改时间
- 黑马程序员一集合中遍历元素的三种方法
- ORACLE PL/SQL编程之六:把过程与函数说透
- IIS的https协议绑定操作的一个报错
- C++中的 template 类使用
- HTML解析利器HtmlAgilityPack
- Spring MVC简介
- 文件属性
- su - oracle和su oracle的区别
- 预防用户流失哪家强?Testin崩溃分析秒杀Flurry
- C#实现整型数据字任意编码任意进制的转换和逆转换简介
- javascript事件处理中Event对象(键盘事件和鼠标事件)实例
- 安波_多智能体系统研究进展与挑战
- [DP]Longest Increasing Subsequence


