降维概述(I)
来源:互联网 发布:房源中介系统源码 编辑:程序博客网 时间:2024/04/27 21:42
在现实世界中,很多事物被表示为高维数据——如语音信号,图像,视频,文本文档,手写字母或数字,指纹和高光谱图像等。 我们通常需要分析和处理大量的数据,For instance, 我们需要鉴别person‘s fingerprint, 通过keyword在网络中搜索文档,去发现图像中某些潜在的模式,从视频中跟踪物体等等。 To complete these tasks, we develop systems to process data。 但是,由于数据分布在高维,直接处理会非常复杂和不稳定,以至于 infeasible. 实际上,很多systems只在低维空间中有效。当数据的维度超过了系统处理的限度,数据将无法被处理。因此,为了在这些systems中处理高维数据,必须对数据降维。
降维的典型事件:
- Fingerprint identification 指纹识别
- Face recognition
- Hyperspectral image analysis/processing 高光谱图像分析/处理
- Text document classification/search
- Data visualization
- Data feature extraction数据特征提取

High Dimension Data Acquisition 高维数据采集
Collection of Images in Face Recognition
人脸识别算法基于面部表情数据集(facial databases),一个典型的facial databases包含大量来自不同人的facial images,每个人的图像可能处于不同的光照条件,不同的姿态,表情以及不同的年龄。在一个数据集中,所有的图像大小(size)或者说是分辨率(resolution)相同。下图给出了从一个facial databases数据集中提取的部分图像,这些图像可以在www.cs.nyu.edu/˜roweis/data.html中下载:

通常,facial images可以是灰度图或者是彩色图。在DR中,将每一个facial images转换为一个向量。例如,每一个灰度图像的resolution是 N = m x n; 在可以把它拉成一个N维的向量。每个彩色图像可以转换为一个N = m x n x 3 维的向量(彩色图像有R,G,B三个通道)。因此,一个有k张图像的数据集可以表示为
数据集
Handwriting Letters and Digits
手写数字和字母转换成向量的方法和人脸图像类似。在手写数字和手写字母的原始图像中,背景用二值数字1表示,字母和数字的部分是0,为了得到稀疏的表示,在转换成二值向量的过程中,0和1互换,因此,一个手写数字或字母的图像转换成一个N维空间中的向量集合。下图是手写数字图像,背景值为0.

在处理时,一个集合通常表示为一个N x k的矩阵,每一列表示一副图像,k是图像的个数。类似于人脸图像,有两个主要的处理任务:识别和分类。通过两个参数分类这样一个集合,我们将其降到两维,而在识别中,我们要将这些数字图像从k维降到s维。
Text Documents
关键字查找是网上的一种常见的搜索方式,为了从搜索结果中分类文档,通常将一个文档转换成一个词项--词频(term-frequency)向量,首先,创建一个关键字字典(keyword dictionary),包含n个关键字。计算每个文档中关键字出现的次数,为文档创建一个n维的term-frequency向量。During the vector conversion for a set of documents, we deploy a few filtering methods to omit empty documents, remove common terms, and sometimes stem the vocabulary.(数据集构建过程中的处理方法)For example, the toolkit developed by McCallum [2] can remove the common terms, and the algorithm developed by Porter [3] can be used to stem vocabulary (处理工具). Each document vector is then normalized(正则化处理)to a unit vector before further processing. The text document data of four newsgroups(新闻数据集展示): sci.crypt, sci.med, sci. space, and soc.religion.christian, and the data Reuters-21578: Text Categorization Test Collection Distribution 1.0 can be obtained from www.daviddlewis.com/resources/testcollections/reuters21578/.
Hyperspectral Images
高光谱图像通过高光谱传感器获取,收集地理/地质geological/geographical图像数据作为一系列相同场景图像的集合, 每一副图像表示5-10 nm (nanometers)的电磁波谱的一个范围(also called spectral band光谱带),通常,一个高光谱图像的集合包含成百个范围between 350 nm and 3500 nm的电磁波谱的窄小的spectral band。Hyperspectral images 通常形成一个三维的高光谱图像的立方体(or HSI cube) 用于图像处理和分析。如下图:

令




一个物体的材质在raster cell中可以通过它的spectral curves识别出来。高光谱传感器扫描的一个空间域
典型的hyperspectral sensors的精确度测量有两种方法。光谱分辨率(which is the width of each band of the captured spectrum)和空间分辨率(which is the size of a raster in an HSI)。因为高光谱传感器能够收集大量非常窄的波段,这使得我们可以识别物体及时只捕获了一小部分像素。spatial resolution contributes to the effectiveness of spectral resolution,这一点很重要。例如,如果空间分辨率很低,多个物体被捕获到一个栅格里面,使得识别物体非常困难。另一方面,如果一个像素覆盖的区域太小,传感器捕获的能量太低使得信噪比(signal-to-noise ratio)过高而不能保持特征的可信度。为了获得高空间分辨率的图像高分辨率(HRI)的黑白或彩色相机被整合到HRI系统中。没有加入HRI的高光谱传感器只能捕获每像素一平方米的图像,而加入HRI的HSI传感器能捕获每平方英寸一像素的图像。
一些HSI数据是免费的,free HSI data的网站有:
- Jet Propulsion Laboratory, California Institute of Technology: aviris.jpl.nasa.gov/html/data.html
- L. Biehl: https://engineering.purdue.edu/∼biehl/MultiSpec/hyperspectral.html (Purdue University)
- Army Geospatial Center: www.agc.army.mil/Hypercube
 ,亦可以被认为是不同波段图像的集合
,亦可以被认为是不同波段图像的集合 ,这取决于图像处理的目标。
,这取决于图像处理的目标。Curse of the Dimensionality维度灾难
Volume of Cubes and Spheres 立方体和球体体积
当一个度量,如欧几里德距离使用很多坐标来定义时,不同的样本对之间的距离已经基本上没有差别。
一种用来描述高维欧几里德空间的巨型性的方法是将超球体中半径 和维数
和维数 的比例,和超立方体中边长
的比例,和超立方体中边长 和等值维数的比例相比较。 这样一个球体的体积计算如下:
和等值维数的比例相比较。 这样一个球体的体积计算如下: 
立方体的体积计算如下: 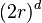
随着空间维度的增加,相对于超立方体的体积来说,超球体的体积就变得微不足道了。这一点可以从当趋于无穷时比较前面的比例清楚地看出: 
当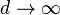 。 因此,在某种意义上,几乎所有的高维空间都远离其中心,或者从另一个角度来看,高维单元空间可以说是几乎完全由超立方体的“边角”所组成的,没有“中部”,这对于理解卡方分布是很重要的直觉理解。 给定一个单一分布,由于其最小值和最大值与最小值相比收敛于0,因此,其最小值和最大值的距离变得不可辨别。
。 因此,在某种意义上,几乎所有的高维空间都远离其中心,或者从另一个角度来看,高维单元空间可以说是几乎完全由超立方体的“边角”所组成的,没有“中部”,这对于理解卡方分布是很重要的直觉理解。 给定一个单一分布,由于其最小值和最大值与最小值相比收敛于0,因此,其最小值和最大值的距离变得不可辨别。 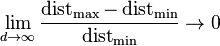 .
.
这通常被引证为距离函数在高维环境下失去其意义的例子。
- 降维概述(I)
- I 概述
- Java I/O (第二版) I/O基础 I/O概述
- I/O模式概述
- I:OAuth 2.0 概述
- I/O概述
- I/O模型概述
- Java I/O : 概述
- Java I/O 概述
- I/O多路复用概述
- Java I/O 技术(一)—— 概述
- 802.11i认证机制概述
- 典型分布式文件系统概述I
- 802.11i认证机制概述
- 802.11i认证机制概述
- java--I/O流概述
- C++ I/O库概述
- I/O概述及其分类
- checkbox 单选
- 动态加载dll
- android电池(四):电池 电量计(MAX17040)驱动分析篇
- 简单复数计算
- 谁脱了物联网的安全外衣?
- 降维概述(I)
- ubuntu 7ZIP 压缩和解压缩
- DKTabPageViewController
- 九度OJ 1174 查找第K小数 (STL)
- 八个炫酷的html5例子
- 从 Java 代码到 Java 堆
- Java父、子类成员变量和方法的调用关系
- android电池(五):电池 充电IC(PM2301)驱动分析篇
- 数据库笔记(三)


