非线性最优化(二)——高斯牛顿法和Levengerg-Marquardt迭代
来源:互联网 发布:遍历json数组 编辑:程序博客网 时间:2024/04/30 11:50
高斯牛顿法和Levengerg-Marquardt迭代都用来解决非线性最小二乘问题(nonlinear least square)。
From Wiki
The Gauss–Newton algorithm is a method used to solve non-linear least squares problems. It is a modification of Newton's method for finding a minimum of a function. Unlike Newton's method, the Gauss–Newton algorithm can only be used to minimize a sum of squared function values, but it has the advantage that second derivatives, which can be challenging to compute, are not required.
Description
Given m functions r = (r1, …, rm) of n variables β = (β1, …, βn), with m ≥ n, the Gauss–Newton algorithm iteratively finds the minimum of the sum of squares
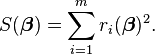
Starting with an initial guess 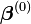 for the minimum, the method proceeds by the iterations
for the minimum, the method proceeds by the iterations
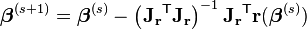
where, if r and β are column vectors, the entries of the Jacobian matrix are

and the symbol 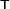 denotes the matrix transpose.
denotes the matrix transpose.
If m = n, the iteration simplifies to

which is a direct generalization of Newton's method in one dimension.
In data fitting, where the goal is to find the parameters β such that a given model function y = f(x, β) best fits some data points (xi, yi), the functions riare the residuals
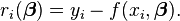
Then, the Gauss-Newton method can be expressed in terms of the Jacobian Jf of the function f as

Notes
The assumption m ≥ n in the algorithm statement is necessary, as otherwise the matrix JrTJr is not invertible (rank(JrTJr)=rank(Jr))and the normal equations (Δ in the "derivation from Newton's method" part) cannot be solved (at least uniquely).
The Gauss–Newton algorithm can be derived by linearly approximating the vector of functions ri. Using Taylor's theorem, we can write at every iteration:

with  The task of finding Δ minimizing the sum of squares of the right-hand side, i.e.,
The task of finding Δ minimizing the sum of squares of the right-hand side, i.e.,
 ,
,
is a linear least squares problem, which can be solved explicitly, yielding the normal equations in the algorithm.
The normal equations are m linear simultaneous equations in the unknown increments, Δ. They may be solved in one step, using Cholesky decomposition, or, better, the QR factorization of Jr. For large systems, an iterative method, such as the conjugate gradient method, may be more efficient. If there is a linear dependence between columns of Jr, the iterations will fail as JrTJr becomes singular.
In what follows, the Gauss–Newton algorithm will be derived from Newton's method for function optimization via an approximation. As a consequence, the rate of convergence of the Gauss–Newton algorithm can be quadratic under certain regularity conditions. In general (under weaker conditions), the convergence rate is linear.
The recurrence relation for Newton's method for minimizing a function S of parameters, 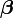 , is
, is

where g denotes the gradient vector of S and H denotes the Hessian matrix of S. Since  , the gradient is given by
, the gradient is given by

Elements of the Hessian are calculated by differentiating the gradient elements,  , with respect to
, with respect to 

The Gauss–Newton method is obtained by ignoring the second-order derivative terms (the second term in this expression). That is, the Hessian is approximated by

where  are entries of the Jacobian Jr. The gradient and the approximate Hessian can be written in matrix notation as
are entries of the Jacobian Jr. The gradient and the approximate Hessian can be written in matrix notation as

These expressions are substituted into the recurrence relation above to obtain the operational equations
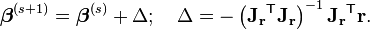
Convergence of the Gauss–Newton method is not guaranteed in all instances. The approximation

that needs to hold to be able to ignore the second-order derivative terms may be valid in two cases, for which convergence is to be expected.
- The function values
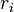 are small in magnitude, at least around the minimum.
are small in magnitude, at least around the minimum. - The functions are only "mildly" non linear, so that
 is relatively small in magnitude.
is relatively small in magnitude.
Improved version
With the Gauss–Newton method the sum of squares S may not decrease at every iteration. However, since Δ is a descent direction, unless  is a stationary point, it holds that
is a stationary point, it holds that 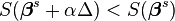 for all sufficiently small
for all sufficiently small 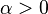 . Thus, if divergence occurs, one solution is to employ a fraction,
. Thus, if divergence occurs, one solution is to employ a fraction,  , of the increment vector, Δ in the updating formula
, of the increment vector, Δ in the updating formula
 .
.
In other words, the increment vector is too long, but it points in "downhill", so going just a part of the way will decrease the objective function S. An optimal value for can be found by using a line search algorithm, that is, the magnitude of is determined by finding the value that minimizes S, usually using a direct search method in the interval  .
.
In cases where the direction of the shift vector is such that the optimal fraction, , is close to zero, an alternative method for handling divergence is the use of the Levenberg–Marquardt algorithm, also known as the "trust region method".[1] The normal equations are modified in such a way that the increment vector is rotated towards the direction of steepest descent,
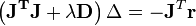 ,
,
where D is a positive diagonal matrix. Note that when D is the identity matrix and  , then
, then  , therefore the direction of Δ approaches the direction of the negative gradient
, therefore the direction of Δ approaches the direction of the negative gradient  .
.
The so-called Marquardt parameter,  , may also be optimized by a line search, but this is inefficient as the shift vector must be re-calculated every time is changed. A more efficient strategy is this. When divergence occurs increase the Marquardt parameter until there is a decrease in S. Then, retain the value from one iteration to the next, but decrease it if possible until a cut-off value is reached when the Marquardt parameter can be set to zero; the minimization of S then becomes a standard Gauss–Newton minimization.
, may also be optimized by a line search, but this is inefficient as the shift vector must be re-calculated every time is changed. A more efficient strategy is this. When divergence occurs increase the Marquardt parameter until there is a decrease in S. Then, retain the value from one iteration to the next, but decrease it if possible until a cut-off value is reached when the Marquardt parameter can be set to zero; the minimization of S then becomes a standard Gauss–Newton minimization.
The (non-negative) damping factor, , is adjusted at each iteration. If reduction of S is rapid, a smaller value can be used, bringing the algorithm closer to the Gauss–Newton algorithm, whereas if an iteration gives insufficient reduction in the residual, can be increased, giving a step closer to the gradient descent direction. Note that the gradient of S with respect to δ equals ![-2(\mathbf{J}^{T} [\mathbf{y} - \mathbf{f}(\boldsymbol \beta) ] )^T](http://upload.wikimedia.org/math/2/a/7/2a7d1cf3c310d2758322acf24c414974.png) . Therefore, for large values of , the step will be taken approximately in the direction of the gradient. If either the length of the calculated step, δ, or the reduction of sum of squares from the latest parameter vector, β + δ, fall below predefined limits, iteration stops and the last parameter vector, β, is considered to be the solution.
. Therefore, for large values of , the step will be taken approximately in the direction of the gradient. If either the length of the calculated step, δ, or the reduction of sum of squares from the latest parameter vector, β + δ, fall below predefined limits, iteration stops and the last parameter vector, β, is considered to be the solution.
Levenberg's algorithm has the disadvantage that if the value of damping factor, , is large, inverting JTJ + I is not used at all. Marquardt provided the insight that we can scale each component of the gradient according to the curvature so that there is larger movement along the directions where the gradient is smaller. This avoids slow convergence in the direction of small gradient. Therefore, Marquardt replaced the identity matrix, I, with the diagonal matrix consisting of the diagonal elements of JTJ, resulting in the Levenberg–Marquardt algorithm:
![\mathbf{(J^T J + \lambda\, diag(J^T J))\boldsymbol \delta = J^T [y - f(\boldsymbol \beta)]}\!](http://upload.wikimedia.org/math/8/e/2/8e230288240a69eecc8ba3e331e6add0.png) .
.
Related algorithms
In a quasi-Newton method, such as that due to Davidon, Fletcher and Powell or Broyden–Fletcher–Goldfarb–Shanno (BFGS method) an estimate of the full Hessian, , is built up numerically using first derivatives
, is built up numerically using first derivatives 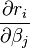 only so that after n refinement cycles the method closely approximates to Newton's method in performance. Note that quasi-Newton methods can minimize general real-valued functions, whereas Gauss-Newton, Levenberg-Marquardt, etc. fits only to nonlinear least-squares problems.
only so that after n refinement cycles the method closely approximates to Newton's method in performance. Note that quasi-Newton methods can minimize general real-valued functions, whereas Gauss-Newton, Levenberg-Marquardt, etc. fits only to nonlinear least-squares problems.
Another method for solving minimization problems using only first derivatives is gradient descent. However, this method does not take into account the second derivatives even approximately. Consequently, it is highly inefficient for many functions, especially if the parameters have strong interactions.
- 非线性最优化(二)——高斯牛顿法和Levengerg-Marquardt迭代
- 迭代求解最优化问题——最小二乘问题、高斯牛顿法
- 最优化学习笔记(七)——Levenberg-Marquardt修正(牛顿法修正)
- 非线性最优化(一)——牛顿迭代法
- 高斯牛顿迭代求解非线性回归问题
- 高斯牛顿(Gauss Newton)、列文伯格-马夸尔特(Levenberg-Marquardt)最优化算法与VSLAM
- 高斯牛顿(Gauss Newton)、列文伯格-马夸尔特(Levenberg-Marquardt)最优化算法与VSLAM
- 非线性优化之牛顿(梯度)下降法、高斯牛顿法、LM下降法
- 二分逼近/牛顿迭代——一元高次非线性方程求解
- 漫步最优化三十四——高斯-牛顿法
- 回归--非线性最小二乘-高斯牛顿法
- 非线性最优化(三)——拟牛顿迭代法(Quasi-Newton)
- 迭代求解最优化问题——梯度下降、牛顿法
- 【math】梯度下降法(梯度下降法,牛顿法,高斯牛顿法,Levenberg-Marquardt算法)
- 牛顿法、梯度下降法、高斯牛顿法、Levenberg-Marquardt算法
- 牛顿迭代优化
- 迭代和非线性
- 高斯牛顿和LM 优化原理
- framebuffer的结构介绍和驱动分析
- 深入理解C语言指针的奥秘
- c语言静态变量和静态函数
- windows环境下wampserver环境搭建
- PullToRefreshView下拉刷新上来加载更多,支持任何子view!
- 非线性最优化(二)——高斯牛顿法和Levengerg-Marquardt迭代
- Cython基础--Cython入门
- 简明 Vim 练级攻略(by陈皓)
- MFC 会员管理的一些笔记
- ORACLE解决锁表问题
- 可重入函数与不可重入函数
- 同步复位与异步复位
- uC/OS-II时间控制块1
- uC/OS-II事件控制块2


