WEKA——数据准备
来源:互联网 发布:js多个请求 编辑:程序博客网 时间:2024/05/16 11:02
使用WEKA作数据挖掘,面临的第一个问题往往是我们的数据不是ARFF格式的。幸好,WEKA还提供了对CSV文件的支持,而这种格式是被很多其他软件所支持的。此外,WEKA还提供了通过JDBC访问数据库的功能。
.* -> .csv
我们给出一个CSV文件的例子(bank-data.csv)。用UltraEdit打开它可以看到,这种格式也是一种逗号分割数据的文本文件,储存了一个二维表格。
Excel的XLS文件可以让多个二维表格放到不同的工作表(Sheet)中,我们只能把每个工作表存成不同的CSV文件。打开一个XLS文件并切换到需要转换的工作表,另存为CSV类型,点“确定”、“是”忽略提示即可完成操作。
在Matlab中的二维表格是一个矩阵,我们通过这条命令把一个矩阵存成CSV格式。
csvwrite('filename',matrixname)
需要注意的是,Matllab给出的CSV文件往往没有属性名(Excel给出的也有可能没有)。而WEKA必须从CSV文件的第一行读取属性名,否则就会把第一行的各属性值读成变量名。因此我们对于Matllab给出的CSV文件需要用UltraEdit打开,手工添加一行属性名。注意属性名的个数要跟数据属性的个数一致,仍用逗号隔开。
.csv -> .arff
将CSV转换为ARFF最迅捷的办法是使用WEKA所带的命令行工具。
运行WEKA的主程序,出现GUI后可以点击下方按钮进入相应的模块。我们点击进入“Simple CLI”模块提供的命令行功能。在新窗口的最下方(上方是不能写字的)输入框写上
java weka.core.converters.CSVLoader filename.csv > filename.arff
即可完成转换。
在WEKA 3.5中提供了一个“Arff Viewer”模块,我们可以用它打开一个CSV文件将进行浏览,然后另存为ARFF文件。
进入“Exploer”模块,从上方的按钮中打开CSV文件然后另存为ARFF文件亦可。
“Exploer”界面
我们应该注意到,“Exploer”还提供了很多功能,实际上可以说这是WEKA使用最多的模块。现在我们先来熟悉它的界面,然后利用它对数据进行预处理。 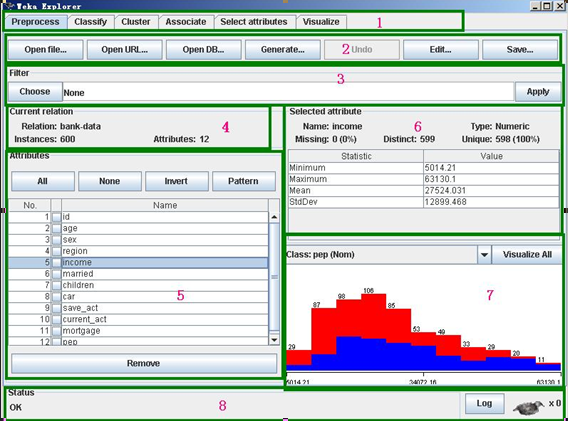
图2 新窗口打开
图2显示的是使用3.5版"Exploer"打开"bank-data.csv"的情况。我们根据不同的功能把这个界面分成8个区域。
区域1的几个选项卡是用来切换不同的挖掘任务面板。这一节用到的只有“Preprocess”,其他面板的功能将在以后介绍。
区域2是一些常用按钮。包括打开数据,保存及编辑功能。我们在这里把"bank-data.csv"另存为"bank-data.arff"。
在区域3中“Choose”某个“Filter”,可以实现筛选数据或者对数据进行某种变换。数据预处理主要就利用它来实现。
区域4展示了数据集的一些基本情况。
区域5中列出了数据集的所有属性。勾选一些属性并“Remove”就可以删除它们,删除后还可以利用区域2的“Undo”按钮找回。区域5上方的一排按钮是用来实现快速勾选的。
在区域5中选中某个属性,则区域6中有关于这个属性的摘要。注意对于数值属性和分类属性,摘要的方式是不一样的。图中显示的是对数值属性“income”的摘要。
区域7是区域5中选中属性的直方图。若数据集的最后一个属性(我们说过这是分类或回归任务的默认目标变量)是分类变量(这里的“pep”正好是),直方图中的每个长方形就会按照该变量的比例分成不同颜色的段。要想换个分段的依据,在区域7上方的下拉框中选个不同的分类属性就可以了。下拉框里选上“No Class”或者一个数值属性会变成黑白的直方图。
区域8是状态栏,可以查看Log以判断是否有错。右边的weka鸟在动的话说明WEKA正在执行挖掘任务。右键点击状态栏还可以执行JAVA内存的垃圾回收。
预处理
bank-data数据各属性的含义如下:
id a unique identification number
age age of customer in years (numeric)
sex MALE / FEMALE
region inner_city/rural/suburban/town
income income of customer (numeric)
married is the customer married (YES/NO)
children number of children (numeric)
car does the customer own a car (YES/NO)
save_acct does the customer have a saving account (YES/NO)
current_acct does the customer have a current account (YES/NO)
mortgage does the customer have a mortgage (YES/NO)
pep did the customer buy a PEP (Personal Equity Plan) after the last mailing (YES/NO)
通常对于数据挖掘任务来说,ID这样的信息是无用的,我们将之删除。在区域5勾选属性“id”,并点击“Remove”。将新的数据集保存一次,并用UltraEdit打开这个ARFF文件。我们发现,在属性声明部分,WEKA已经为每个属性选好了合适的类型。
我们知道,有些算法,只能处理所有的属性都是分类型的情况。这时候我们就需要对数值型的属性进行离散化。在这个数据集中有3个变量是数值型的,分别是“age”,“income”和“children”。
其中“children”只有4个取值:0,1,2,3。这时我们在UltraEdit中直接修改ARFF文件,把
@attribute children numeric
改为
@attribute children {0,1,2,3}
就可以了。
在“Explorer”中重新打开“bank-data.arff”,看看选中“children”属性后,区域6那里显示的“Type”是不是变成“Nominal”了?
“age”和“income”的离散化我们需要借助WEKA中名为“Discretize”的Filter来完成。在区域2中点“Choose”,出现一棵“Filter树”,逐级找到“weka.filters.unsupervised.attribute.Discretize”,点击。若无法关闭这个树,在树之外的地方点击“Explorer”面板即可。
现在“Choose”旁边的文本框应该显示“Discretize -B 10 -M -0.1 -R first-last”。 点击这个文本框会弹出新窗口以修改离散化的参数。
我们不打算对所有的属性离散化,只是针对对第1个和第4个属性(见区域5属性名左边的数字),故把attributeIndices右边改成“1,4”。计划把这两个属性都分成3段,于是把“bins”改成“3”。其它框里不用更改,关于它们的意思可以点“More”查看。点“OK”回到“Explorer”,可以看到“age”和“income”已经被离散化成分类型的属性。若想放弃离散化可以点区域2的“Undo”。
如果对“"(-inf-34.333333]"”这样晦涩的标识不满,我们可以用UltraEdit打开保存后的ARFF文件,把所有的“'\'(-inf-34.333333]\''”替换成“0_34”。其它标识做类似地手动替换。
经过上述操作得到的数据集我们保存为bank-data-final.arff。
----整理自http://maya.cs.depaul.edu/~classes/ect584/WEKA/preprocess.html
- WEKA——数据准备
- weka数据准备
- Weka数据挖掘——分类
- Weka数据挖掘——聚类
- Weka数据挖掘——关联
- Weka数据挖掘——选择属性
- 工程化机器学习数据挖掘系列——How to weka,weka环境安装步骤,weka编译步骤,weka运行用例
- 数据挖掘(Data Mining)——Pentaho Weka
- 数据挖掘(Data Mining)——Pentaho Weka
- 【分享】weka实验数据——bank-data
- 一个数据挖掘的开源工具——Weka
- 数据分类——weka的朴素贝叶斯分类器
- WEKA——数据挖掘与机器学习工具
- 个人推荐的Weka教程,包含了数据格式、数据准备、分类和聚类Demo
- 个人推荐的Weka教程,包含了数据格式、数据准备、分类和聚类Demo
- weka学习—解决导入weka中文乱码
- 数据库基础——数据准备
- ELM实验——数据准备
- 业界良心机构解密:90后更适合学网络营销的六大理由!
- 数据挖掘技术(五)——离群点检测
- socket编程实例
- 接入广告App 教你如何赚取你的第一桶金 - 2048(含源码)
- shiro安全框架扩展教程--整合cas框架扩展自定义CasRealm
- WEKA——数据准备
- 知识管理
- 多视点的数据表示
- Discuz!X3.2学习笔记(一)
- 新手入门使用git 简单使用 终端命令
- poj 2318
- moodle基本配置
- 动态链接时如何访问在其他模块中的全局变量
- 微信开发不用xstream来将对象解析成xml


