随机森林的视觉应用-Regression Forests (2)
来源:互联网 发布:雕刻机编程软件有几种 编辑:程序博客网 时间:2024/04/28 23:37
我个人觉得具有时代意义的文章是J. Gall的Hough Forests,regression forests这个概念已经很多年,但是近几年在视觉中应用的regression forests本质是HF。Gall原来在ETH Zürich Computer Vision Laboratory,即Luc Van Gool那,去年去了Max Planck Institute。HF的主要思想是将Random Forests和Hough Transform结合起来了,这个思想从某种意义上是受到了ISM的影响,其区别在于ISM采用传统的构件codebook的方法,而HF的codebook是根据random forests来构建的。到底是怎么样构建这个codebook的呢?即上文中我们讲到的卫兵和算命先生(内部节点和叶子节点)。这是random forests的精华,我们先来回顾一下。作为一篇具有research性质的blog,似乎很难避免用点数学描述,在此文中,我们用到一些简单的信息论的知识:Information Gain 和Entropy。他们在进行树的构建的过程中起到了非常重要的作用。我们用最简单的object detection为例还说明这个过程,训练的数据集与其它的object detection的方法无异。在一个图像中,有object的bounding box,bouding box被视为目标,而bounding box外即为background。HF训练的方法是在图像中随机的选择固定大小size的patch,从foreground和background上都会选择一些,这些训练的patch就会有一下特征 Pa = (I,offset,class). I是图像的feature,注意这些feature与SIFT与HoG之类的对histogram有区别,而是在每个像素位置都对应一个vector的feature,简单的理解,每一个像素点都有一个灰度值,这是最简单的feature特征,在实际的运用中, 会将一些高级的feature进行一定的改装,比如在Gall的原文就将HoG就行了一定的改装使得每一个像素点位置都有一个vector的特征表达。offset是这个patch到object center的偏移量,HF将这个引进来是成功的关键,也为最近几年的新型regression forests提供了基础。然后class就是这个patch到底属于背景还是前景。从所有的训练图像中提取若干的这样的patch后,训练准备工作就结束了,然后就开始了训练。
现在树还是空的,开始建第一个root节点。如前所述,每个节点就是一个split function, 最简单的形式就是选择两个像素位置,然后进行对比。这样一来,有以下问题:
1) 选哪两个位置
2) 如果有多维特征,比较哪一个特征
3) 比较的时候的阈值怎么设定
这些问题的答案很简单:try!
这是random forests的基本思想,位置随机产生一些pair,特征也random的选择一些出来,然后在特征的最大差和最小差之间随机的产生一下阈值。这样,三个随机就组合成了一个大的candidate的集合,每一个candidate都可以将当前的这些patch分为两个小的集合L和R。我们就需要衡量一下哪一个candidate最好,这就需要用到information gain了。但是在decision tree中的所谓的information gain其实不是真正意义上的Kullback-Leribler divergence,而是其估计值,即mutual information。既然大家都这么用了,也不深究了,如果想深究的人,特别是对信息论本身功力深厚的人可以去研究一下,说不定能整出点东西来。 我们这只关心这个mutual information怎么计算。公式如下:
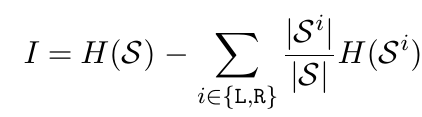
(p.s. i have no idea how to input equations in this blog so they will appear in terms of image)
这个公示应该一看就可以明白是什么意思,H(*)是Entropy,当前节点的entropy减去由某个candidate分成的两个set的entropy的和。当前节点的entropy肯定已经是个定值了,所以在实际的计算中直接省去,因为我们关注的是一个相对大小。关于Entropy的计算,那最常用的分类问题来讲就是p*\log(p)这种naive entropy方式计算。对于regression的问题,相对复杂一点。首先我们要做一个假设,比如假设这些局部数据是服从高斯分布的,然后通过高斯分布的协方差矩阵来计算连续型变量的entropy。听起来很复杂,在上文所述的tutorial中,也有很详尽的讨论。而我的直观理解是这样的,既然是服从高斯分布,那么最好的split就是把集中的东西分到一起,然后统计一下这些点的集中性,这当然也就是协方差的来源。在HF的文章中,其实就是统计的某个patch到平均offset的距离。HF的另外一个创新点就是在树的构建过程中,有的节点是做classification,有的节点在做regression的事,区别就在于entropy的计算方式。这样一来,一棵树会努力的将前景和背景分开,同时会将离object中心相似距离的patch分到一起。这个思想很nice,笔者根据这个思想进行了一点点的扩充,在2013的FG上写了一篇关于facial feature detection的文章,有兴趣的可以去读读。为了更直观的说明information gain的作用,下面有一个toy example:
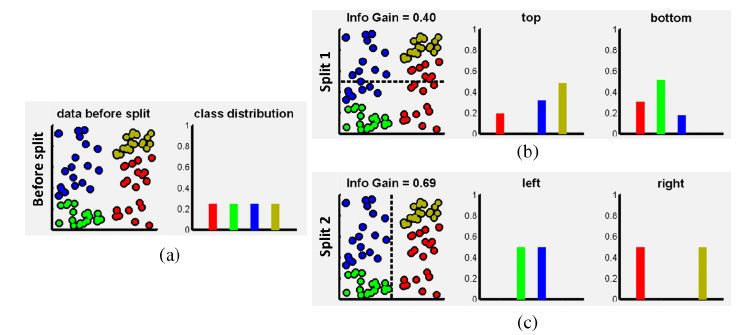
(a)中的数据有四类,均匀分布,然后split1 和split2是两个不同的split candidate,都是最简单的线性分类器,根据其info gain的值就知道split2的分类方式比split1的好。
如果是信息论的人应该知道,在info gain计算的过程中,对于entropy的估计是一个很有意思的课题。naive entropy在random forests中用了这么些年,一直没有人去质疑他,直到2012年的一篇ICML文章:
Sebastian Nowozin, "Improved Information Gain Estimates for Decision Tree Induction", (PDF,arXiv,video recording),29th International Conference on Machine Learning (ICML 2012).
作者也是微软剑桥的,他一个人写的。Nowozin很nice,我都了这篇文章后跟他讨论过一些细节。他回邮件很神速,也有可能是因为我们没有时差吧,还很幽默的跟我来了个Ni hao,可能是从我的英语水平或者名字判断是我是Chinese,后来的通信中一直用很多bukeqi之类的,然后我查看了一下,原来他在上海交大做过交换生,老婆应该也是个中国人,估计是交换时候的最大收获,呵呵。最近几年他发的文章都非常的不错,有晋升大牛人行列的潜质!在以上的文章中,他做了大量的实验,对不同的entropy estimators进行了比较,然后得出一个结论,其实有比naive entropy estimator好很多的estimator,所以希望大家能用!
言归正传,HF通过以上的方式将建立好树过后,所有的patch都到了leaf node,每一个patch都包含一个与center之间的offset的信息。所以在进行test的时候,patch从y0出来而来,根据test function一路向下,走到leaf node,发现很多的patch在那,每一个都有一个offset,进行一下vote,y=y0+offset。这样vote完过后,在object center的地方就会有个高峰。当然在实际的操作中,如果要进行多个scale的vote,training的patch还需要包含scale的信息。然后在每个scale得到一个voting map。最后就成了一个mode detection的问题。简单的meanshift 一下就出来了。所以,通过这样,HF就random forest和Hough voting就结合在了一起,就靠这个,连续发了n篇paper。
有个问题就是,如果将所有的training patch都存储起来,一是浪费存储空间,使得模型很big;二是不准确,因为有的patch就是些outier,不应该要。所以在后来的regression中,就在每个leaf node存一个模型,目前就两种简单的方式,一是learn一个简单的Gaussian model,vote的中心是Gaussian的mean value,weight由covariance matrix决定。在前面提到human pose estimation based on depth image中的系列文章中,除了那篇cvpr的best paper,后来的leaf node 的模型都是由mean shift聚类得到的某些,选取最大的1到2个类的中心作为vote的中心,weight是这个聚类的相对size大小。
就这样,random forests的regression方法在视觉领域得到了很多的应用,其中比较经典的文章,仍然出自于Gall的门生和微软剑桥视觉研究组。简单的罗列如下:
Fanelli G., Gall J., and van Gool L.,Real Time 3D Head Pose Estimation: Recent Achievements and Future Challenges (PDF,Images/Videos/Data/Code), 5th International Symposium on Communications, Control and Signal Processing (ISCCSP'12), 2012.©IEEE
Dantone M., Gall J., Fanelli G., and van Gool L.,Real-time Facial Feature Detection using Conditional Regression Forests (PDF,Images/Videos/Data/Code), IEEE Conference on Computer Vision and Pattern Recognition (CVPR'12), 2578-2585, 2012.©IEEE
Fanelli G., Dantone M., Gall J., Fossati A. and van
Gool L.,Random Forests for Real Time 3D Face Analysis (PDF,Images/Videos/Data/Code), International Journal of Computer Vision, Special Issue on Human Computer Interaction, Vol 101(3), 437-458, Springer, 2013.©Springer-Verlag
Ross Girshick, Jamie Shotton, Pushmeet Kohli, Antonio Criminisi, and Andrew Fitzgibbon, Efficient Regression of General-Activity Human Poses from Depth Images, inICCV, IEEE, October 2011.
小弟也发了有两篇regression forests在facial feature detection方面的拙作:
Heng Yang, Ioannis Patras, "Face Parts Localization Using Structured-output Regression Forests", ACCV2012, Dajeon, Korea.
Heng Yang, Ioannis Patras, " Privileged information-based Conditional Regression Forests for Facial Feature Detection", IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2013, Shanghai, China.
两篇文章的档次都在iccv和cvpr之下。当时是第一年,效率也低,觉得把regression forests用在facial feature detection上不错,就开始做,结果就在ACCV的前几周,发现CVPR出录取结果了,Gall的学生就做了这么一件事,幸好我们对regression forests都作了改进,并且属于两个不同方面的。总之呢,research的道路不简单,哪怕即使只是ACCV或者FG,如果做的问题是如我做的facial feature detection这样的几十年都老问题,要想有个paper,都得有所建树。
下一篇,我会将将2012年和2013年这两年中regression forests的一些改进,主要集中在三个方面:一是怎么加入结构信息,二是怎样进行更好的split,三是一些新的应用领域。
http://blog.sciencenet.cn/blog-941987-691570.html
- 随机森林的视觉应用-Regression Forests (2)
- 谈谈随机森林的视觉应用-Random Forests(1)
- Random forests, 随机森林,online random forests
- Random Forests (随机森林)
- Random Forests (随机森林)
- 随机森林(Random Forests)
- 【机器学习】Random Forests随机森林的基础及运用
- 随机森林——Random Forests
- 随机森林——Random Forests
- 随机森林——Random Forests
- 随机森林 计算机视觉应用医学图像处理应用
- 装袋法(bagging)和随机森林(random forests)的区别
- 分类和回归树,随机森林,霍夫森林(CART,random forests,hough forests)
- 分类和回归树,随机森林,霍夫森林(CART,random forests,hough forests)
- 分类和回归树,随机森林,霍夫森林(CART,random forests,hough forests)
- 分类和回归树,随机森林,霍夫森林(CART,random forests,hough forests)
- 分类和回归树,随机森林,霍夫森林(CART,random forests,hough forests)
- 计算机视觉:随机森林算法在人体识别中的应用
- EBCDIC 与 GBK 的字符编码及其转换(转)
- java中error和exception的区别
- 给VirtualBox上的Ubuntu虚机扩展硬盘空间
- 牛逼站是怎样炼成的?-推荐系统篇
- 在iOS上绘制自然的签名
- 随机森林的视觉应用-Regression Forests (2)
- 接入广告App 教你如何赚取你的第一桶金 - 2048(含源码)
- C# 安装程序制作,如何添加第三方DLL以及自定义的文件夹(如uploadFiles 文件夹)
- Could not write to output file 'c:\WINDOWS\Microsoft.NET\Framework\..dll-拒绝访问
- VLC源码分析二
- HDOJ 1053 Huffman编码 自写优先队列的ADT 权当做练习数据结构
- VS中的路径宏
- 写给喜欢数据分析的初学者
- iOS开发的一些奇巧淫技


