Lucene - Overview
来源:互联网 发布:php九九乘法表代码视频 编辑:程序博客网 时间:2024/06/05 18:24
Lucene is simple yet powerful java based search library. It can be used in any application to add search capability to it. Lucene is open-source project. It is scalable and high-performance library used to index and search virtually any kind of text. Lucene library provides the core operations which are required by any search application. Indexing and Searching.
How Search Application works?
Any search application does the few or all of the following operations.
Apart from these basic operations, search application can also provide administration user interface providing administrators of the application to control the level of search based on the user profiles. Analytics of search result is another important and advanced aspect of any search application.
Lucene's role in search application
Lucene plays role in steps 2 to step 7 mentioned above and provides classes to do the required operations. In nutshell, lucene works as a heart of any search application and provides the vital operations pertaining to indexing and searching. Acquiring contents and displaying the results is left for the application part to handle. Let's start with first simple search application using lucene search library in next chapter.
Lucene - Environment Setup
Environment Setup
This tutorial will guide you on how to prepare a development environment to start your work with Spring Framework. This tutorial will also teach you how to setup JDK, Tomcat and Eclipse on your machine before you setup Spring Framework:
Step 1 - Setup Java Development Kit (JDK):
You can download the latest version of SDK from Oracle's Java site: Java SE Downloads. You will find instructions for installing JDK in downloaded files, follow the given instructions to install and configure the setup. Finally set PATH and JAVA_HOME environment variables to refer to the directory that contains java and javac, typically java_install_dir/bin and java_install_dir respectively.
If you are running Windows and installed the JDK in C:\jdk1.6.0_15, you would have to put the following line in your C:\autoexec.bat file.
set PATH=C:\jdk1.6.0_15\bin;%PATH%set JAVA_HOME=C:\jdk1.6.0_15
Alternatively, on Windows NT/2000/XP, you could also right-click on My Computer, select Properties, then Advanced, then Environment Variables. Then, you would update the PATH value and press the OK button.
On Unix (Solaris, Linux, etc.), if the SDK is installed in /usr/local/jdk1.6.0_15 and you use the C shell, you would put the following into your .cshrc file.
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATHsetenv JAVA_HOME /usr/local/jdk1.6.0_15
Alternatively, if you use an Integrated Development Environment (IDE) like Borland JBuilder, Eclipse, IntelliJ IDEA, or Sun ONE Studio, compile and run a simple program to confirm that the IDE knows where you installed Java, otherwise do proper setup as given document of the IDE.
Step 2 - Setup Eclipse IDE
All the examples in this tutorial have been written using Eclipse IDE. So I would suggest you should have latest version of Eclipse installed on your machine.
To install Eclipse IDE, download the latest Eclipse binaries from http://www.eclipse.org/downloads/. Once you downloaded the installation, unpack the binary distribution into a convenient location. For example in C:\eclipse on windows, or /usr/local/eclipse on Linux/Unix and finally set PATH variable appropriately.
Eclipse can be started by executing the following commands on windows machine, or you can simply double click on eclipse.exe
%C:\eclipse\eclipse.exe
Eclipse can be started by executing the following commands on Unix (Solaris, Linux, etc.) machine:
$/usr/local/eclipse/eclipse
After a successful startup, if everything is fine then it should display following result:
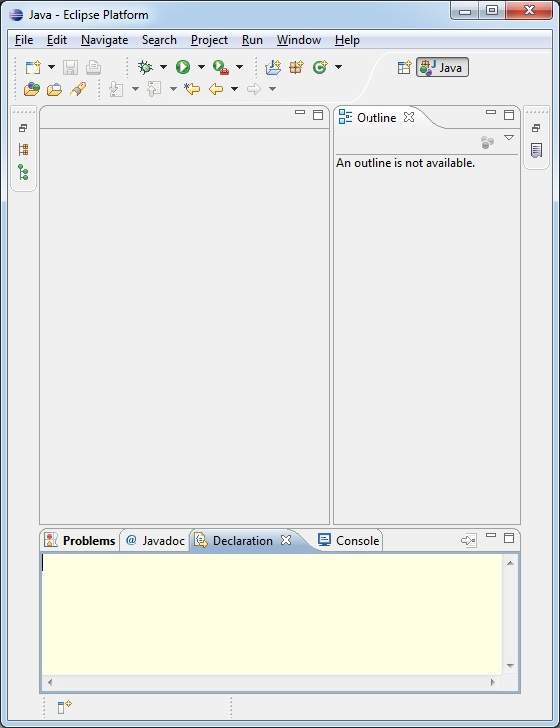
Step 3 - Setup Lucene Framework Libraries
Now if everything is fine, then you can proceed to setup your Lucene framework. Following are the simple steps to download and install the framework on your machine.
- http://archive.apache.org/dist/lucene/java/3.6.2/
Make a choice whether you want to install Lucene on Windows, or Unix and then proceed to the next step to download .zip file for windows and .tz file for Unix.
Download the suitable version of Lucene framework binaries fromhttp://archive.apache.org/dist/lucene/java/.
At the time of writing this tutorial, I downloaded lucene-3.6.2.zip on my Windows machine and when you unzip the downloaded file it will give you directory structure inside C:\lucene-3.6.2 as follows.
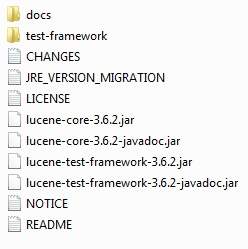
You will find all the Lucene libraries in the directory C:\lucene-3.6.2. Make sure you set your CLASSPATH variable on this directory properly otherwise you will face problem while running your application. If you are using Eclipse then it is not required to set CLASSPATH because all the setting will be done through Eclipse.
Once you are done with this last step, you are ready to proceed for your first Lucene Example which you will see in the next chapter.
Lucene - First Application
Let us start actual programming with Lucene Framework. Before you start writing your first example using Lucene framework, you have to make sure that you have setup your Lucene environment properly as explained in Lucene - Environment Setup tutorial. I also assume that you have a little bit working knowledge with Eclipse IDE.
So let us proceed to write a simple Search Application which will print number of search result found. We'll also see the list of indexes created during this process.
Step 1 - Create Java Project:
The first step is to create a simple Java Project using Eclipse IDE. Follow the option File -> New -> Project and finally select Java Project wizard from the wizard list. Now name your project asLuceneFirstApplication using the wizard window as follows:
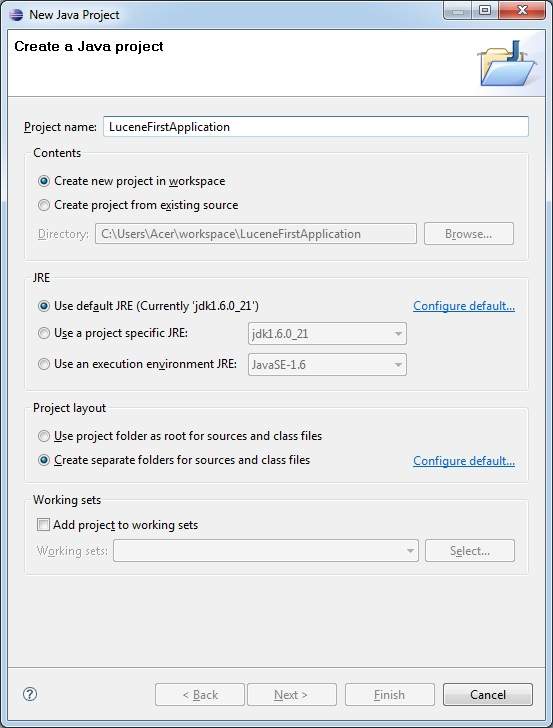
Once your project is created successfully, you will have following content in your Project Explorer:
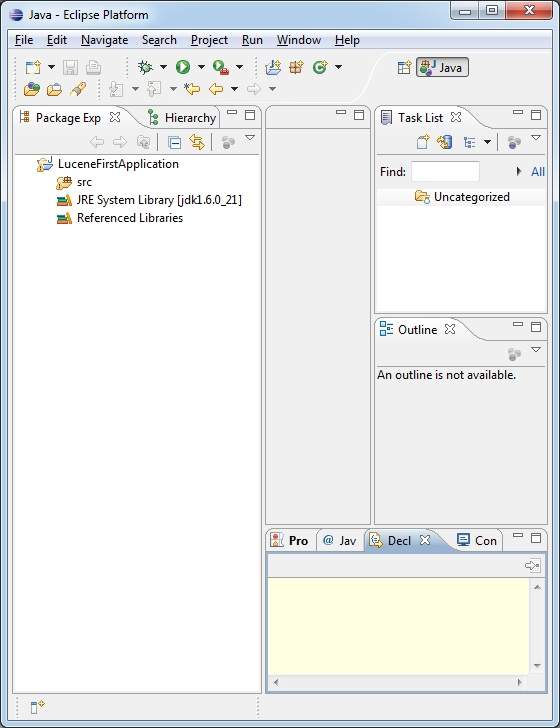
Step 2 - Add Required Libraries:
As a second step let us add Lucene core Framework library in our project. To do this, right click on your project name LuceneFirstApplication and then follow the following option available in context menu:Build Path -> Configure Build Path to display the Java Build Path window as follows:
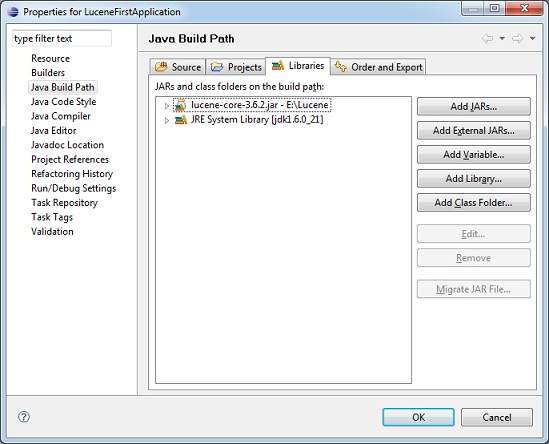
Now use Add External JARs button available under Libraries tab to add the following core JAR from Lucene installation directory:
lucene-core-3.6.2
Step 3 - Create Source Files:
Now let us create actual source files under the LuceneFirstApplication project. First we need to create a package called com.tutorialspoint.lucene. To do this, right click on src in package explorer section and follow the option : New -> Package.
Next we will create LuceneTester.java and other java classes under the com.tutorialspoint.lucene package.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
Searcher.java
This class is used to search the indexes created by Indexer to search the requested contents.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the indexing and search capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); } private void search(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime)); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: " + doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Step 4 - Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Step 5 - Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Indexing E:\Lucene\Data\record1.txtIndexing E:\Lucene\Data\record10.txtIndexing E:\Lucene\Data\record2.txtIndexing E:\Lucene\Data\record3.txtIndexing E:\Lucene\Data\record4.txtIndexing E:\Lucene\Data\record5.txtIndexing E:\Lucene\Data\record6.txtIndexing E:\Lucene\Data\record7.txtIndexing E:\Lucene\Data\record8.txtIndexing E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms1 documents found. Time :0File: E:\Lucene\Data\record4.txt
Once you've run the program successfully, you will have following content in your index directory:
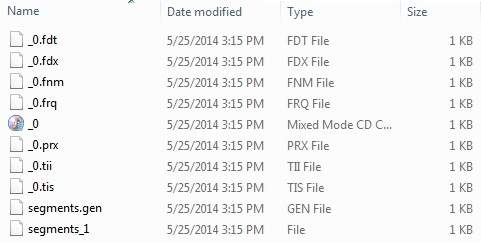
Lucene - Indexing Classes
Indexing process is one of the core functionality provided by Lucene. Following diagram illustrates the indexing process and use of classes. IndexWriter is the most important and core component of the indexing process.
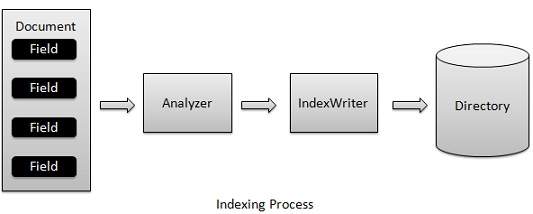
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using theAnalyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Indexing Classes:
Following is the list of commonly used classes during indexing process.
This class acts as a core component which creates/updates indexes during indexing process.2Directory
This class represents the storage location of the indexes.3Analyzer
Analyzer class is responsible to analyze a document and get the tokens/words from the text which is to be indexed. Without analysis done, IndexWriter can not create index.4Document
Document represents a virtual document with Fields where Field is object which can contain the physical document's contents, its meta data and so on. Analyzer can understand a Document only.5Field
Field is the lowest unit or the starting point of the indexing process. It represents the key value pair relationship where a key is used to identify the value to be indexed. Say a field used to represent contents of a document will have key as "contents" and the value may contain the part or all of the text or numeric content of the document. Lucene can index only text or numeric contents only.
Lucene - IndexWriter
Introduction
This class acts as a core component which creates/updates indexes during indexing process.
Class declaration
Following is the declaration for org.apache.lucene.index.IndexWriter class:
public class IndexWriter extends Object implements Closeable, TwoPhaseCommit
Field
Following are the fields for org.apache.lucene.index.IndexWriter class:
static int DEFAULT_MAX_BUFFERED_DELETE_TERMS -- Deprecated. use IndexWriterConfig.DEFAULT_MAX_BUFFERED_DELETE_TERMS instead.
static int DEFAULT_MAX_BUFFERED_DOCS -- Deprecated. Use IndexWriterConfig.DEFAULT_MAX_BUFFERED_DOCS instead.
static int DEFAULT_MAX_FIELD_LENGTH -- Deprecated. See IndexWriterConfig.
static double DEFAULT_RAM_BUFFER_SIZE_MB -- Deprecated. Use IndexWriterConfig.DEFAULT_RAM_BUFFER_SIZE_MB instead.
static int DEFAULT_TERM_INDEX_INTERVAL -- Deprecated. Use IndexWriterConfig.DEFAULT_TERM_INDEX_INTERVAL instead.
static int DISABLE_AUTO_FLUSH -- Deprecated. Use IndexWriterConfig.DISABLE_AUTO_FLUSH instead.
static int MAX_TERM_LENGTH -- Absolute hard maximum length for a term.
static String WRITE_LOCK_NAME -- Name of the write lock in the index.
static long WRITE_LOCK_TIMEOUT -- Deprecated. Use IndexWriterConfig.WRITE_LOCK_TIMEOUT instead.
Class constructors
Deprecated. use IndexWriter(Directory, IndexWriterConfig) instead.2IndexWriter(Directory d, Analyzer a, boolean create, IndexWriter.MaxFieldLength mfl)
Deprecated. use IndexWriter(Directory, IndexWriterConfig) instead.3IndexWriter(Directory d, Analyzer a, IndexDeletionPolicy deletionPolicy, IndexWriter.MaxFieldLength mfl)
Deprecated. use IndexWriter(Directory, IndexWriterConfig) instead.4IndexWriter(Directory d, Analyzer a, IndexDeletionPolicy deletionPolicy, IndexWriter.MaxFieldLength mfl, IndexCommit commit)
Deprecated. use IndexWriter(Directory, IndexWriterConfig) instead.5IndexWriter(Directory d, Analyzer a, IndexWriter.MaxFieldLength mfl)
Deprecated. use IndexWriter(Directory, IndexWriterConfig) instead.6IndexWriter(Directory d, IndexWriterConfig conf)
Constructs a new IndexWriter per the settings given in conf.
Class methods
Adds a document to this index.2void addDocument(Document doc, Analyzer analyzer)
Adds a document to this index, using the provided analyzer instead of the value of getAnalyzer().3void addDocuments(Collection<Document> docs)
Atomically adds a block of documents with sequentially assigned document IDs, such that an external reader will see all or none of the documents.4void addDocuments(Collection<Document> docs, Analyzer analyzer)
Atomically adds a block of documents, analyzed using the provided analyzer, with sequentially assigned document IDs, such that an external reader will see all or none of the documents.5void addIndexes(Directory... dirs)
Adds all segments from an array of indexes into this index.6void addIndexes(IndexReader... readers)
Merges the provided indexes into this index.7void addIndexesNoOptimize(Directory... dirs)
Deprecated.use addIndexes(Directory...) instead8void close()
Commits all changes to an index and closes all associated files.9void close(boolean waitForMerges)
Closes the index with or without waiting for currently running merges to finish.10void commit()
Commits all pending changes (added & deleted documents, segment merges, added indexes, etc.) to the index, and syncs all referenced index files, such that a reader will see the changes and the index updates will survive an OS or machine crash or power loss.11void commit(Map<String,String> commitUserData)
Commits all changes to the index, specifying a commitUserData Map (String -> String).12void deleteAll()
Delete all documents in the index.13void deleteDocuments(Query... queries)
Deletes the document(s) matching any of the provided queries.14void deleteDocuments(Query query)
Deletes the document(s) matching the provided query.15void deleteDocuments(Term... terms)
Deletes the document(s) containing any of the terms.16void deleteDocuments(Term term)
Deletes the document(s) containing term.17void deleteUnusedFiles()
Expert: remove any index files that are no longer used.18protected void doAfterFlush()
A hook for extending classes to execute operations after pending added and deleted documents have been flushed to the Directory but before the change is committed (new segments_N file written).19protected void doBeforeFlush()
A hook for extending classes to execute operations before pending added and deleted documents are flushed to the Directory.20protected void ensureOpen()
21protected void ensureOpen(boolean includePendingClose)
Used internally to throw an AlreadyClosedException if this IndexWriter has been closed.22void expungeDeletes()
Deprecated.23void expungeDeletes(boolean doWait)
Deprecated.24protected void flush(boolean triggerMerge, boolean applyAllDeletes)
Flush all in-memory buffered updates (adds and deletes) to the Directory.25protected void flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes)
NOTE: flushDocStores is ignored now (hardwired to true); this method is only here for backwards compatibility26void forceMerge(int maxNumSegments)
Forces merge policy to merge segments until there's <= maxNumSegments.27void forceMerge(int maxNumSegments, boolean doWait)
Just like forceMerge(int), except you can specify whether the call should block until all merging completes.28void forceMergeDeletes()
Forces merging of all segments that have deleted documents.29void forceMergeDeletes(boolean doWait)
Just like forceMergeDeletes(), except you can specify whether the call should block until the operation completes.30Analyzer getAnalyzer()
Returns the analyzer used by this index.31IndexWriterConfig getConfig()
Returns the private IndexWriterConfig, cloned from the IndexWriterConfig passed to IndexWriter(Directory, IndexWriterConfig).32static PrintStream getDefaultInfoStream()
Returns the current default infoStream for newly instantiated IndexWriters.33static long getDefaultWriteLockTimeout()
Deprecated.use IndexWriterConfig.getDefaultWriteLockTimeout() instead34Directory getDirectory()
Returns the Directory used by this index.35PrintStream getInfoStream()
Returns the current infoStream in use by this writer.36int getMaxBufferedDeleteTerms()
Deprecated.use IndexWriterConfig.getMaxBufferedDeleteTerms() instead37int getMaxBufferedDocs()
Deprecated.use IndexWriterConfig.getMaxBufferedDocs() instead.38int getMaxFieldLength()
Deprecated.use LimitTokenCountAnalyzer to limit number of tokens.39int getMaxMergeDocs()
Deprecated.use LogMergePolicy.getMaxMergeDocs() directly.40IndexWriter.IndexReaderWarmer getMergedSegmentWarmer()
Deprecated.use IndexWriterConfig.getMergedSegmentWarmer() instead.41int getMergeFactor()
Deprecated.use LogMergePolicy.getMergeFactor() directly.42MergePolicy getMergePolicy()
Deprecated.use IndexWriterConfig.getMergePolicy() instead43MergeScheduler getMergeScheduler()
Deprecated.use IndexWriterConfig.getMergeScheduler() instead44Collection<SegmentInfo> getMergingSegments()
Expert: to be used by a MergePolicy to a void selecting merges for segments already being merged.45MergePolicy.OneMerge getNextMerge()
Expert: the MergeScheduler calls this method to retrieve the next merge requested by the MergePolicy46PayloadProcessorProvider getPayloadProcessorProvider()
Returns the PayloadProcessorProvider that is used during segment merges to process payloads.47double getRAMBufferSizeMB()
Deprecated.use IndexWriterConfig.getRAMBufferSizeMB() instead.48IndexReader getReader()
Deprecated.Please use IndexReader.open(IndexWriter,boolean) instead.49IndexReader getReader(int termInfosIndexDivisor)
Deprecated.Please use IndexReader.open(IndexWriter,boolean) instead. Furthermore, this method cannot guarantee the reader (and its sub-readers) will be opened with the termInfosIndexDivisor setting because some of them may have already been opened according to IndexWriterConfig.setReaderTermsIndexDivisor(int). You should set the requested termInfosIndexDivisor through IndexWriterConfig.setReaderTermsIndexDivisor(int) and use getReader().50int getReaderTermsIndexDivisor()
Deprecated.use IndexWriterConfig.getReaderTermsIndexDivisor() instead.51Similarity getSimilarity()
Deprecated.use IndexWriterConfig.getSimilarity() instead52int getTermIndexInterval()
Deprecated.use IndexWriterConfig.getTermIndexInterval()53boolean getUseCompoundFile()
Deprecated.use LogMergePolicy.getUseCompoundFile()54long getWriteLockTimeout()
Deprecated.use IndexWriterConfig.getWriteLockTimeout()55boolean hasDeletions()
56static boolean isLocked(Directory directory)
Returns true iff the index in the named directory is currently locked.57int maxDoc()
Returns total number of docs in this index, including docs not yet flushed (still in the RAM buffer), not counting deletions.58void maybeMerge()
Expert: asks the mergePolicy whether any merges are necessary now and if so, runs the requested merges and then iterate (test again if merges are needed) until no more merges are returned by the mergePolicy.59void merge(MergePolicy.OneMerge merge)
Merges the indicated segments, replacing them in the stack with a single segment.60void message(String message)
Prints a message to the infoStream (if non-null), prefixed with the identifying information for this writer and the thread that's calling it.61int numDeletedDocs(SegmentInfo info)
Obtain the number of deleted docs for a pooled reader.62int numDocs()
Returns total number of docs in this index, including docs not yet flushed (still in the RAM buffer), and including deletions.63int numRamDocs()
Expert: Return the number of documents currently buffered in RAM.64void optimize()
Deprecated.65void optimize(boolean doWait)
Deprecated.66void optimize(int maxNumSegments)
Deprecated.67void prepareCommit()
Expert: prepare for commit.68void prepareCommit(Map<String,String> commitUserData)
Expert: prepare for commit, specifying commitUserData Map (String -> String).69long ramSizeInBytes()
Expert: Return the total size of all index files currently cached in memory.70void rollback()
Close the IndexWriter without committing any changes that have occurred since the last commit (or since it was opened, if commit hasn't been called).71String segString()
72String segString(Iterable<SegmentInfo> infos)
73String segString(SegmentInfo info)
74static void setDefaultInfoStream(PrintStream infoStream)
If non-null, this will be the default infoStream used by a newly instantiated IndexWriter.75static void setDefaultWriteLockTimeout(long writeLockTimeout)
Deprecated.use IndexWriterConfig.setDefaultWriteLockTimeout(long) instead76void setInfoStream(PrintStream infoStream)
If non-null, information about merges, deletes and a message when maxFieldLength is reached will be printed to this.77void setMaxBufferedDeleteTerms(int maxBufferedDeleteTerms)
Deprecated.use IndexWriterConfig.setMaxBufferedDeleteTerms(int) instead.78void setMaxBufferedDocs(int maxBufferedDocs)
Deprecated.use IndexWriterConfig.setMaxBufferedDocs(int) instead.79void setMaxFieldLength(int maxFieldLength)
Deprecated.use LimitTokenCountAnalyzer instead. Note that the behvaior slightly changed - the analyzer limits the number of tokens per token stream created, while this setting limits the total number of tokens to index. This only matters if you index many multi-valued fields though.80void setMaxMergeDocs(int maxMergeDocs)
Deprecated.use LogMergePolicy.setMaxMergeDocs(int) directly.81void setMergedSegmentWarmer(IndexWriter.IndexReaderWarmer warmer)
Deprecated.use IndexWriterConfig.setMergedSegmentWarmer( org.apache.lucene.index.IndexWriter.IndexReaderWarmer ) instead.82void setMergeFactor(int mergeFactor)
Deprecated.use LogMergePolicy.setMergeFactor(int) directly.83void setMergePolicy(MergePolicy mp)
Deprecated.use IndexWriterConfig.setMergePolicy(MergePolicy) instead.84void setMergeScheduler(MergeScheduler mergeScheduler)
Deprecated.use IndexWriterConfig.setMergeScheduler(MergeScheduler) instead85void setPayloadProcessorProvider(PayloadProcessorProvider pcp)
Sets the PayloadProcessorProvider to use when merging payloads.86void setRAMBufferSizeMB(double mb)
Deprecated.use IndexWriterConfig.setRAMBufferSizeMB(double) instead.87void setReaderTermsIndexDivisor(int divisor)
Deprecated.use IndexWriterConfig.setReaderTermsIndexDivisor(int) instead.88void setSimilarity(Similarity similarity)
Deprecated.use IndexWriterConfig.setSimilarity(Similarity) instead89void setTermIndexInterval(int interval)
Deprecated.use IndexWriterConfig.setTermIndexInterval(int)90void setUseCompoundFile(boolean value)
Deprecated.use LogMergePolicy.setUseCompoundFile(boolean).91void setWriteLockTimeout(long writeLockTimeout)
Deprecated.use IndexWriterConfig.setWriteLockTimeout(long) instead92static void unlock(Directory directory)
Forcibly unlocks the index in the named directory.93void updateDocument(Term term, Document doc)
Updates a document by first deleting the document(s) containing term and then adding the new document.94void updateDocument(Term term, Document doc, Analyzer analyzer)
Updates a document by first deleting the document(s) containing term and then adding the new document.95void updateDocuments(Term delTerm, Collection<Document> docs)
Atomically deletes documents matching the provided delTerm and adds a block of documents with sequentially assigned document IDs, such that an external reader will see all or none of the documents.96void updateDocuments(Term delTerm, Collection<Document> docs, Analyzer analyzer)
Atomically deletes documents matching the provided delTerm and adds a block of documents, analyzed using the provided analyzer, with sequentially assigned document IDs, such that an external reader will see all or none of the documents.97boolean verbose()
Returns true if verbosing is enabled (i.e., infoStream !98void waitForMerges()
Wait for any currently outstanding merges to finish.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Directory
Introduction
This class represents the storage location of the indexes and generally it is a list of files. These files are called index files. Index files are normally created once and then used for read operation or can be deleted.
Class declaration
Following is the declaration for org.apache.lucene.store.Directory class:
public abstract class Directory extends Object implements Closeable
Field
Following are the fields for org.apache.lucene.store.Directory class:
protected boolean isOpen
protected LockFactory lockFactory -- Holds the LockFactory instance (implements locking for this Directory instance).
Class constructors
Class methods
Attempt to clear (forcefully unlock and remove) the specified lock.2abstract void close()
Closes the store.3static void copy(Directory src, Directory dest, boolean closeDirSrc)
Deprecated. Should be replaced with calls to copy(Directory, String, String) for every file that needs copying. You can use the following code:
IndexFileNameFilter filter = IndexFileNameFilter.getFilter(); for (String file : src.listAll()) { if (filter.accept(null, file)) { src.copy(dest, file, file); } }4void copy(Directory to, String src, String dest)
Copies the file src to Directory to under the new file name dest.5abstract IndexOutput createOutput(String name)
Creates a new, empty file in the directory with the given name.6abstract void deleteFile(String name)
Removes an existing file in the directory.7protected void ensureOpen()
8abstract boolean fileExists(String name)
Returns true iff a file with the given name exists.9abstract long fileLength(String name)
Returns the length of a file in the directory.10abstract long fileModified(String name)
Deprecated.11LockFactory getLockFactory()
Get the LockFactory that this Directory instance is using for its locking implementation.12String getLockID()
Return a string identifier that uniquely differentiates this Directory instance from other Directory instances.13abstract String[] listAll()
Returns an array of strings, one for each file in the directory.14Lock makeLock(String name)
Construct a Lock.15abstract IndexInput openInput(String name)
Returns a stream reading an existing file.16IndexInput openInput(String name, int bufferSize)
Returns a stream reading an existing file, with the specified read buffer size.17void setLockFactory(LockFactory lockFactory)
Set the LockFactory that this Directory instance should use for its locking implementation.18void sync(Collection<String> names)
Ensure that any writes to these files are moved to stable storage.19void sync(String name)
Deprecated. use sync(Collection) instead. For easy migration you can change your code to call sync(Collections.singleton(name))20String toString()
21abstract void touchFile(String name)
Deprecated. Lucene never uses this API; it will be removed in 4.0.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Analyzer
Introduction
Analyzer class is responsible to analyze a document and get the tokens/words from the text which is to be indexed. Without analysis done, IndexWriter can not create index.
Class declaration
Following is the declaration for org.apache.lucene.analysis.Analyzer class:
public abstract class Analyzer extends Object implements Closeable
Class constructors
Class methods
Frees persistent resources used by this Analyzer2int getOffsetGap(Fieldable field)
Just like getPositionIncrementGap(java.lang.String), except for Token offsets instead.3int getPositionIncrementGap(String fieldName)
Invoked before indexing a Fieldable instance if terms have already been added to that field.4protected Object getPreviousTokenStream()
Used by Analyzers that implement reusableTokenStream to retrieve previously saved TokenStreams for re-use by the same thread.5TokenStream reusableTokenStream(String fieldName, Reader reader)
Creates a TokenStream that is allowed to be re-used from the previous time that the same thread called this method.6protected void setPreviousTokenStream(Object obj)
Used by Analyzers that implement reusableTokenStream to save a TokenStream for later re-use by the same thread.7abstract TokenStream tokenStream(String fieldName, Reader reader)
Creates a TokenStream which tokenizes all the text in the provided Reader.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Document
Introduction
Document represents a virtual document with Fields where Field is object which can contain the physical document's contents, its meta data and so on. Analyzer can understand a Document only.
Class declaration
Following is the declaration for org.apache.lucene.document.Document class:
public final class Document extends Object implements Serializable
Class constructors
Constructs a new document with no fields.
Class methods
Attempt to clear (forcefully unlock and remove) the specified lock.2void add(Fieldable field)
Adds a field to a document.3String get(String name)
Returns the string value of the field with the given name if any exist in this document, or null.4byte[] getBinaryValue(String name)
Returns an array of bytes for the first (or only) field that has the name specified as the method parameter.5byte[][] getBinaryValues(String name)
Returns an array of byte arrays for of the fields that have the name specified as the method parameter.6float getBoost()
Returns, at indexing time, the boost factor as set by setBoost(float).7Field getField(String name)
Deprecated. Use getFieldable(java.lang.String) instead and cast depending on data type.8Fieldable getFieldable(String name)
Returns a field with the given name if any exist in this document, or null.9Fieldable[] getFieldables(String name)
Returns an array of Fieldables with the given name.10List<Fieldable> getFields()
Returns a List of all the fields in a document.11Field[] getFields(String name)
Deprecated. Use getFieldable(java.lang.String) instead and cast depending on data type.12String[] getValues(String name)
Returns an array of values of the field specified as the method parameter.13void removeField(String name)
Removes field with the specified name from the document.14void removeFields(String name)
Removes all fields with the given name from the document.15void setBoost(float boost)
Sets a boost factor for hits on any field of this document.16String toString()
Prints the fields of a document for human consumption.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Field
Introduction
Field is the lowest unit or the starting point of the indexing process. It represents the key value pair relationship where a key is used to identify the value to be indexed. Say a field used to represent contents of a document will have key as "contents" and the value may contain the part or all of the text or numeric content of the document.
Lucene can index only text or numeric contents only.This class represents the storage location of the indexes and generally it is a list of files. These files are called index files. Index files are normally created once and then used for read operation or can be deleted.
Class declaration
Following is the declaration for org.apache.lucene.document.Field class:
public final class Field extends AbstractField implements Fieldable, Serializable
Class constructors
Create a field by specifying its name, value and how it will be saved in the index.2Field(String name, byte[] value)
Create a stored field with binary value.3Field(String name, byte[] value, Field.Store store)
Deprecated.4Field(String name, byte[] value, int offset, int length)
Create a stored field with binary value.5Field(String name, byte[] value, int offset, int length, Field.Store store)
Deprecated.6Field(String name, Reader reader)
Create a tokenized and indexed field that is not stored.7Field(String name, Reader reader, Field.TermVector termVector)
Create a tokenized and indexed field that is not stored, optionally with storing term vectors.8Field(String name, String value, Field.Store store, Field.Index index)
Create a field by specifying its name, value and how it will be saved in the index.9Field(String name, String value, Field.Store store, Field.Index index, Field.TermVector termVector)
Create a field by specifying its name, value and how it will be saved in the index.10Field(String name, TokenStream tokenStream)
Create a tokenized and indexed field that is not stored.11Field(String name, TokenStream tokenStream, Field.TermVector termVector)
Create a tokenized and indexed field that is not stored, optionally with storing term vectors.
Class methods
Attempt to clear (forcefully unlock and remove) the specified lock.2Reader readerValue()
The value of the field as a Reader, or null.3void setTokenStream(TokenStream tokenStream)
Expert: sets the token stream to be used for indexing and causes isIndexed() and isTokenized() to return true.4void setValue(byte[] value)
Expert: change the value of this field.5void setValue(byte[] value, int offset, int length)
Expert: change the value of this field.6void setValue(Reader value)
Expert: change the value of this field.7void setValue(String value)
Expert: change the value of this field.8String stringValue()
The value of the field as a String, or null.9TokenStream tokenStreamValue()
The TokesStream for this field to be used when indexing, or null.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.document.AbstractField
java.lang.Object
Lucene - Searching Classes
Searching process is again one of the core functionality provided by Lucene. It's flow is similar to that of indexing process. Basic search of lucene can be made using following classes which can also be termed as foundation classes for all search related operations.
Searching Classes:
Following is the list of commonly used classes during searching process.
This class act as a core component which reads/searches indexes created after indexing process. It takes directory instance pointing to the location containing the indexes.2Term
This class is the lowest unit of searching. It is similar to Field in indexing process.3Query
Query is an abstract class and contains various utility methods and is the parent of all types of queries that lucene uses during search process.4TermQuery
TermQuery is the most commonly used query object and is the foundation of many complex queries that lucene can make use of.5TopDocs
TopDocs points to the top N search results which matches the search criteria. It is simple container of pointers to point to documents which are output of search result.
Lucene - IndexSearcher
Introduction
This class acts as a core component which reads/searches indexes during searching process.
Class declaration
Following is the declaration for org.apache.lucene.search.IndexSearcher class:
public class IndexSearcher extends Searcher
Field
Following are the fields for org.apache.lucene.index.IndexWriter class:
protected int[] docStarts
protected IndexReader[] subReaders
protected IndexSearcher[] subSearchers
Class constructors
Deprecated. Use IndexSearcher(IndexReader) instead.2IndexSearcher(Directory path, boolean readOnly)
Deprecated. Use IndexSearcher(IndexReader) instead.3IndexSearcher(IndexReader r)
Creates a searcher searching the provided index.4IndexSearcher(IndexReader r, ExecutorService executor)
Runs searches for each segment separately, using the provided ExecutorService.5IndexSearcher(IndexReader reader, IndexReader[] subReaders, int[] docStarts)
Expert: directly specify the reader, subReaders and their docID starts.6IndexSearcher(IndexReader reader, IndexReader[] subReaders, int[] docStarts, ExecutorService executor)
Expert: directly specify the reader, subReaders and their docID starts, and an ExecutorService.
Class methods
Note that the underlying IndexReader is not closed, if IndexSearcher was constructed with IndexSearcher(IndexReader r).2Weight createNormalizedWeight(Query query)
Creates a normalized weight for a top-level Query.3Document doc(int docID)
Returns the stored fields of document i.4Document doc(int docID, FieldSelector fieldSelector)
Get the Document at the nth position.5int docFreq(Term term)
Returns total docFreq for this term.6Explanation explain(Query query, int doc)
Returns an Explanation that describes how doc scored against query.7Explanation explain(Weight weight, int doc)
Expert: low-level implementation method Returns an Explanation that describes how doc scored against weight.8protected void gatherSubReaders(List allSubReaders, IndexReader r)
9IndexReader getIndexReader()
Return the IndexReader this searches.10Similarity getSimilarity()
Expert: Return the Similarity implementation used by this Searcher.11IndexReader[] getSubReaders()
Returns the atomic subReaders used by this searcher.12int maxDoc()
Expert: Returns one greater than the largest possible document number.13Query rewrite(Query original)
Expert: called to re-write queries into primitive queries.14void search(Query query, Collector results)
Lower-level search API.15void search(Query query, Filter filter, Collector results)
Lower-level search API.16TopDocs search(Query query, Filter filter, int n)
Finds the top n hits for query, applying filter if non-null.17TopFieldDocs search(Query query, Filter filter, int n, Sort sort)
Search implementation with arbitrary sorting.18TopDocs search(Query query, int n)
Finds the top n hits for query.19TopFieldDocs search(Query query, int n, Sort sort)
Search implementation with arbitrary sorting and no filter.20void search(Weight weight, Filter filter, Collector collector)
Lower-level search API.21TopDocs search(Weight weight, Filter filter, int nDocs)
Expert: Low-level search implementation.22TopFieldDocs search(Weight weight, Filter filter, int nDocs, Sort sort)
Expert: Low-level search implementation with arbitrary sorting.23protected TopFieldDocs search(Weight weight, Filter filter, int nDocs, Sort sort, boolean fillFields)
Just like search(Weight, Filter, int, Sort), but you choose whether or not the fields in the returned FieldDoc instances should be set by specifying fillFields.24protected TopDocs search(Weight weight, Filter filter, ScoreDoc after, int nDocs)
Expert: Low-level search implementation.25TopDocs searchAfter(ScoreDoc after, Query query, Filter filter, int n)
Finds the top n hits for query, applying filter if non-null, where all results are after a previous result (after).26TopDocs searchAfter(ScoreDoc after, Query query, int n)
Finds the top n hits for query where all results are after a previous result (after).27void setDefaultFieldSortScoring(boolean doTrackScores, boolean doMaxScore)
By default, no scores are computed when sorting by field (using search(Query,Filter,int,Sort)).28void setSimilarity(Similarity similarity)
Expert: Set the Similarity implementation used by this Searcher.29String toString()
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Searcher
java.lang.Object
Lucene - Term
Introduction
This class is the lowest unit of searching. It is similar to Field in indexing process.
Class declaration
Following is the declaration for org.apache.lucene.index.Term class:
public final class Term extends Object implements Comparable, Serializable
Class constructors
Constructs a Term with the given field and empty text.2Term(String fld, String txt)
Constructs a Term with the given field and text.
Class methods
Adds a document to this index.2int compareTo(Term other)
Compares two terms, returning a negative integer if this term belongs before the argument, zero if this term is equal to the argument, and a positive integer if this term belongs after the argument.3Term createTerm(String text)
Optimized construction of new Terms by reusing same field as this Term - avoids field.intern() overhead4boolean equals(Object obj)
5String field()
Returns the field of this term, an interned string.6int hashCode()
7String text()
Returns the text of this term.8String toString()
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Query
Introduction
Query is an abstract class and contains various utility methods and is the parent of all types of queries that lucene uses during search process.
Class declaration
Following is the declaration for org.apache.lucene.search.Query class:
public abstract class Query extends Object implements Serializable, Cloneable
Class constructors
Class methods
Returns a clone of this query.2Query combine(Query[] queries)
Expert: called when re-writing queries under MultiSearcher.3Weight createWeight(Searcher searcher)
Expert: Constructs an appropriate Weight implementation for this query.4boolean equals(Object obj)
5void extractTerms(Set<Term> terms)
Expert: adds all terms occurring in this query to the terms set.6float getBoost()
Gets the boost for this clause.7Similarity getSimilarity(Searcher searcher)
Deprecated. Instead of using "runtime" subclassing/delegation, subclass the Weight instead.8int hashCode()
9static Query mergeBooleanQueries(BooleanQuery... queries)
Expert: merges the clauses of a set of BooleanQuery's into a single BooleanQuery.10Query rewrite(IndexReader reader)
Expert: called to re-write queries into primitive queries.11void setBoost(float b)
Sets the boost for this query clause to b.12String toString()
Prints a query to a string.13abstract String toString(String field)
Prints a query to a string, with field assumed to be the default field and omitted.14Weight weight(Searcher searcher)
Deprecated. never ever use this method in Weight implementations. Subclasses of Query should use createWeight(org.apache.lucene.search.Searcher), instead.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - TermQuery
Introduction
TermQuery is the most commonly used query object and is the foundation of many complex queries that lucene can make use of.
Class declaration
Following is the declaration for org.apache.lucene.search.TermQuery class:
public class TermQuery extends Query
Class constructors
Constructs a query for the term t.
Class methods
Adds a document to this index.2Weight createWeight(Searcher searcher)
Expert: Constructs an appropriate Weight implementation for this query.3boolean equals(Object o)
Returns true iff o is equal to this.4void extractTerms(Set<Term> terms)
Expert: adds all terms occurring in this query to the terms set.5Term getTerm()
Returns the term of this query.6int hashCode()
Returns a hash code value for this object.7String toString(String field)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Query
java.lang.Object
Lucene - TopDocs
Introduction
TopDocs points to the top N search results which matches the search criteria. It is simple container of pointers to point to documents which are output of search result.
Class declaration
Following is the declaration for org.apache.lucene.search.TopDocs class:
public class TopDocs extends Object implements Serializable
Field
Following are the fields for org.apache.lucene.search.TopDocs class:
ScoreDoc[] scoreDocs -- The top hits for the query.
int totalHits -- The total number of hits for the query.
Class constructors
Class methods
Returns the maximum score value encountered.2static TopDocs merge(Sort sort, int topN, TopDocs[] shardHits)
Returns a new TopDocs, containing topN results across the provided TopDocs, sorting by the specified Sort.3void setMaxScore(float maxScore)
Sets the maximum score value encountered.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - Indexing Process
Indexing process is one of the core functionality provided by Lucene. Following diagram illustrates the indexing process and use of classes. IndexWriter is the most important and core component of the indexing process.
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using theAnalyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Now we'll show you a step by step process to get a kick start in understanding of indexing process using a basic example.
Create a document
Create a method to get a lucene document from a text file.
Create various types of fields which are key value pairs containing keys as names and values as contents to be indexed.
Set field to be analyzed or not. In our case, only contents is to be analyzed as it can contain data such as a, am, are, an etc. which are not required in search operations.
Add the newly created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document;}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during indexing process.
Create object of IndexWriter.
Create a lucene directory which should point to location where indexes are to be stored.
Initialize the IndexWriter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED);}
Start Indexing process
private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document);}
Example Application
Let us create a test Lucene application to test indexing process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
LuceneTester.java
This class is used to test the indexing capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Indexing E:\Lucene\Data\record1.txtIndexing E:\Lucene\Data\record10.txtIndexing E:\Lucene\Data\record2.txtIndexing E:\Lucene\Data\record3.txtIndexing E:\Lucene\Data\record4.txtIndexing E:\Lucene\Data\record5.txtIndexing E:\Lucene\Data\record6.txtIndexing E:\Lucene\Data\record7.txtIndexing E:\Lucene\Data\record8.txtIndexing E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have following content in your index directory:
Lucene - Indexing Operations
In this chapter, we'll discuss the four major operations of indexing. These operations are useful at various times and are used throughout of a software search application.
Indexing Operations:
Following is the list of commonly used operations during indexing process.
This operation is used in the initial stage of indexing proces to create the indexes on the newly available contents.2Update Document
This operation is used to update indexes to reflect the changes in the updated contents. It is similar to recreating the index.3Delete Document
This operation is used to update indexes to exclude the documents which are not required to be indexed/searched.4Field Options
Field options specifies a way or controls the way in which contents of a field are to be made searchable.
Lucene - Add Document Operation
Add document is one of the core operation as part of indexing process.
We add Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update or create indexes.
Now we'll show you a step by step process to get a kick start in understanding of add document using a basic example.
Add a document to an index.
Create a method to get a lucene document from a text file.
Create various types of fields which are key value pairs containing keys as names and values as contents to be indexed.
Set field to be analyzed or not. In our case, only contents is to be analyzed as it can contain data such as a, am, are, an etc. which are not required in search operations.
Add the newly created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document;}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during indexing process.
Create object of IndexWriter.
Create a lucene directory which should point to location where indexes are to be stored.
Initialize the IndexWricrter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED);}
Add document and start Indexing process
Following two are the ways to add the document.
addDocument(Document) - Adds the document using the default analyzer (specified when index writer is created.)
addDocument(Document,Analyzer) - Adds the document using the provided analyzer.
private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document);}
Example Application
Let us create a test Lucene application to test indexing process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
LuceneTester.java
This class is used to test the indexing capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Indexing E:\Lucene\Data\record1.txtIndexing E:\Lucene\Data\record10.txtIndexing E:\Lucene\Data\record2.txtIndexing E:\Lucene\Data\record3.txtIndexing E:\Lucene\Data\record4.txtIndexing E:\Lucene\Data\record5.txtIndexing E:\Lucene\Data\record6.txtIndexing E:\Lucene\Data\record7.txtIndexing E:\Lucene\Data\record8.txtIndexing E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have following content in your index directory:
Lucene - Update Document Operation
Update document is another important operation as part of indexing process.This operation is used when already indexed contents are updated and indexes become invalid. This operation is also known as re-indexing.
We update Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update indexes.
Now we'll show you a step by step process to get a kick start in understanding of update document using a basic example.
Update a document to an index.
Create a method to update a lucene document from an updated text file.
private void updateDocument(File file) throws IOException{ Document document = new Document(); //update indexes for file contents writer.updateDocument( new Term(LuceneConstants.CONTENTS, new FileReader(file)),document); writer.close();}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during indexing process.
Create object of IndexWriter.
Create a lucene directory which should point to location where indexes are to be stored.
Initialize the IndexWricrter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED);}
Update document and start reindexing process
Following two are the ways to update the document.
updateDocument(Term, Document) - Delete the document containing the term and add the document using the default analyzer (specified when index writer is created.)
updateDocument(Term, Document,Analyzer) - Delete the document containing the term and add the document using the provided analyzer.
private void indexFile(File file) throws IOException{ System.out.println("Updating index for "+file.getCanonicalPath()); updateDocument(file); }
Example Application
Let us create a test Lucene application to test indexing process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private void updateDocument(File file) throws IOException{ Document document = new Document(); //update indexes for file contents writer.updateDocument( new Term(LuceneConstants.FILE_NAME, file.getName()),document); writer.close(); } private void indexFile(File file) throws IOException{ System.out.println("Updating index: "+file.getCanonicalPath()); updateDocument(file); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
LuceneTester.java
This class is used to test the indexing capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Updating index for E:\Lucene\Data\record1.txtUpdating index for E:\Lucene\Data\record10.txtUpdating index for E:\Lucene\Data\record2.txtUpdating index for E:\Lucene\Data\record3.txtUpdating index for E:\Lucene\Data\record4.txtUpdating index for E:\Lucene\Data\record5.txtUpdating index for E:\Lucene\Data\record6.txtUpdating index for E:\Lucene\Data\record7.txtUpdating index for E:\Lucene\Data\record8.txtUpdating index for E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have following content in your index directory:
Lucene - Delete Document Operation
Delete document is another important operation as part of indexing process.This operation is used when already indexed contents are updated and indexes become invalid or indexes become very large in size then in order to reduce the size and update the index, delete operations are carried out.
We delete Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update indexes.
Now we'll show you a step by step process to get a kick start in understanding of delete document using a basic example.
Delete a document from an index.
Create a method to delete a lucene document of an obsolete text file.
private void deleteDocument(File file) throws IOException{ //delete indexes for a file writer.deleteDocument(new Term(LuceneConstants.FILE_NAME,file.getName())); writer.commit(); System.out.println("index contains deleted files: "+writer.hasDeletions()); System.out.println("index contains documents: "+writer.maxDoc()); System.out.println("index contains deleted documents: "+writer.numDoc());}
Create a IndexWriter
IndexWriter class acts as a core component which creates/updates indexes during indexing process.
Create object of IndexWriter.
Create a lucene directory which should point to location where indexes are to be stored.
Initialize the IndexWricrter object created with the index directory, a standard analyzer having version information and other required/optional parameters.
private IndexWriter writer;public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED);}
Delete document and start reindexing process
Following two are the ways to delete the document.
deleteDocuments(Term) - Delete all the documents containing the term.
deleteDocuments(Term[]) - Delete all the documents containing any of the terms in the array.
deleteDocuments(Query) - Delete all the documents matching the query.
deleteDocuments(Query[]) - Delete all the documents matching the query in the array.
deleteAll - Delete all the documents.
private void indexFile(File file) throws IOException{ System.out.println("Deleting index for "+file.getCanonicalPath()); deleteDocument(file); }
Example Application
Let us create a test Lucene application to test indexing process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.Term;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private void deleteDocument(File file) throws IOException{ //delete indexes for a file writer.deleteDocuments( new Term(LuceneConstants.FILE_NAME,file.getName())); writer.commit(); } private void indexFile(File file) throws IOException{ System.out.println("Deleting index: "+file.getCanonicalPath()); deleteDocument(file); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
LuceneTester.java
This class is used to test the indexing capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Deleting index E:\Lucene\Data\record1.txtDeleting index E:\Lucene\Data\record10.txtDeleting index E:\Lucene\Data\record2.txtDeleting index E:\Lucene\Data\record3.txtDeleting index E:\Lucene\Data\record4.txtDeleting index E:\Lucene\Data\record5.txtDeleting index E:\Lucene\Data\record6.txtDeleting index E:\Lucene\Data\record7.txtDeleting index E:\Lucene\Data\record8.txtDeleting index E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have following content in your index directory:
Lucene - Field Options
Field is the most important and the foundation unit of indexing process. It is the actual object containing the contents to be indexed. When we add a field, lucene provides numerous controls on the field using Field Options which states how much a field is to be searchable.
We add Document(s) containing Field(s) to IndexWriter where IndexWriter is used to update or create indexes.
Now we'll show you a step by step process to get a kick start in understanding of various Field options using a basic example.
Various Field Options
Index.ANALYZED - First analyze then do indexing. Used for normal text indexing. Analyzer will break the field's value into stream of tokens and each token is searcable sepearately.
Index.NOT_ANALYZED - Don't analyze but do indexing. Used for complete text indexing for example person's names, URL etc.
Index.ANALYZED_NO_NORMS - Varient of Index.ANALYZED. Analyzer will break the field's value into stream of tokens and each token is searcable sepearately but NORMs are not stored in the indexes.NORMS are used to boost searching but are sometime memory consuming.
Index.Index.NOT_ANALYZED_NO_NORMS - Varient of Index.NOT_ANALYZED. Indexing is done but NORMS are not stored in the indexes.
Index.NO - Field value is not searchable.
Use of Field Options
Create a method to get a lucene document from a text file.
Create various types of fields which are key value pairs containing keys as names and values as contents to be indexed.
Set field to be analyzed or not. In our case, only contents is to be analyzed as it can contain data such as a, am, are, an etc. which are not required in search operations.
Add the newly created fields to the document object and return it to the caller method.
private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document;}
Example Application
Let us create a test Lucene application to test indexing process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Indexer.java
This class is used to index the raw data so that we can make it searchable using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException{ //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException{ writer.close(); } private Document getDocument(File file) throws IOException{ Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException{ System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException{ //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); }}
LuceneTester.java
This class is used to test the indexing capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException{ indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running this program, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory and index directory, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
Indexing E:\Lucene\Data\record1.txtIndexing E:\Lucene\Data\record10.txtIndexing E:\Lucene\Data\record2.txtIndexing E:\Lucene\Data\record3.txtIndexing E:\Lucene\Data\record4.txtIndexing E:\Lucene\Data\record5.txtIndexing E:\Lucene\Data\record6.txtIndexing E:\Lucene\Data\record7.txtIndexing E:\Lucene\Data\record8.txtIndexing E:\Lucene\Data\record9.txt10 File indexed, time taken: 109 ms
Once you've run the program successfully, you will have following content in your index directory:
Lucene - Search Operation
Searching process is one of the core functionality provided by Lucene. Following diagram illustrates the searching process and use of classes. IndexSearcher is the most important and core component of the searching process.
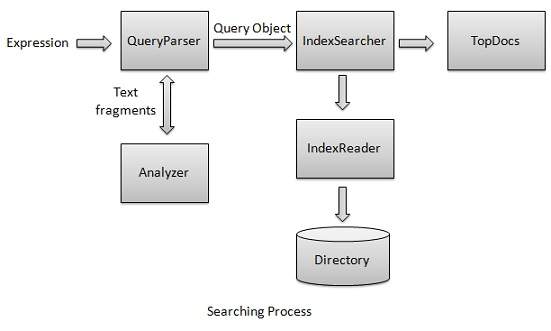
We first create Directory(s) containing indexes and then pass it to IndexSearcher which opens theDirectory using IndexReader. Then we create a Query with a Term and make a search usingIndexSearcher by passing the Query to the searcher. IndexSearcher returns a TopDocs object which contains the search details along with document ID(s) of the Document which is the result of the search operation.
Now we'll show you a step by step process to get a kick start in understanding of indexing process using a basic example.
Create a QueryParser
QueryParser class parses the user entered input into lucene understandable format query.
Create object of QueryParser.
Initialize the QueryParser object created with a standard analyzer having version information and index name on which this query is to run.
QueryParser queryParser;public Searcher(String indexDirectoryPath) throws IOException{ queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36));}
Create a IndexSearcher
IndexSearcher class acts as a core component which searcher indexes created during indexing process.
Create object of IndexSearcher.
Create a lucene directory which should point to location where indexes are to be stored.
Initialize the IndexSearcher object created with the index directory
IndexSearcher indexSearcher;public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory);}
Make search
To start search, create a Query object by parsing search expression through QueryParser.
Make search by calling IndexSearcher.search() method.
Query query;public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);}
Get the document
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc);}
Close IndexSearcher
public void close() throws IOException{ indexSearcher.close();}
Example Application
Let us create a test Lucene application to test searching process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
TextFileFilter.java
This class is used as a .txt file filter.
package com.tutorialspoint.lucene;import java.io.File;import java.io.FileFilter;public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); }}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void search(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) +" ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
1 documents found. Time :29 msFile: E:\Lucene\Data\record4.txt
Lucene - Query Programming
As we've seen in previous chapter Lucene - Search Operation, Lucene uses IndexSearcher to make searches and it uses Query object created by QueryParser as input. In this chapter, we are going to discuss various types of Query objects and ways to create them programmatically. Creating different types of Query object gives control on the kind of search to be made.
Consider a case of Advanced Search, provided by many applications where users are given multiple options to confine the search results. By Query programming, we can achieve the same very easily.
Following is the list of Query types that we'll discuss in due course.
This class acts as a core component which creates/updates indexes during indexing process.2TermRangeQuery
TermRangeQuery is the used when a range of textual terms are to be searched.3PrefixQuery
PrefixQuery is used to match documents whose index starts with a specified string.4BooleanQuery
BooleanQuery is used to search documents which are result of multiple queries using AND, OR or NOT operators.5PhraseQuery
Phrase query is used to search documents which contain a particular sequence of terms.6WildCardQuery
WildcardQuery is used to search documents using wildcards like '*' for any character sequence,? matching a single character.7FuzzyQuery
FuzzyQuery is used to search documents using fuzzy implementation that is an approximate search based on edit distance algorithm.8MatchAllDocsQuery
MatchAllDocsQuery as name suggests matches all the documents.
Lucene - TermQuery
Introduction
TermQuery is the most commonly used query object and is the foundation of many complex queries that lucene can make use of. TermQuery is normally used to retrieve documents based on the key which is case sensitive.
Class declaration
Following is the declaration for org.apache.lucene.search.TermQuery class:
public class TermQuery extends Query
Class constructors
Constructs a query for the term t.
Class methods
Adds a document to this index.2Weight createWeight(Searcher searcher)
Expert: Constructs an appropriate Weight implementation for this query.3boolean equals(Object o)
Returns true iff o is equal to this.4void extractTerms(Set<Term> terms)
Expert: adds all terms occurring in this query to the terms set.5Term getTerm()
Returns the term of this query.6int hashCode()
Returns a hash code value for this object.7String toString(String field)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingTermQuery( String searchQuery)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new TermQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using TermQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingTermQuery("record4.txt"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingTermQuery( String searchQuery)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new TermQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
1 documents found. Time :13 msFile: E:\Lucene\Data\record4.txt
Lucene - TermRangeQuery
Introduction
TermRangeQuery is the used when a range of textual terms are to be searched.
Class declaration
Following is the declaration for org.apache.lucene.search.TermRangeQuery class:
public class TermRangeQuery extends MultiTermQuery
Class constructors
Constructs a query selecting all terms greater/equal than lowerTerm but less/equal than upperTerm.2TermRangeQuery(String field, String lowerTerm, String upperTerm, boolean includeLower, boolean includeUpper, Collator collator)
Constructs a query selecting all terms greater/equal than lowerTerm but less/equal than upperTerm.
Class methods
2Collator getCollator()
Returns the collator used to determine range inclusion, if any.3protected FilteredTermEnum getEnum(IndexReader reader)
Construct the enumeration to be used, expanding the pattern term.4String getField()
Returns the field name for this query.5String getLowerTerm()
Returns the lower value of this range query.6String getUpperTerm()
Returns the upper value of this range query.7int hashCode()
8boolean includesLower()
Returns true if the lower endpoint is inclusive.9boolean includesUpper()
Returns true if the upper endpoint is inclusive.10String toString(String field)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.MultiTermQuery
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingTermRangeQuery(String searchQueryMin, String searchQueryMax)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create the term query object Query query = new TermRangeQuery(LuceneConstants.FILE_NAME, searchQueryMin,searchQueryMax,true,false); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using TermRangeQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermRangeQuery;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingTermRangeQuery("record2.txt","record6.txt"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingTermRangeQuery(String searchQueryMin, String searchQueryMax)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create the term query object Query query = new TermRangeQuery(LuceneConstants.FILE_NAME, searchQueryMin,searchQueryMax,true,false); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
4 documents found. Time :17msFile: E:\Lucene\Data\record2.txtFile: E:\Lucene\Data\record3.txtFile: E:\Lucene\Data\record4.txtFile: E:\Lucene\Data\record5.txt
Lucene - PrefixQuery
Introduction
PrefixQuery is used to match documents whose index starts with a specified string.
Class declaration
Following is the declaration for org.apache.lucene.search.PrefixQuery class:
public class PrefixQuery extends MultiTermQuery
Class constructors
Constructs a query for the term starting with prefix.
Class methods
Returns true iff o is equal to this.2protected FilteredTermEnumgetEnum(IndexReader reader)
Construct the enumeration to be used, expanding the pattern term3Term getPrefix()
Returns the prefix of this query.4int hashCode()
Returns a hash code value for this object.5String toString(String field)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.MultiTermQuery
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingPrefixQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new PrefixQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using PrefixQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.PrefixQuery;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingPrefixQuery("record1"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingPrefixQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new PrefixQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
2 documents found. Time :20msFile: E:\Lucene\Data\record1.txtFile: E:\Lucene\Data\record10.txt
Lucene - BooleanQuery
Introduction
BooleanQuery is used to search documents which are result of multiple queries using AND, OR or NOT operators.
Class declaration
Following is the declaration for org.apache.lucene.search.BooleanQuery class:
public class BooleanQuery extends Query implements Iterable<BooleanClause>
Fields
protected int minNrShouldMatch
Class constructors
Constructs an empty boolean query.1BooleanQuery(boolean disableCoord)
Constructs an empty boolean query.
Class methods
Adds a clause to a boolean query.2void add(Query query, BooleanClause.Occur occur)
Adds a clause to a boolean query.3List<BooleanClause> clauses()
Returns the list of clauses in this query.4Object clone()
Returns a clone of this query.5Weight createWeight(Searcher searcher)
Expert: Constructs an appropriate Weight implementation for this query.6boolean equals(Object o)
Returns true iff o is equal to this.7void extractTerms(Set<Term> terms)
Expert: adds all terms occurring in this query to the terms set.8BooleanClause[] getClauses()
Returns the set of clauses in this query.9static int getMaxClauseCount()
Return the maximum number of clauses permitted, 1024 by default.10int getMinimumNumberShouldMatch()
Gets the minimum number of the optional BooleanClauses which must be satisfied.11int hashCode()
Returns a hash code value for this object.12boolean isCoordDisabled()
Returns true iff Similarity.coord(int,int) is disabled in scoring for this query instance.13Iterator<BooleanClause> iterator()
Returns an iterator on the clauses in this query.14Query rewrite(IndexReader reader)
Expert: called to re-write queries into primitive queries.15static void setMaxClauseCount(int maxClauseCount)
Set the maximum number of clauses permitted per BooleanQuery.16void setMinimumNumberShouldMatch(int min)
Specifies a minimum number of the optional BooleanClauses which must be satisfied.17String toString(String field)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingBooleanQuery(String searchQuery1, String searchQuery2)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term1 = new Term(LuceneConstants.FILE_NAME, searchQuery1); //create the term query object Query query1 = new TermQuery(term1); Term term2 = new Term(LuceneConstants.FILE_NAME, searchQuery2); //create the term query object Query query2 = new PrefixQuery(term2); BooleanQuery query = new BooleanQuery(); query.add(query1,BooleanClause.Occur.MUST_NOT); query.add(query2,BooleanClause.Occur.MUST); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using BooleanQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.BooleanClause;import org.apache.lucene.search.PrefixQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.BooleanQuery;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingBooleanQuery("record1.txt","record1"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingBooleanQuery(String searchQuery1, String searchQuery2)throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term1 = new Term(LuceneConstants.FILE_NAME, searchQuery1); //create the term query object Query query1 = new TermQuery(term1); Term term2 = new Term(LuceneConstants.FILE_NAME, searchQuery2); //create the term query object Query query2 = new PrefixQuery(term2); BooleanQuery query = new BooleanQuery(); query.add(query1,BooleanClause.Occur.MUST_NOT); query.add(query2,BooleanClause.Occur.MUST); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
1 documents found. Time :26msFile: E:\Lucene\Data\record10.txt
Lucene - PhraseQuery
Introduction
Phrase query is used to search documents which contain a particular sequence of terms.
Class declaration
Following is the declaration for org.apache.lucene.search.PhraseQuery class:
public class PhraseQuery extends Query
Class constructors
Constructs an empty phrase query.
Class methods
Adds a term to the end of the query phrase.2void add(Term term, int position)
Adds a term to the end of the query phrase.3Weight createWeight(Searcher searcher)
Expert: Constructs an appropriate Weight implementation for this query.4boolean equals(Object o)
Returns true iff o is equal to this.5void extractTerms(Set<Term> queryTerms)
Expert: adds all terms occurring in this query to the terms set.6int[] getPositions()
Returns the relative positions of terms in this phrase.7int getSlop()
Returns the slop.8Term[] getTerms()
Returns the set of terms in this phrase.9int hashCode()
Returns a hash code value for this object.10Query rewrite(IndexReader reader)
Expert: called to re-write queries into primitive queries.11void setSlop(int s)
Sets the number of other words permitted between words in query phrase.12String toString(String f)
Prints a user-readable version of this query.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingPhraseQuery(String[] phrases) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); PhraseQuery query = new PhraseQuery(); query.setSlop(0); for(String word:phrases){ query.add(new Term(LuceneConstants.FILE_NAME,word)); } //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using PhraseQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.PhraseQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); String[] phrases = new String[]{"record1.txt"}; tester.searchUsingPhraseQuery(phrases); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingPhraseQuery(String[] phrases) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); PhraseQuery query = new PhraseQuery(); query.setSlop(0); for(String word:phrases){ query.add(new Term(LuceneConstants.FILE_NAME,word)); } //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
1 documents found. Time :14msFile: E:\Lucene\Data\record1.txt
Lucene - FuzzyQuery
Introduction
FuzzyQuery is used to search documents using fuzzy implementation that is an approximate search based on edit distance algorithm.
Class declaration
Following is the declaration for org.apache.lucene.search.FuzzyQuery class:
public class FuzzyQuery extends MultiTermQuery
Fields
static int defaultMaxExpansions
static float defaultMinSimilarity
static int defaultPrefixLength
protected Term term
Class constructors
Calls FuzzyQuery(term, 0.5f, 0, Integer.MAX_VALUE).2FuzzyQuery(Term term, float minimumSimilarity)
Calls FuzzyQuery(term, minimumSimilarity, 0, Integer.MAX_VALUE).3FuzzyQuery(Term term, float minimumSimilarity, int prefixLength)
Calls FuzzyQuery(term, minimumSimilarity, prefixLength, Integer.MAX_VALUE).4FuzzyQuery(Term term, float minimumSimilarity, int prefixLength, int maxExpansions)
Create a new FuzzyQuery that will match terms with a similarity of at least minimum Similarity to term.
Class methods
1boolean equals(Object obj)2protected FilteredTermEnum getEnum(IndexReader reader)
Construct the enumeration to be used, expanding the pattern term.3float getMinSimilarity()
Returns the minimum similarity that is required for this query to match.4int getPrefixLength()
Returns the non-fuzzy prefix length.5Term getTerm()
Returns the pattern term.6int hashCode()
7String toString(String field)
Prints a query to a string, with field assumed to be the default field and omitted.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.MultiTermQuery
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingFuzzyQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using FuzzyQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.FuzzyQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingFuzzyQuery("cord3.txt"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingFuzzyQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
10 documents found. Time :78msScore: 1.3179655 File: E:\Lucene\Data\record3.txtScore: 0.790779 File: E:\Lucene\Data\record1.txtScore: 0.790779 File: E:\Lucene\Data\record2.txtScore: 0.790779 File: E:\Lucene\Data\record4.txtScore: 0.790779 File: E:\Lucene\Data\record5.txtScore: 0.790779 File: E:\Lucene\Data\record6.txtScore: 0.790779 File: E:\Lucene\Data\record7.txtScore: 0.790779 File: E:\Lucene\Data\record8.txtScore: 0.790779 File: E:\Lucene\Data\record9.txtScore: 0.2635932 File: E:\Lucene\Data\record10.txt
Lucene - MatchAllDocsQuery
Introduction
MatchAllDocsQuery as name suggests matches all the documents.
Class declaration
Following is the declaration for org.apache.lucene.search.MatchAllDocsQuery class:
public class MatchAllDocsQuery extends Query
Class constructors
2MatchAllDocsQuery(String normsField)
Class methods
Expert: Constructs an appropriate Weight implementation for this query.2boolean equals(Object o)
3void extractTerms(Set<Term> terms)
Expert: adds all terms occurring in this query to the terms set.4int hashCode()
5String toString(String field)
Prints a query to a string, with field assumed to be the default field and omitted.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.search.Query
java.lang.Object
Usage
private void searchUsingMatchAllDocsQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create the term query object Query query = new MatchAllDocsQuery(searchQuery); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test search using MatchAllDocsQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.MatchAllDocsQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.searchUsingMatchAllDocsQuery(""); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void searchUsingMatchAllDocsQuery(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create the term query object Query query = new MatchAllDocsQuery(searchQuery); //do the search TopDocs hits = searcher.search(query); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
10 documents found. Time :9msScore: 1.0 File: E:\Lucene\Data\record1.txtScore: 1.0 File: E:\Lucene\Data\record10.txtScore: 1.0 File: E:\Lucene\Data\record2.txtScore: 1.0 File: E:\Lucene\Data\record3.txtScore: 1.0 File: E:\Lucene\Data\record4.txtScore: 1.0 File: E:\Lucene\Data\record5.txtScore: 1.0 File: E:\Lucene\Data\record6.txtScore: 1.0 File: E:\Lucene\Data\record7.txtScore: 1.0 File: E:\Lucene\Data\record8.txtScore: 1.0 File: E:\Lucene\Data\record9.txt
Lucene - Analysis
As we've seen in one of the previous chapter Lucene - Indexing Process, Lucene uses IndexWriter which analyzes the Document(s) using the Analyzer and then creates/open/edit indexes as required. In this chapter, we are going to discuss various types of Analyzer objects and other relevant objects which are used during analysis process. Understanding Analysis process and how analyzers work will give you great insight over how lucene indexes the documents.
Following is the list of objects that we'll discuss in due course.
Token represents text or word in a document with relevant details like its metadata(position, start offset, end offset, token type and its position increment).2TokenStream
TokenStream is an output of analysis process and it comprises of series of tokens. It is an abstract class.3Analyzer
This is abstract base class of for each and every type of Analyzer.4WhitespaceAnalyzer
This analyzer spilts the text in a document based on whitespace.5SimpleAnalyzer
This analyzer spilts the text in a document based on non-letter characters and then lowercase them.6StopAnalyzer
This analyzer works similar to SimpleAnalyzer and remove the common words like 'a','an','the' etc.7StandardAnalyzer
This is the most sofisticated analyzer and is capable of handling names, email address etc. It lowercases each token and removes common words and punctuation if any.
Lucene - Token
Introduction
Token represents text or word in a document with relevant details like its metadata(position, start offset, end offset, token type and its position increment).
Class declaration
Following is the declaration for org.apache.lucene.analysis.Token class:
public class Token extends TermAttributeImpl implements TypeAttribute, PositionIncrementAttribute, FlagsAttribute, OffsetAttribute, PayloadAttribute, PositionLengthAttribute
Fields
static AttributeSource.AttributeFactory TOKEN_ATTRIBUTE_FACTORY - Convenience factory that returns Token as implementation for the basic attributes and return the default impl (with "Impl" appended) for all other attributes.
Class constructors
Constructs a Token will null text.2Token(char[] startTermBuffer, int termBufferOffset, int termBufferLength, int start, int end)
Constructs a Token with the given term buffer (offset & length), start and end offsets3Token(int start, int end)
Constructs a Token with null text and start & end offsets.4Token(int start, int end, int flags)
Constructs a Token with null text and start & end offsets plus flags.5Token(int start, int end, String typ)
Constructs a Token with null text and start & end offsets plus the Token type.6Token(String text, int start, int end)
Constructs a Token with the given term text, and start & end offsets.7Token(String text, int start, int end, int flags)
Constructs a Token with the given text, start and end offsets, & type.8Token(String text, int start, int end, String typ)
Constructs a Token with the given text, start and end offsets, & type.
Class methods
Resets the term text, payload, flags, and positionIncrement, startOffset, endOffset and token type to default.2Object clone()
Shallow clone.3Token clone(char[] newTermBuffer, int newTermOffset, int newTermLength, int newStartOffset, int newEndOffset)
Makes a clone, but replaces the term buffer & start/end offset in the process.4void copyTo(AttributeImpl target)
Copies the values from this Attribute into the passed-in target attribute.5int endOffset()
Returns this Token's ending offset, one greater than the position of the last character corresponding to this token in the source text.6boolean equals(Object obj)
7int getFlags()
Get the bitset for any bits that have been set.8Payload getPayload()
Returns this Token's payload.9int getPositionIncrement()
Returns the position increment of this Token.10int getPositionLength()
Get the position length.11int hashCode()
12void reflectWith(AttributeReflector reflector)
This method is for introspection of attributes, it should simply add the key/values this attribute holds to the given AttributeReflector.13Token reinit(char[] newTermBuffer, int newTermOffset, int newTermLength, int newStartOffset, int newEndOffset)
Shorthand for calling clear(), CharTermAttributeImpl.copyBuffer(char[], int, int), setStartOffset(int), setEndOffset(int) setType(java.lang.String) on Token.DEFAULT_TYPE14Token reinit(char[] newTermBuffer, int newTermOffset, int newTermLength, int newStartOffset, int newEndOffset, String newType)
Shorthand for calling clear(), CharTermAttributeImpl.copyBuffer(char[], int, int), setStartOffset(int), setEndOffset(int), setType(java.lang.String)15Token reinit(String newTerm, int newStartOffset, int newEndOffset)
Shorthand for calling clear(), CharTermAttributeImpl.append(CharSequence), setStartOffset(int), setEndOffset(int) setType(java.lang.String) on Token.DEFAULT_TYPE16Token reinit(String newTerm, int newTermOffset, int newTermLength, int newStartOffset, int newEndOffset)
Shorthand for calling clear(), CharTermAttributeImpl.append(CharSequence, int, int), setStartOffset(int), setEndOffset(int) setType(java.lang.String) on Token.DEFAULT_TYPE17Token reinit(String newTerm, int newTermOffset, int newTermLength, int newStartOffset, int newEndOffset, String newType)
Shorthand for calling clear(), CharTermAttributeImpl.append(CharSequence, int, int), setStartOffset(int), setEndOffset(int) setType(java.lang.String)18Token reinit(String newTerm, int newStartOffset, int newEndOffset, String newType)
Shorthand for calling clear(), CharTermAttributeImpl.append(CharSequence), setStartOffset(int), setEndOffset(int) setType(java.lang.String)19void reinit(Token prototype)
Copy the prototype token's fields into this one.20void reinit(Token prototype, char[] newTermBuffer, int offset, int length)
Copy the prototype token's fields into this one, with a different term.21void reinit(Token prototype, String newTerm)
Copy the prototype token's fields into this one, with a different term.22void setEndOffset(int offset)
Set the ending offset.23void setFlags(int flags)
24void setOffset(int startOffset, int endOffset)
Set the starting and ending offset.25void setPayload(Payload payload)
Sets this Token's payload.26void setPositionIncrement(int positionIncrement)
Set the position increment.27void setPositionLength(int positionLength)
Set the position length.28void setStartOffset(int offset)
Set the starting offset.29void setType(String type)
Set the lexical type.30int startOffset()
Returns this Token's starting offset, the position of the first character corresponding to this token in the source text.31String type()
Returns this Token's lexical type.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.analysis.tokenattributes.TermAttributeImpl
org.apache.lucene.analysis.tokenattributes.CharTermAttributeImpl
org.apache.lucene.util.AttributeImpl
java.lang.Object
Lucene - TokenStream
Introduction
TokenStream is an output of analysis process and it comprises of series of tokens. It is an abstract class.
Class declaration
Following is the declaration for org.apache.lucene.analysis.TokenStream class:
public abstract class TokenStream extends AttributeSource implements Closeable
Class constructors
A TokenStream using the default attribute factory.2protected TokenStream(AttributeSource.AttributeFactory factory)
A TokenStream using the supplied AttributeFactory for creating new Attribute instances.3protected TokenStream(AttributeSource input)
A TokenStream that uses the same attributes as the supplied one.
Class methods
Releases resources associated with this stream.2void end()
This method is called by the consumer after the last token has been consumed, after incrementToken() returned false (using the new TokenStream API).3abstract boolean incrementToken()
Consumers (i.e., IndexWriter) use this method to advance the stream to the next token.4void reset()
Resets this stream to the beginning.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.util.AttributeSource
java.lang.Object
Lucene - Analyzer
Introduction
Analyzer class is responsible to analyze a document and get the tokens/words from the text which is to be indexed. Without analysis done, IndexWriter can not create index.
Class declaration
Following is the declaration for org.apache.lucene.analysis.Analyzer class:
public abstract class Analyzer extends Object implements Closeable
Class constructors
Class methods
Frees persistent resources used by this Analyzer2int getOffsetGap(Fieldable field)
Just like getPositionIncrementGap(java.lang.String), except for Token offsets instead.3int getPositionIncrementGap(String fieldName)
Invoked before indexing a Fieldable instance if terms have already been added to that field.4protected Object getPreviousTokenStream()
Used by Analyzers that implement reusableTokenStream to retrieve previously saved TokenStreams for re-use by the same thread.5TokenStream reusableTokenStream(String fieldName, Reader reader)
Creates a TokenStream that is allowed to be re-used from the previous time that the same thread called this method.6protected void setPreviousTokenStream(Object obj)
Used by Analyzers that implement reusableTokenStream to save a TokenStream for later re-use by the same thread.7abstract TokenStream tokenStream(String fieldName, Reader reader)
Creates a TokenStream which tokenizes all the text in the provided Reader.
Methods inherited
This class inherits methods from the following classes:
java.lang.Object
Lucene - WhitespaceAnalyzer
Introduction
This analyzer spilts the text in a document based on whitespace.
Class declaration
Following is the declaration for org.apache.lucene.analysis.WhitespaceAnalyzer class:
public final class WhitespaceAnalyzer extends ReusableAnalyzerBase
Class constructors
Deprecated. use WhitespaceAnalyzer(Version) instead2WhitespaceAnalyzer(Version matchVersion)
Creates a new WhitespaceAnalyzer
Class methods
Creates a new ReusableAnalyzerBase.TokenStreamComponents instance for this analyzer.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.analysis.ReusableAnalyzerBase
org.apache.lucene.analysis.Analyzer
java.lang.Object
Usage
private void displayTokenUsingWhitespaceAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new WhitespaceAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream(LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); }}
Example Application
Let us create a test Lucene application to test search using BooleanQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import java.io.StringReader;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.WhitespaceAnalyzer;import org.apache.lucene.analysis.tokenattributes.TermAttribute;import org.apache.lucene.util.Version;public class LuceneTester { public static void main(String[] args) { LuceneTester tester; tester = new LuceneTester(); try { tester.displayTokenUsingWhitespaceAnalyzer(); } catch (IOException e) { e.printStackTrace(); } } private void displayTokenUsingWhitespaceAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new WhitespaceAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream( LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); } }}
Running the Program:
Once you are done with creating source, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
[Lucene] [is] [simple] [yet] [powerful] [java] [based] [search] [library.]
Lucene - SimpleAnalyzer
Introduction
This analyzer spilts the text in a document based on non-letter characters and then lowercase them.
Class declaration
Following is the declaration for org.apache.lucene.analysis.SimpleAnalyzer class:
public final class SimpleAnalyzer extends ReusableAnalyzerBase
Class constructors
Deprecated. use SimpleAnalyzer(Version) instead2SimpleAnalyzer(Version matchVersion)
Creates a new SimpleAnalyzer
Class methods
Creates a new ReusableAnalyzerBase.TokenStreamComponents instance for this analyzer.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.analysis.ReusableAnalyzerBase
org.apache.lucene.analysis.Analyzer
java.lang.Object
Usage
private void displayTokenUsingSimpleAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new SimpleAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream( LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); }}
Example Application
Let us create a test Lucene application to test search using BooleanQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import java.io.StringReader;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.SimpleAnalyzer;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.tokenattributes.TermAttribute;import org.apache.lucene.util.Version;public class LuceneTester { public static void main(String[] args) { LuceneTester tester; tester = new LuceneTester(); try { tester.displayTokenUsingSimpleAnalyzer(); } catch (IOException e) { e.printStackTrace(); } } private void displayTokenUsingSimpleAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new SimpleAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream( LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); } }}
Running the Program:
Once you are done with creating source, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
[lucene] [is] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - StopAnalyzer
Introduction
This analyzer works similar to SimpleAnalyzer and remove the common words like 'a','an','the' etc.
Class declaration
Following is the declaration for org.apache.lucene.analysis.StopAnalyzer class:
public final class StopAnalyzer extends StopwordAnalyzerBase
Fields
static Set<?> ENGLISH_STOP_WORDS_SET - An unmodifiable set containing some common English words that are not usually useful for searching.
Class constructors
Builds an analyzer which removes words in ENGLISH_STOP_WORDS_SET.2StopAnalyzer(Version matchVersion, File stopwordsFile)
Builds an analyzer with the stop words from the given file.3StopAnalyzer(Version matchVersion, Reader stopwords)
Builds an analyzer with the stop words from the given reader.4StopAnalyzer(Version matchVersion, Set<?> stopWords)
Builds an analyzer with the stop words from the given set.
Class methods
Creates a new ReusableAnalyzerBase.TokenStreamComponents used to tokenize all the text in the provided Reader.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.analysis.StopwordAnalyzerBase
org.apache.lucene.analysis.ReusableAnalyzerBase
org.apache.lucene.analysis.Analyzer
java.lang.Object
Usage
private void displayTokenUsingStopAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new StopAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream(LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); }}
Example Application
Let us create a test Lucene application to test search using BooleanQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import java.io.StringReader;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.StopAnalyzer;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.tokenattributes.TermAttribute;import org.apache.lucene.util.Version;public class LuceneTester { public static void main(String[] args) { LuceneTester tester; tester = new LuceneTester(); try { tester.displayTokenUsingStopAnalyzer(); } catch (IOException e) { e.printStackTrace(); } } private void displayTokenUsingStopAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new StopAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream( LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); } }}
Running the Program:
Once you are done with creating source, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
[lucene] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - StandardAnalyzer
Introduction
This is the most sofisticated analyzer and is capable of handling names, email address etc. It lowercases each token and removes common words and punctuation if any.
Class declaration
Following is the declaration for org.apache.lucene.analysis.StandardAnalyzer class:
public final class StandardAnalyzer extends StopwordAnalyzerBase
Fields
static int DEFAULT_MAX_TOKEN_LENGTH - Default maximum allowed token length
static Set<?> STOP_WORDS_SET - An unmodifiable set containing some common English words that are usually not useful for searching.
Class constructors
Builds an analyzer with the default stop words (STOP_WORDS_SET).2StandardAnalyzer(Version matchVersion, File stopwords)
Deprecated. Use StandardAnalyzer(Version, Reader) instead.3StandardAnalyzer(Version matchVersion, Reader stopwords)
Builds an analyzer with the stop words from the given reader.4StandardAnalyzer(Version matchVersion, Set<?> stopWords)
Builds an analyzer with the given stop words.
Class methods
Creates a new ReusableAnalyzerBase.TokenStreamComponents instance for this analyzer.2int getMaxTokenLength()
3void setMaxTokenLength(int length)
Set maximum allowed token length.
Methods inherited
This class inherits methods from the following classes:
org.apache.lucene.analysis.StopwordAnalyzerBase
org.apache.lucene.analysis.ReusableAnalyzerBase
org.apache.lucene.analysis.Analyzer
java.lang.Object
Usage
private void displayTokenUsingStandardAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream(LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); }}
Example Application
Let us create a test Lucene application to test search using BooleanQuery.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import java.io.StringReader;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.StandardAnalyzer;import org.apache.lucene.analysis.tokenattributes.TermAttribute;import org.apache.lucene.util.Version;public class LuceneTester { public static void main(String[] args) { LuceneTester tester; tester = new LuceneTester(); try { tester.displayTokenUsingStandardAnalyzer(); } catch (IOException e) { e.printStackTrace(); } } private void displayTokenUsingStandardAnalyzer() throws IOException{ String text = "Lucene is simple yet powerful java based search library."; Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_36); TokenStream tokenStream = analyzer.tokenStream( LuceneConstants.CONTENTS, new StringReader(text)); TermAttribute term = tokenStream.addAttribute(TermAttribute.class); while(tokenStream.incrementToken()) { System.out.print("[" + term.term() + "] "); } }}
Running the Program:
Once you are done with creating source, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
[lucene] [simple] [yet] [powerful] [java] [based] [search] [library]
Lucene - Sorting
In this chapter we will look into the sorting orders in which lucene gives the search results by default or can be manipulated as required.
Sorting By Relevance
This is default sorting mode used by lucene. Lucene provides results by the most relevant hit at the top.
private void sortUsingRelevance(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.RELEVANCE); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Sorting By IndexOrder
This is sorting mode used by lucene in which first document indexed is shown first in the search results.
private void sortUsingIndex(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.INDEXORDER); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close();}
Example Application
Let us create a test Lucene application to test sorting process.
LuceneConstants.java
This class is used to provide various constants to be used across the sample application.
package com.tutorialspoint.lucene;public class LuceneConstants { public static final String CONTENTS="contents"; public static final String FILE_NAME="filename"; public static final String FILE_PATH="filepath"; public static final int MAX_SEARCH = 10;}
Searcher.java
This class is used to read the indexes made on raw data and searches data using lucene library.
package com.tutorialspoint.lucene;import java.io.File;import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.CorruptIndexException;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.Sort;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class Searcher {IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException{ Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException{ query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query,Sort sort) throws IOException, ParseException{ return indexSearcher.search(query, LuceneConstants.MAX_SEARCH,sort); } public void setDefaultFieldSortScoring(boolean doTrackScores, boolean doMaxScores){ indexSearcher.setDefaultFieldSortScoring( doTrackScores,doMaxScores); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException{ return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException{ indexSearcher.close(); }}
LuceneTester.java
This class is used to test the searching capability of lucene library.
package com.tutorialspoint.lucene;import java.io.IOException;import org.apache.lucene.document.Document;import org.apache.lucene.index.Term;import org.apache.lucene.queryParser.ParseException;import org.apache.lucene.search.FuzzyQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.Sort;import org.apache.lucene.search.TopDocs;public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.sortUsingRelevance("cord3.txt"); tester.sortUsingIndex("cord3.txt"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void sortUsingRelevance(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.RELEVANCE); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } private void sortUsingIndex(String searchQuery) throws IOException, ParseException{ searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.INDEXORDER); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }}
Data & Index directory creation
I've used 10 text files named from record1.txt to record10.txt containing simply names and other details of the students and put them in the directory E:\Lucene\Data. Test Data. An index directory path should be created as E:\Lucene\Index. After running the indexing program during chapter Lucene - Indexing Process, you can see the list of index files created in that folder.
Running the Program:
Once you are done with creating source, creating the raw data, data directory, index directory and indexes, you are ready for this step which is compiling and running your program. To do this, Keep LuceneTester.Java file tab active and use either Run option available in the Eclipse IDE or use Ctrl + F11 to compile and run your LuceneTester application. If everything is fine with your application, this will print the following message in Eclipse IDE's console:
10 documents found. Time :31msScore: 1.3179655 File: E:\Lucene\Data\record3.txtScore: 0.790779 File: E:\Lucene\Data\record1.txtScore: 0.790779 File: E:\Lucene\Data\record2.txtScore: 0.790779 File: E:\Lucene\Data\record4.txtScore: 0.790779 File: E:\Lucene\Data\record5.txtScore: 0.790779 File: E:\Lucene\Data\record6.txtScore: 0.790779 File: E:\Lucene\Data\record7.txtScore: 0.790779 File: E:\Lucene\Data\record8.txtScore: 0.790779 File: E:\Lucene\Data\record9.txtScore: 0.2635932 File: E:\Lucene\Data\record10.txt10 documents found. Time :0msScore: 0.790779 File: E:\Lucene\Data\record1.txtScore: 0.2635932 File: E:\Lucene\Data\record10.txtScore: 0.790779 File: E:\Lucene\Data\record2.txtScore: 1.3179655 File: E:\Lucene\Data\record3.txtScore: 0.790779 File: E:\Lucene\Data\record4.txtScore: 0.790779 File: E:\Lucene\Data\record5.txtScore: 0.790779 File: E:\Lucene\Data\record6.txtScore: 0.790779 File: E:\Lucene\Data\record7.txtScore: 0.790779 File: E:\Lucene\Data\record8.txtScore: 0.790779 File: E:\Lucene\Data\record9.txt
- Lucene - Overview
- Overview
- Overview
- Overview
- Overview
- overview-overview
- lucene
- Lucene
- lucene
- lucene
- Lucene
- lucene
- lucene
- lucene
- Lucene
- Lucene
- lucene
- Lucene
- 关于Android开发中导出jar包后的资源使用问题解决
- SWIFT是什么意思?
- jquery flot 画柱状图
- First集Follow集通俗易懂的讲解加实例
- 5个典型的JavaScript面试题
- Lucene - Overview
- 1155. Can I Post the lette
- 【BZOJ】【P1976】【BeiJing2010组队】【能量魔方 Cube】【题解】【最小割】
- Zxing调整扫描区域 优化取图速度
- 用Drawerlayout来实现侧滑效果
- snprintf比sprintf好,那么strncpy就比strcpy好?!
- python特殊语句
- 【MongoDB for Java】Java操作MongoDB
- 课程设计


