一些重要struct
来源:互联网 发布:人工智能 中科院 编辑:程序博客网 时间:2024/05/29 16:34
//+++++++++++struct列表+++++++++++++++++++++++++++++++++++++++++++
struct mm_struct ;struct vm_area_struct
/*这个参考《深入理解LINUX内存管理》学习笔记 */
typedef struct pglist_data;
struct zone;
struct page;
//++++++++++++以下是个struct的详细解析++++++++++++++++++++++++++++++++++
//struct mm_struct 可以由
current->mm
或者
task = get_proc_task(file->f_path.dentry->d_inode); //get_pid_task(proc_pid(inode), PIDTYPE_PID);
mm = get_task_mm(task);
得到。
struct mm_struct{struct vm_area_struct * mmap;/* 这个链表链接了属于这个内存描述符的所有 vm_area_struct 结构体。*/struct rb_root mm_rb; /* 由于属于一个内存描述符的内存区域可能非常多,为了加快内存区域的查找以及添加删除等操作的速度,内核用 mm_rb 表示一棵链接了所有内存区域的红黑树。*/ /*mmap 和 mm_rb 是用两种不同的数据结构表示同一批数据。*/ struct vm_area_struct * mmap_cache;;/* 指向最后一个引用的线性区对象*/#ifdef CONFIG_MMU /* 在进程地址空间中搜索有效线性地址区间的方法 */unsigned long (*get_unmapped_area) (struct file *filp,unsigned long addr, unsigned long len,unsigned long pgoff, unsigned long flags);#endifunsigned long mmap_base;/* base of mmap area */unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */unsigned long task_size;/* size of task vm space */unsigned long highest_vm_end;/* highest vma end address */pgd_t * pgd; /* 指向页全局目录 */ atomic_t mm_users; atomic_t mm_count;/*每一个进程如果拥有一个内存描述符,则会增加 mm_users 的计数,所有 mm_users 的计数只相当于 mm_count 的一个计数。比如n 个 Linux 线程共享同一个内存描述符,那么对应的内存描述符的 mm_users 计数则为n,而 mm_count 则可能只是 1。如果有内核执行序列想要访问一个内存描述符,则该执行序列先增加 mm_count 的计数,使用结束后减少 mm_count 的计数。一但mm_count 减为 0,表示该内存描述符没有任何引用,则它会被内核销毁。*/ int map_count;/* number of VMAs */ /* 线性区的个数 */spinlock_t page_table_lock;/* Protects page tables and some counters */ struct rw_semaphore mmap_sem;/*mmap_sem 是一个读写锁,凡是需要操作内存描述符中的内存区域时,则需要先得到相应的读锁或者写锁,使用结束后释放该锁*/struct list_head mmlist;/* List of maybe swapped mm's.These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock *//*mm_list 字段是一个循环双链表。它链接了系统中所有的内存描述符。*/unsigned long hiwater_rss;/* High-watermark of RSS usage */ /* 进程所拥有的最大页框数 */unsigned long hiwater_vm; /* 进程线性区中的最大页数 */unsigned long total_vm;/* Total pages mapped */unsigned long locked_vm;/* Pages that have PG_mlocked set */ /*"锁住"而不能换出的页的个数*/unsigned long pinned_vm;/* Refcount permanently increased */unsigned long shared_vm;/* Shared pages (files) */ /*共享文件内存映射中的页数*/unsigned long exec_vm;/* VM_EXEC & ~VM_WRITE */ /*可执行内存映射中的页数*/unsigned long stack_vm;/* VM_GROWSUP/DOWN */ /*用户态堆栈中的页数*/unsigned long def_flags;unsigned long nr_ptes;/* Page table pages */unsigned long start_code, end_code, start_data, end_data; /*代码段的起始地址,代码段的最后地址,数据段的起始地址和数据段的最后的地址*/unsigned long start_brk, brk, start_stack;/*堆的起始地址,堆的当前最后地址,用户态堆栈的起始地址*/ unsigned long arg_start, arg_end, env_start, env_end;/*命令行参数的起始地址,命令行参数的最后地址,环境变量的起始地址,环境变量的最后地址*/unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */ /* 开始执行ELF程序时会使用到saved_auxv参数 *//* * Special counters, in some configurations protected by the * page_table_lock, in other configurations by being atomic. */struct mm_rss_stat rss_stat;struct linux_binfmt *binfmt;cpumask_var_t cpu_vm_mask_var;/* Architecture-specific MM context */mm_context_t context;unsigned long flags; /* Must use atomic bitops to access the bits */struct core_state *core_state; /* coredumping support */#ifdef CONFIG_AIOspinlock_tioctx_lock;struct hlist_headioctx_list;#endif#ifdef CONFIG_MM_OWNER/* * "owner" points to a task that is regarded as the canonical * user/owner of this mm. All of the following must be true in * order for it to be changed: * * current == mm->owner * current->mm != mm * new_owner->mm == mm * new_owner->alloc_lock is held */struct task_struct __rcu *owner;#endif/* store ref to file /proc/<pid>/exe symlink points to */struct file *exe_file;#ifdef CONFIG_MMU_NOTIFIERstruct mmu_notifier_mm *mmu_notifier_mm;#endif#ifdef CONFIG_TRANSPARENT_HUGEPAGEpgtable_t pmd_huge_pte; /* protected by page_table_lock */#endif#ifdef CONFIG_CPUMASK_OFFSTACKstruct cpumask cpumask_allocation;#endif#ifdef CONFIG_NUMA_BALANCING/* * numa_next_scan is the next time that the PTEs will be marked * pte_numa. NUMA hinting faults will gather statistics and migrate * pages to new nodes if necessary. */unsigned long numa_next_scan;/* numa_next_reset is when the PTE scanner period will be reset */unsigned long numa_next_reset;/* Restart point for scanning and setting pte_numa */unsigned long numa_scan_offset;/* numa_scan_seq prevents two threads setting pte_numa */int numa_scan_seq;/* * The first node a task was scheduled on. If a task runs on * a different node than Make PTE Scan Go Now. */int first_nid;#endif#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)/* * An operation with batched TLB flushing is going on. Anything that * can move process memory needs to flush the TLB when moving a * PROT_NONE or PROT_NUMA mapped page. */bool tlb_flush_pending;#endifstruct uprobes_state uprobes_state;};//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
struct vm_area_struct { struct mm_struct * vm_mm; /*指向该 VMA 属于的内存描述符。*/ unsigned long vm_start; /*虚拟区开始的地址*/ unsigned long vm_end; /*虚拟区结束的地址,但不包括 vm_end 指向的地址,即vm_end 是虚拟内存区域的最后一个有效字节的后一个字节。*/ struct vm_area_struct *vm_next;/*链接虚存区*/ pgprot_t vm_page_prot; /*虚存区的保护权限*/ unsigned long vm_flags; /*虚存区的标志*/ short vm_avl_height;/*AVL的高度*/ struct vm_area_struct * vm_avl_left; /*左虚存区节点*/ struct vm_area_struct * vm_avl_right;/*右虚存区节点*/ struct vm_area_struct *vm_next_share; struct vm_area_struct **vm_pprev_share; struct vm_operations_struct * vm_ops;/*对虚存区操作的函数*/ unsigned long vm_pgoff; /* 映射文件中的偏移量*/ struct file * vm_file;/*vm_file 是该内存区域对应的文件,如果内存区域是匿名的,则该字段被置为 NULL。*/ unsigned long vm_raend;/ voidvoid * vm_private_data; /*指向内存区的私有数据*/ }; //++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
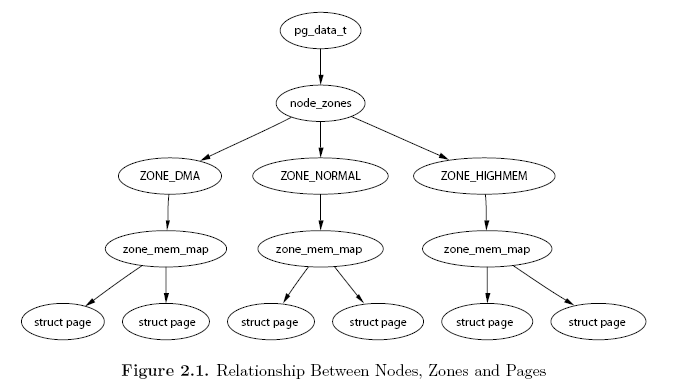
typedef struct pglist_data {struct zone node_zones[MAX_NR_ZONES]; /*节点中的管理区 分别为ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM*//*list中zone的顺序代表了分配内存的顺序,前者分配内存失败将会到后者的区域中分配内存;当调用free_area_init_core()时,由mm/page_alloc.c文件中的build_zonelists()函数设置*/struct zonelist node_zonelists[MAX_ZONELISTS]; int nr_zones; /*节点中管理区的数目,不一定为3个,有的节点中可能不存在ZONE_DMA*/#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */struct page *node_mem_map; /*node中的第一个page,它可以指向mem_map中的任何一个page*/#ifdef CONFIG_CGROUP_MEM_RES_CTLRstruct page_cgroup *node_page_cgroup;#endif#endifstruct bootmem_data *bdata;/*这个仅用于boot 的内存分配*/#ifdef CONFIG_MEMORY_HOTPLUG/* * Must be held any time you expect node_start_pfn, node_present_pages * or node_spanned_pages stay constant. Holding this will also * guarantee that any pfn_valid() stays that way. * * Nests above zone->lock and zone->size_seqlock. */spinlock_t node_size_lock;#endifunsigned long node_start_pfn; /*pfn是page frame number的缩写。这个成员是用于表示node中的开始那个page在物理内存中的位置的; 该节点的起始页框编号*/unsigned long node_present_pages; /* total number of physical pages ;node中的真正可以使用的page数量*/unsigned long node_spanned_pages; /* total size of physical page range, including holes ; */int node_id; /*节点标识符,代表当前节点是系统中的第几个节点*/wait_queue_head_t kswapd_wait; /*页换出进程使用的等待队列*/struct task_struct *kswapd; /*指向页换出进程的进程描述符*/int kswapd_max_order; /*kswapd将要创建的空闲块的大小取对数的值*/}//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
struct zone {/* Fields commonly accessed by the page allocator *//* zone watermarks, access with *_wmark_pages(zone) macros */unsigned long watermark[NR_WMARK];/*该管理区的三个水平线值,min,low,high*//* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */unsigned long percpu_drift_mark;/* * We don't know if the memory that we're going to allocate will be freeable * or/and it will be released eventually, so to avoid totally wasting several * GB of ram we must reserve some of the lower zone memory (otherwise we risk * to run OOM on the lower zones despite there's tons of freeable ram * on the higher zones). This array is recalculated at runtime if the * sysctl_lowmem_reserve_ratio sysctl changes. */ /*每个管理区必须保留的页框数*/ /*为了防止一些代码必须运行在低地址区域,所以事先保留一些低地址区域的内存*/unsigned longlowmem_reserve[MAX_NR_ZONES]; #ifdef CONFIG_NUMA /*如果定义了NUMA*/int node; /*该管理区所属节点的节点号*//* * zone reclaim becomes active if more unmapped pages exist. */unsigned longmin_unmapped_pages; /*当可回收的页面数大于该变量时,管理区将回收页面*/unsigned longmin_slab_pages; /*同上,只不过该标准用于slab回收页面中*/struct per_cpu_pageset*pageset[NR_CPUS]; /*每个CPU使用的页面缓存*/#elsestruct per_cpu_pagesetpageset[NR_CPUS];#endif/* * free areas of different sizes */spinlock_tlock; /*保护该管理区的自旋锁*/#ifdef CONFIG_MEMORY_HOTPLUG/* see spanned/present_pages for more description */seqlock_tspan_seqlock;#endifstruct free_areafree_area[MAX_ORDER];/*标识出管理区中的空闲页框块; 页面使用状态的信息,以每个bit标识对应的page是否可以分配*/#ifndef CONFIG_SPARSEMEM/* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */unsigned long*pageblock_flags;#endif /* CONFIG_SPARSEMEM */ZONE_PADDING(_pad1_)/* Fields commonly accessed by the page reclaim scanner */spinlock_tlru_lock;/*(最近最少使用算法)的自旋锁*/struct zone_lru {struct list_head list;} lru[NR_LRU_LISTS]; struct zone_reclaim_stat reclaim_stat; /*页面回收的状态*//*管理区回收页框时使用的计数器,记录到上一次回收,一共扫过的页框数*/unsigned longpages_scanned; /* since last reclaim */unsigned longflags; /* zone flags, see below *//* Zone statistics */atomic_long_tvm_stat[NR_VM_ZONE_STAT_ITEMS];/* * prev_priority holds the scanning priority for this zone. It is * defined as the scanning priority at which we achieved our reclaim * target at the previous try_to_free_pages() or balance_pgdat() * invokation. * * We use prev_priority as a measure of how much stress page reclaim is * under - it drives the swappiness decision: whether to unmap mapped * pages. * * Access to both this field is quite racy even on uniprocessor. But * it is expected to average out OK. */int prev_priority;/* * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on * this zone's LRU. Maintained by the pageout code. */unsigned int inactive_ratio;ZONE_PADDING(_pad2_)/* Rarely used or read-mostly fields *//* * wait_table-- the array holding the hash table * wait_table_hash_nr_entries-- the size of the hash table array * wait_table_bits-- wait_table_size == (1 << wait_table_bits) * * The purpose of all these is to keep track of the people * waiting for a page to become available and make them * runnable again when possible. The trouble is that this * consumes a lot of space, especially when so few things * wait on pages at a given time. So instead of using * per-page waitqueues, we use a waitqueue hash table. * * The bucket discipline is to sleep on the same queue when * colliding and wake all in that wait queue when removing. * When something wakes, it must check to be sure its page is * truly available, a la thundering herd. The cost of a * collision is great, but given the expected load of the * table, they should be so rare as to be outweighed by the * benefits from the saved space. * * __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the * primary users of these fields, and in mm/page_alloc.c * free_area_init_core() performs the initialization of them. */wait_queue_head_t* wait_table; /*等待一个page释放的等待队列哈希表。它会被wait_on_page(),unlock_page()函数使用. 用哈希表,而不用一个等待队列的原因,防止进程长期等待资源。*/unsigned longwait_table_hash_nr_entries; /*散列表数组的大小*/unsigned longwait_table_bits; /*散列表数组的大小对2取log的结果*//* * Discontig memory support fields. */struct pglist_data*zone_pgdat; /*管理区所属节点 ;指向这个zone所在的pglist_data对象*/unsigned longzone_start_pfn; /*管理区的起始页框号 zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ /* * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; * * present_pages is physical pages existing within the zone, which * is calculated as: * present_pages = spanned_pages - absent_pages(pages in holes); * * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): * managed_pages = present_pages - reserved_pages; * * So present_pages may be used by memory hotplug or memory power * management logic to figure out unmanaged pages by checking * (present_pages - managed_pages). And managed_pages should be used * by page allocator and vm scanner to calculate all kinds of watermarks * and thresholds. * * Locking rules: * * zone_start_pfn and spanned_pages are protected by span_seqlock. * It is a seqlock because it has to be read outside of zone->lock, * and it is done in the main allocator path. But, it is written * quite infrequently. * * The span_seq lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. * * Write access to present_pages at runtime should be protected by * lock_memory_hotplug()/unlock_memory_hotplug(). Any reader who can't * tolerant drift of present_pages should hold memory hotplug lock to * get a stable value. * * Read access to managed_pages should be safe because it's unsigned * long. Write access to zone->managed_pages and totalram_pages are * protected by managed_page_count_lock at runtime. Idealy only * adjust_managed_page_count() should be used instead of directly * touching zone->managed_pages and totalram_pages. *//*这个地方参考free_area_init_core()*/unsigned longspanned_pages;/*管理区的大小,包括洞*/unsigned longpresent_pages;/*管理区的大小,不包括洞, 可能包含dma_reserve,以及mem_map结构提所占用的;*/unsigned long managed_pages; /* * rarely used fields: */const char*name; /*指向管理区的名称,为"DMA","NORMAL"或"HighMem"*/}//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
struct page { /* First double word block */ unsigned long flags; /*flags 字段存储了页面的状态信息,例如:表示页面刚被写了数据的脏位;该页面是否被锁定在内存中不充许置换到交换分区的标志。*//*为空表示该页属于交换高速缓存;mapping字段非空,且最低位是1,mapping字段中存放的是指向anon_vma描述符的指针,表示该页为匿名页;mapping字段非空,且最低位是0,mapping字段指向对应文件的address_space对象,表示该页为映射页;*/ struct address_space *mapping; /* If low bit clear, points to * inode address_space, or NULL. * If page mapped as anonymous * memory, low bit is set, and * it points to anon_vma object: * see PAGE_MAPPING_ANON below. */ /* Second double word */ struct { union {/*这个成员根据page的使用的目的有2种可能的含义。第一种情况:如果page是file mapping的一部分,它指明在文件中的偏移。如果page是交换缓存,则它指明在address_space所声明的对象:swapper_space(交换地址空间)中的偏移。第二种情况:如果这个page是一个特殊的进程将要释放的一个page块,则这是一个将要释放的page块的序列值,这个值在__free_page_ok()函数中设置。*/ pgoff_t index; /* Our offset within mapping. */ void *freelist; /* slub/slob first free object */ bool pfmemalloc; /* If set by the page allocator, * ALLOC_NO_WATERMARKS was set * and the low watermark was not * met implying that the system * is under some pressure. The * caller should try ensure * this page is only used to * free other pages. */ }; union {#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \ defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE) /* Used for cmpxchg_double in slub */ unsigned long counters;#else /* * Keep _count separate from slub cmpxchg_double data. * As the rest of the double word is protected by * slab_lock but _count is not. */ unsigned counters;#endif struct { union { /* * Count of ptes mapped in * mms, to show when page is * mapped & limit reverse map * searches. * * Used also for tail pages * refcounting instead of * _count. Tail pages cannot * be mapped and keeping the * tail page _count zero at * all times guarantees * get_page_unless_zero() will * never succeed on tail * pages. */ atomic_t _mapcount; //_mapcount字段存放引用页框的页表项数目,确定其是否共享; struct { /* SLUB */ unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; int units; /* SLOB */ }; atomic_t _count; /* page的访问计数,当为0是,说明page是空闲的,当大于0的时候,说明page被一个或多个进程真正使用或者kernel用于在等待I/O*//*_count 字段和_mapcount字段都是引用计数,它们用来共同维护 page 页面的生命期。_mapcount 表示一个页面拥有多少页表项指向它,_count 被称为 page 的使用计数,所有的_mapcount 计数只相当于_count 计数中的一次计数。如果内核代码中某执行序列在访问某个页面时需要确保该页面存在,则在访问前给_count 计数加一,访问结束后_count 计数减一。当_count 计数减到负数时表示没有任何内核需要使用该页面,则表示该页面没被使用。内核代码不应该直接访问_count 计数,而应该使用 page_count 函数。该函数用一个struct page 的指针做为参数,当该页空闲时函数返回 0,否则返回一个正数表示参数指向的页面正被使用。*/ }; }; }; /* Third double word block */ union { struct list_head lru; /* Pageout list, eg. active_list * protected by zone->lru_lock ! */ struct { /* slub per cpu partial pages */ struct page *next; /* Next partial slab */#ifdef CONFIG_64BIT int pages; /* Nr of partial slabs left */ int pobjects; /* Approximate # of objects */#else short int pages; short int pobjects;#endif }; struct list_head list; /* slobs list of pages */ struct slab *slab_page; /* slab fields */ }; /* Remainder is not double word aligned */ union { unsigned long private; /* Mapping-private opaque data: * usually used for buffer_heads * if PagePrivate set; used for * swp_entry_t if PageSwapCache; * indicates order in the buddy * system if PG_buddy is set. */#if USE_SPLIT_PTLOCKS spinlock_t ptl;#endif struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */ struct page *first_page; /* Compound tail pages */ }; /* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */#if defined(WANT_PAGE_VIRTUAL) void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */#endif /* WANT_PAGE_VIRTUAL */#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; /* Use atomic bitops on this */#endif struct task_struct *tsk_dirty; /* task that sets this page dirty */#ifdef CONFIG_KMEMCHECK /* * kmemcheck wants to track the status of each byte in a page; this * is a pointer to such a status block. NULL if not tracked. */ void *shadow;#endif#ifdef LAST_NID_NOT_IN_PAGE_FLAGS int _last_nid;#endif#ifdef CONFIG_PAGE_OWNER int order; gfp_t gfp_mask; struct stack_trace trace; unsigned long trace_entries[8];#endif}//++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
<span style="font-size:18px;"><span style="font-size:12px;"></span></span><pre name="code" class="objc">mapping字段
- 一些重要struct
- struct一些学习经验
- 一些重要的属性
- 一些重要的文件
- Object一些重要方法
- 一些重要的计数器
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- 一些重要的算法
- nodejs安装express
- 内存溢出攻击分析
- POJ 2253 Frogger
- Android 代码混淆及反编译方法
- Ubuntu14.04 Redmine搭建、SVN配置、以及对接
- 一些重要struct
- 蓝桥杯 入门训练 Fibonacci数列 JAVA
- 自动识别图形验证码
- apprfamework 3.0如何去掉侧导航nav的默认滚动
- Python实现mmseg分词算法和吐嘈
- 学习Emacs系列教程(八):查找替换
- [Leetcode]Longest Valid Parentheses
- android的inflate
- 黑马程序员 —— Java基础加强 - 反射


