Dom4j详解
来源:互联网 发布:羽毛球软件 编辑:程序博客网 时间:2024/04/27 19:16
先来看看dom4j中对应XML的DOM树建立的继承关系(下图及API转自Here)
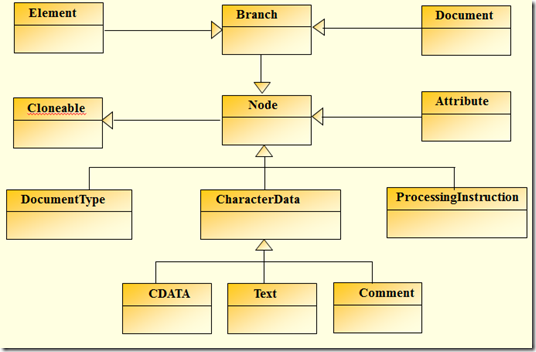
针对于XML标准定义,dom4j提供了以下实现:
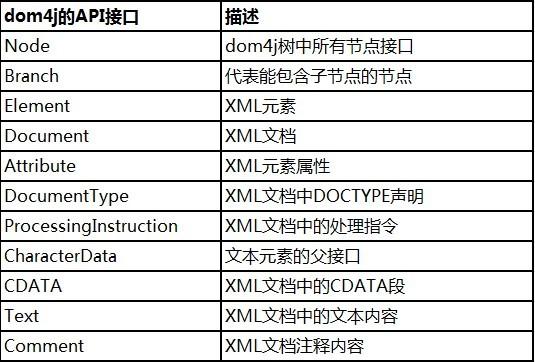
同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
- read 提供多种读取xml文件的方式,返回一个Domcument对象
interface org.dom4j.Document
- iterator 使用此法获取node
- getRootElement 获取根节点
interface org.dom4j.Node
- getName 获取node名字,例如获取根节点名称为bookstore
- getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
- getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
interface org.dom4j.Element
- attributes 返回该元素的属性列表
- attributeValue 根据传入的属性名获取属性值
- elementIterator 返回包含子元素的迭代器
- element 返回子元素节点名对应的第一个元素节点
- elements 返回包含子元素的列表
interface org.dom4j.Attribute
- getName 获取属性名
- getValue 获取属性值
interface org.dom4j.Text
- getText 获取Text节点值
看完下面的例子,就对xml拼装和拆解无所畏惧了:
拼装:
package com.test2;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;public class Foo {public static void main(String[] args) {Document doc = createDocument();System.out.println(doc.asXML());}public static Document createDocument() {Document document = DocumentHelper.createDocument();Element root = document.addElement("root");Element author1 = root.addElement("author").addAttribute("name", "James").addAttribute("location", "UK").addText("James Strachan");System.out.println("author1:" + author1.asXML());Element author2 = root.addElement("author").addAttribute("name", "Bob").addAttribute("location", "US").addText("Bob McWhirter");System.out.println("author2:" + author2.asXML());return document;}}输出:
author1:<author name="James" location="UK">James Strachan</author>
author2:<author name="Bob" location="US">Bob McWhirter</author>
<?xml version="1.0" encoding="UTF-8"?><root><author name="James" location="UK">James Strachan</author><author name="Bob" location="US">Bob McWhirter</author></root>
==================================================================
拆解:
public static void main(String[] args) {String documentXmlStr = document.asXML();// 要拆解的xml格式字符串try {Document doc = DocumentHelper.parseText(documentXmlStr);Element node = doc.getRootElement();listNodes(node);} catch (DocumentException e) {e.printStackTrace();}}public static void listNodes(Element node) {System.out.println("当前节点:" + node.getName());List<Attribute> list = node.attributes();for (Attribute attr : list) {System.out.println("属性key-value:" + attr.getName() + "-" + attr.getValue());}if (!(node.getTextTrim().equals(""))) {System.out.println("文本内容:" + node.getText());}Iterator<Element> it = node.elementIterator();while (it.hasNext()) {Element e = it.next();// 获取某个子节点对象System.out.println("==================================");listNodes(e);// 对子节点进行遍历}}输出:
当前节点:root
==================================
当前节点:author
属性key-value:name-James
属性key-value:location-UK
文本内容:James Strachan
==================================
当前节点:author
属性key-value:name-Bob
属性key-value:location-US
文本内容:Bob McWhirter
拆解->其他常用方法:
String documentXmlStr = document.asXML();try {Document doc = DocumentHelper.parseText(documentXmlStr);Element node = doc.getRootElement();Element firstAuthorEle = node.element("author");// 获取指定的子元素节点String firstAuthorEleTxt = node.elementText("author");System.out.println("First Author Element:" + firstAuthorEle.asXML());System.out.println("First Author Element Text:" + firstAuthorEleTxt);List<Element> elements = node.elements();// 获取所有子元素节点for (Element e : elements) {System.out.println("Child Element:" + e.asXML());}Iterator eleIt = node.elementIterator("author");// 类似node.elements("author")while (eleIt.hasNext()) {Element e = (Element) eleIt.next();Attribute attr = e.attribute("name");System.out.println(attr.asXML() + ":" + attr.getName() + "-" + attr.getValue() + "==" + e.attributeValue("name"));}} catch (DocumentException e) {e.printStackTrace();}输出:
First Author Element:<author name="James" location="UK">James Strachan</author>
First Author Element Text:James Strachan
Child Element:<author name="James" location="UK">James Strachan</author>
Child Element:<author name="Bob" location="US">Bob McWhirter</author>
name="James":name-James==James
name="Bob":name-Bob==Bob
==================================================================
最后,对xml文件的读写操作:
读:
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/dom4j/sida.xml"));
写:
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream(new File("src//a.xml")), "UTF-8"), format);
writer.write(document);
writer.flush(); // 立即写入
writer.close();
=========================================
注:
addAttribute("abc",var);如果var==null,相当于没有加此属性。
addText(var);如果var==null,相当于没有加此元素的text。
- DOM4J 知识详解 dom4j
- dom4j 详解
- Dom4j 详解
- Dom4j详解
- DOM4J详解
- DOM4J 知识详解
- 9、DOM4J详解
- Dom4j 使用 详解~~
- dom4j解析xml详解
- dom4j解析xml详解
- dom4j api 详解
- dom4j api 详解
- dom4j api 详解
- DOM4j解析器详解
- dom4j应用详解
- dom4j api 详解
- dom4j API详解
- dom4j的详解
- Linux 编程中的API函数和系统调用的关系
- VC获取各类指针
- linux c源码之top源码
- HTML5 Canvas 显示不出图片
- NPOI生成Excel
- Dom4j详解
- [数据结构] 图的邻接矩阵深度优先搜索
- android View图
- 南邮NOJ2029节奏大师
- uva1346(排序)
- go method使用
- HDU 1116 Play on Words(欧拉通路)
- 设计模式在游戏中的应用--简单工厂模式(一)
- 把一个Js功能块封装到一个JS对象中


