CopyOnWriteArrayList (一)
来源:互联网 发布:pos机软件 编辑:程序博客网 时间:2024/06/05 01:11
一、CopyOnWriteArrayList
制作数组的干净复本是一项成本极高的操作,在时间和内存这两方面均有开销,以至于在通常的应用中不能考虑该方法;开发者常常求助于使用同步的 ArrayList来替代前述方法。但这也是一个比较有代价的选项,因为当每次你遍历访问该集合中的内容时,你不得不同步所有的方法,包括读和写,以确保内存一致性。 在有大量用户在读取ArrayList而只有很少用户对其进行修改的这一场景中,上述方法将使成本结构变得缓慢。 CopyOnWriteArrayList就是解决这一问题的一个极好的宝贝工具。它的Javadoc描述到,ArrayList通过创建数组的干净复本来实现可变操作(添加,修改,等等),而CopyOnWriteArrayList则是ArrayList的一个"线程安全"的变体。 对于任何修改操作,该集合类会在内部将其内容复制到一个新数组中,所以当读用户访问数组的内容时不会招致任何同步开销(因为它们没有对可变数据进行操作)。 本质上,创建CopyOnWriteArrayList的想法,是出于应对当ArrayList无法满足我们要求时的场景:经常读,而很少写的集合对象,例如针对JavaBean事件的Listener。
用途:读多写少,ArrayList(读 不加锁) Vector(写 加锁)
二、ConcurrentHashMap
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁。如图 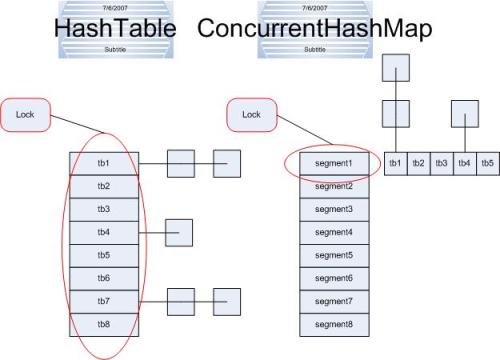
左边便是Hashtable的实现方式---锁整个hash表;而右边则是ConcurrentHashMap的实现方式---锁桶(或段)。ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器(见之前的文章《JAVA API备忘---集合》)的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
接下来,让我们看看ConcurrentHashMap中的几个重要方法,心里知道了实现机制后,使用起来就更加有底气。
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应上面的图可以看出之间的关系。
注意:
ConcurrentHashMap,不要轻易用.size(),因为它会锁整张表;
ConcurrentHashMap,不要轻易用.remove(),因为它会涉及到hashTable中该entry之前的所有元素都要进行拷贝操作(为什么要拷贝呢?因为entry除了value字段是变量外,其他都是final的,这样索引的时候不用同步,性能更快)
用途:读多写少,HashMap(读 不加锁) Hashtable(写 加锁)
三、BlockingQueue
BlockingQueue,如果BlockQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作.
使用BlockingQueue的关键技术点如下:
1.BlockingQueue定义的常用方法如下:
1)add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则招聘异常
2)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
5)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
2.BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
3.LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
BlockingQueue和Queue的区别:
1.BlockingQueue:支持两个附加操作的 Queue,这两个操作是:检索元素时等待队列变为非空,以及存储元素时等待空间变得可用。
2.BlockingQueue 不接受 null 元素。
3.BlockingQueue 可以是限定容量的。
4.BlockingQueue 实现是线程安全的。Queue不是线程安全的。因此可以将Blockingqueue用于用于生产者-使用者队列。
原地址:点击打开链接
- CopyOnWriteArrayList (一)
- 并发编程一:CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- CopyOnWriteArrayList
- wget 详细介绍
- 轮子----文本框内容不是唯一返回
- 换不开的硬币问题
- uri、url、refer
- 学习angular ui-router - 管理状态
- CopyOnWriteArrayList (一)
- 【python】python的内置函数apply()filter() reduce()map()
- RHadoop的技术性文章
- iOS开发之数组、字典、集合
- 内核编译图文教程,usb键盘鼠标篇
- /etc/profile和 . profile 文件
- Xcode 6.1 做ipa企业级分发(In-House模式)详细步骤
- 指针函数 、函数指针 、 回调函数
- 自定义ActionBar盘点---------GlassActionBar


