HDFS新特性Centralized Cache Management介绍
来源:互联网 发布:snmp网络拓扑发现 编辑:程序博客网 时间:2024/06/03 11:15
概述
HDFS作为Hadoop底层存储架构实现,提供了高可容错性,以及较高的吞吐量等特性。在Hadoop 2.3版本里,HDFS提供了一个新特性——Centralized Cache Management。该特性能够让用户显式地把某些HDFS文件强制映射到内存中,防止被操作系统换出内存页,提高内存利用效率,有效加快文件访问速度。对于Hive来说,如果对某些SQL查询里需要经常读取的表格文件进行缓存,通常能够提升运行效率。
架构介绍
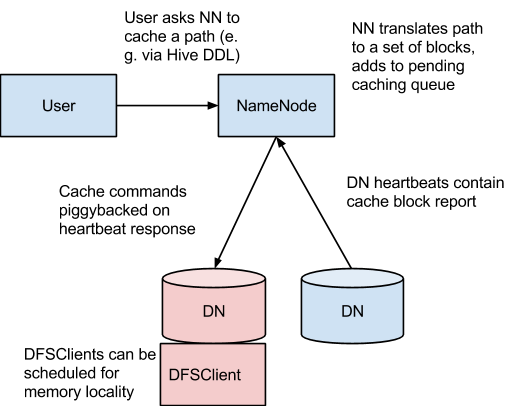
NameNode主要负责协调所有DataNode的堆外内存。DataNode会按照一定的时间间隔通过heartbeat向NameNode汇报所缓存的文件block块记录。NameNode会接收用户缓存或清空某个路径的缓存命令,然后通过heartbeat通知含有对应文件block的DataNode进行缓存。
NameNode提供一个缓存池(cache pools)来方便管理缓存命令(cache directives),缓存命令负责决定具体进行缓存的路径。
目前缓存只能够在文件夹或者文件的粒度进行控制。文件块和子块缓存仍然在计划开发中。
缓存命令接口
具体用法和参数意义参见官网介绍,这里只作简单介绍。
Cache directive命令
addDirective
添加一个新的cache directive。如: hdfs cacheadmin -addDirective -path <path> -pool <pool-name>
- removeDirective
移除一个cache directive。如:hdfs cacheadmin -removeDirective <id>
removeDirectives
移除指定路径的每个cache directive。如:hdfs cacheadmin -removeDirectives <path>
listDirectives
列出cache directive。如: hdfs cacheadmin -listDirectives
Cache pool命令
addPool
添加新的内存池。如:hdfs cacheadmin -addPool <name>
modifyPool
修改缓存池的metadata。如:hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
removePool
移除缓存池,同时也会移除在缓存池里的路径。如: hdfs cacheadmin -removePool <name>
listPools
显示缓存池信息。如:hdfs cacheadmin -listPools [-stats] [<name>]
实践与思考
上面的内容基本从官网简单摘取过来,这节才是本文章的重点,也是真正的干货所在。
首先要注意的是,官网没有说明的一点,要读取到cache到内存的文件block,必须要首先开启Short-Circuit Local Reads特性。该特性简单来说,就是对于在读取文件位于相同节点的时候,能够避免建立TCP socket,直接读取位于磁盘上的文件block。需要注意的是,该特性有两种不同实现方案(HDFS-2246和HDFS-347),其中,HDFS-347是Hadoop 2.x的重新实现方案,并且只有这个方案才可以读取Cache到内存的文件block。
在配置Cache的过程中,由于DataNode需要强制锁定文件映射到内存中,需要设置hdfs-site.xml参数dfs.datanode.max.locked.memory参数(单位bytes)。另外要注意的是通常还需要更改操作系统参数ulimit -l(单位KB),否则DataNode在启动的时候会抛出异常。
为了能够更加深入理解这个特性带来的性能影响,在测试环境下进行了简单的测试。
测试环境是一个有3个节点的小集群。2个NameNode(启用NameNode HA特性),3个DataNode。其中Active NameNode(93)总共有12G内存,8个Intel(R) Xeon(R) CPU 2.50GHz;另外backup NameNode(24)和DataNode(25)均只有4GB内存,4个Intel(R) Xeon(R) CPU 2.00GHz。
为了能够减少干扰,更加清晰地了解该特性带来的性能变化,并且注意到要使用该特性,必须使用一个全新的API来进行读取操作,因此写了一个简单的读HDFS文件的测试程序来测量耗时。
对于一个约400MB大小的HDFS文件,进行读取,得出数据如下:
1137
117025275112641199从上面数据可以看到,开启了Short-Circuit特性的时候,读取文件至少快了2-3倍;当启用Centralized Cache Management特性的时候,读取文件并没有太大的速度提升。
关于这个Cache Management不甚明显的原因,查找相关资料(interactive-hadoop-via-flash-and-memory.pptx),可能说明了部分问题的原因:开启了Short-Circuit本地读取后,操作系统可能会在读取的过程中同时缓存文件到内存里,但是,如果此时节点内存使用比较紧张的时候(可能由于多个MR子任务的执行),操作系统可能会随时把这些缓存换出,导致缓存无效。使用Cache Management显式指定文件缓存后,可以保证该部分内存不被换出,同时由于使用的是off-heap memory,免于JVM的管理,避免产生GC。
因此考虑到目前测试环境上的仅仅执行简单测试,没有模拟出激烈的内存使用情况,可能导致效果不甚明显。
另外,还尝试过做Hive、HBase的读取测试,无论是开启Short-Circuit还是Short-Circuit + Centralized Cache Management都暂时没有发现太大的性能提升,暂时怀疑是由于测试环境的节点实在太少,而且其中两个节点的4G内存实在少得可怜,开启任务后,空闲情况下只有5-600MB可用,而这两个特性极度依赖于内存的使用情况,因此没有办法体现出真正的性能提升优势。
当然,这只是一个推论,最好的做法还是,待仔细查看源码理解具体实现,明白更加深层次的原因。
源代码实现分析(Hadoop 2.6.0)
(1)DataNode把文件block进行缓存并锁定内存
NameNode向DataNode请求把对应的HDFS的文件block进行cache的时候,DataNode将接收到的RPC命令是DatanodeProtocol.DNA_CACHE。然后会调用FsDataSetImpl.cache()把所有请求block块进行缓存。接着调用cacheBlock()把每个Block进行逐个缓存。
FsDataSetImpl.cacheBlock()函数主要是把每个block的缓存任务分配到每个Volume的线程中异步执行。通过找到对应的Volume后,其会调用FsDatasetCache.cacheBlock()进行具体的异步缓存任务执行。
FsDatasetCache.cacheBlock()主要负责进行缓存异步任务提交。为了追踪缓存异步任务执行结果,首先把block id封装成ExtendedBlockId对象,然后放入到mappableBlockMap里,同时更新状态为CACHING。接着向FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务。
CachingTask主要负责把具体的文件Block进行缓存和锁定。具体缓存和锁定的操作会调用MappableBlock.load()执行。然后把返回的MappableBlock保存到 FsDatasetCache的mappableBlockMap中,同时更新状态为Cached(如果之前状态为CACHING_CANCELLED时,则不会保留),并且更新引用计数。
MappableBlock.load主要是调用FileChannelImpl.map和POSIX.mlock(最终会调用到libc的mmap和mlock),同时进行文件块校验。然后返回新建MappableBlock对象。
(2)客户端HDFS读逻辑
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。short circuit read就是直接读取本地文件。zero-copy read就是在short circuit read基础上,直接读取之前缓存了的文件block内存。
这里给出一个利用新API进行zero-copy read的例子。
为了能够进行short circuit read和zero-copy read,需要采用指定的API——ByteBuffer read(ByteBufferPool bufferPool,int maxLength, EnumSet<ReadOption> opts)。在调用函数FileSystem.get获取具体的FileSystem子类(如果是HDFS,则是DistributedFileSystem),会创建DFSClient对象,DFSClient对象内部封装了ClientProtocol对象,负责和NameNode进行RPC通信,获取需要读取的block信息。
FSDataInputStream.read()函数负责HDFS文件block读逻辑处理。真正的实现在DFSInputStream.tryReadZeroCopy()函数里。具体主要调用BlockReader.getClientMmap()函数,如果是开启了short circuit read特性,则具体调用的是BlockReaderLocal.getClientMmap()。getClientMmap()会调用到ShortCircuitCache.getOrCreateClientMmap(),函数实现会查看缓存是否已经进行过MMap过的文件block块信息。如果不存在,则会调用ShortCircuitReplica.loadMmapInternal(),然后最终会调用到FileChannelImpl.map(),如果之前进行过文件缓存,并mmlock锁定,则这里就会把具体的物理内存映射到本进程的虚拟内存地址空间中,如果没有,则会重新读取文件进行mmap操作。
可见,HDFS的这个zero copy read特性有一定限制,需要在本地上有需要读取的block块数据,也就是同样需要考虑data-lock限制,因此综合来看,主要是针对short circuit read的性能提升。目前的情况是在测试环境下,short circuit read时开启后有较大的性能提升,zero copy read对比起short circuit read暂时没有太大的明显变化。
- HDFS新特性Centralized Cache Management介绍
- HDFS centralized cache management
- HDFS缓存集中管理特性:Centralized Cache Management
- Centralized Cache Management in HDFS
- Centralized Cache Management in HDFS
- HDFS中的集中缓存(Centralized Cache Management in HDFS)
- HDFS中的集中缓存 (Centralized Cache Management in HDFS)
- HDFS集中式缓存管理(Centralized Cache Management)
- HDFS集中式缓存管理(Centralized Cache Management)
- Hadoop浅解Centralized Cache Management(集中式缓存管理)
- javaSE 新特性介绍
- HTML5新特性介绍
- JAVA6新特性介绍
- Java6新特性介绍
- Android新特性介绍
- html5新特性介绍
- HTML5新特性介绍
- jee7 新特性介绍
- 使用C函数读取BMP格式图像
- H264 ES PS TS 流的区别
- hibernate 用spring实现jdbc事物管理
- Android常用的五大布局:LinearLayout/RelativeLayout/AbsoluteLayout/ TableLayout/FrameLayout
- 【连通图|边双连通分量+Tarjan+并查集】POJ-3694 Network(400+ms)
- HDFS新特性Centralized Cache Management介绍
- mysql定时备份脚本
- Android EGL_BAD_CONFIG error,配置EGLConfigChooser
- hdu2852 KiKi's K-Number 树状数组求第k大数
- windows下使用libxml2处理XML报文
- Hadoop 1.2.1升级2.6.0的一次崎岖之旅(包括Hive、HBase对应的升级)
- 蓝桥杯——安慰奶牛
- 通过不同的域名来访问根目录和根目录下的子目录
- hiho一下 第十五周


