计算机网络复习
来源:互联网 发布:淘宝网秋天中老年帽子 编辑:程序博客网 时间:2024/05/24 05:49
差错控制
CRC 循环冗余码
- 信息位为N位,在后面添加K位冗余位
- 已知的生成多项式是K+1位的,即若生成多项式是5位,则冗余位为4位。
- 将信息位左移K位,去除以生成多项式对应的二进制码,得到K位余数,此时得到CRC码为N位信息位+K位余数冗余位。注意除法中的减法不借位。
- 客户端接收到的码字除以生成多项式对应的二进制代码,能整除则无错,否则就有错。
例子:
已知信息位为1100,生成多项式为
解:
生成多项式是4位的,因此冗余位为3位。将信息位左移三位,得到
1100000 // 左移三位,低位补0用1100000除以生成多项式对应的二进制代码1011,注意除法中的减法不会借位。得到的结果商为1110,余数为010。因此,CRC码为
1100010 // 将余数替换左移的那三位数字它是检错码,检验的方法也很简单,在接收端接收到的完整CRC码,去除以生成多项式对应的二进制码,若整除则无错,否则就有错。
海明码
若信息位为K位,增加R位冗余位,需要满足关系式
比如4位信息位,满足关系式的最小R位3。
下面是比较tricky的海明码的生成算法:
假设信息位为
10101011 // 从左到右分别编号为D8, D7, ... D1根据关系式,满足不等式的最小R为4,即需要4位冗余位。我们将冗余位标记为P1, P2, P3, P4。冗余位要放置在1, 2, 4, 8, 16, 32, 64..即
现在,需要计算冗余位的数据。计算方法为将数据位所在位置用冗余位的位置关系来表示(即用1,2,4,8..来表示)
Index(D1) = 3 = 1 + 2 Index(D2) = 5 = 1 + 4 Index(D3) = 6 = 2 + 4 Index(D4) = 7 = 1 + 2 + 4 Index(D5) = 9 = 1 + 8Index(D6) = 10 = 2 + 8Index(D7) = 11 = 1 + 2 + 8Index(D8) = 12 = 4 + 8根据这种位置上的关系,可以看到P1出现在D1,D2,D4,D5,D7中,因此
P1 = D1 ^ D2 ^ D4 ^ D5 ^ D7 = 1// 同理可得P2 = D1 ^ D3 ^ D4 ^ D6 ^ D7 = 1P3 = D2 ^ D3 ^ D4 ^ D8 = 1P4 = D5 ^ D6 ^ D7 ^ D8 = 0将P1~P4带入,得到海明码为
101001011111进行校验时,假设D1出现差错,则
P1 ^ D1 ^ D2 ^ D4 ^ D5 ^ D7 = 1P2 ^ D1 ^ D3 ^ D4 ^ D6 ^ D7 = 1P3 ^ D2 ^ D3 ^ D4 ^ D8 = 0P4 ^ D5 ^ D6 ^ D7 ^ D8 = 0得到的结果为0011,表示数字3,对应的刚好是数据位D1,即可纠错。
拥塞控制
网络层的拥塞控制
两种方法:
1. 闭环控制:事先考虑拥塞原因,尽量避免拥塞的静态预防法
2. 开环控制:基于反馈环路的概念,检测拥塞的产生并处理,是一种动态的方法。
传输层的拥塞控制
发送方有拥塞窗口进行拥塞控制,窗口动态变化,只要未拥塞,窗口就增大,只要拥塞,窗口就减小。控制算法如下图所示

- 慢开始:拥塞窗口从1开始成指数增长,达到阀值后开始拥塞避免算法
- 拥塞避免:窗口线性增长,直到出现拥塞。此时修改阀值=当前窗口/2,重新从慢开始开始。
此时,发送窗口的实际大小由接收窗口和拥塞窗口共同控制,取他们的最小值。
流量控制
数据链路层的流量控制
基于滑动窗口的流量控制方式。
- 发送方维持一组允许发送的帧序号,称为发送窗口。其大小表示在未收到确认的情况下,最多允许发送的帧数目。若发送窗口为空,则表示停止发送。
- 接收方维持一组允许接收的帧序号,称为接收窗口。只有在接受窗口中的帧才能接收,其他的则全部丢弃。
- 发送窗口只有接收到确认后,才能滑动一个帧的距离;接收窗口只有收到帧并发送一个确认后,才能移动一个帧的距离。因此,只有接受窗口先移动,发送窗口才能移动。
数据链路层中的停等协议,回退N协议和选择重传协议只是在发送、接收窗口大小上有差异。
- 停等协议相当于发送=1,接收 = 1
- 回退N协议相当于发送>1, 接收 = 1
- 选择重传协议相当于发送>1,接收>1
数据链路层的窗口大小是固定的。
传输层的流量控制
传输层的流量控制也是使用滑动窗口协议,原理上跟上面的相同,不同之处在于传输层的滑动窗口大小是可变的。
在接收方,根据自己接收的缓存的大小,动态的更新发送方的窗口大小,即窗口字段,表示接收方能接收的最大字节数目。发送方根据窗口字段限制自己发送窗口的大小。
发送窗口的实际大小取拥塞窗口和接收窗口中的最小值。
数据在各层当中的封装

路由算法
RIP:基于距离-矢量算法(基于UDP)
路由信息协议
- 距离也称为路由器的跳数。跳数为0表示直接连接。RIP认为跳数越少越好。
- 每隔30秒就跟相邻节点之间交换路由表。一开始的时候每个节点都只知道相邻节点的路由信息,一次广播后就能知道跳数为1的路由,N次广播后就能知道整个网络的路由,最终是收敛的。
- 跳数最大为16,即最多只能经过15个路由器,再多的话就被标记为不可达。
例子:
- A收到B发过来的RIP报文
<C, 3>,A将该报文修改为<C, 4> - 若A中没有C,则插入;若A中到C的跳数大于4,则更新为A经过B可达到C,距离为4。
- 若某个节点180秒没有更新过,则修改为16(不可达)。
缺点:
- 每次更新需要发送全部路由表,占用带宽大
- 网络出现故障时,收敛速度慢。
OSPF:基于链路状态路由算法(基于IP)
开放最短路径优先协议
- 使用泛洪法,向本域内所有路由器广播更新信息,而不只是相邻节点。
- 广播的是临近节点的链路状态,而不是整个路由表。
- 只有改变时才更新,而不是定时更新,收敛速度快。
- 每个路由器使用dijkstra算法计算最短路径,只需要保存下一跳,不需要保存完整路径。
BGP:基于路径-矢量算法(基于TCP)
边际网关协议,用于不同自治域之间的路由信息交换。
- 由BGP发言人建立TCP链接,交换路由信息,然后各个自治域就能找到到达对方的最短路由。
- BGP是各个自治域之间的路由交换,交换数量相比域内小很多。
- 路由表中,需要记录网络号前缀,下一跳的路由,以及中间可能经过的其他域的序列。
- 同样是有变化时才交换变化的部分,节省带宽。
IP数据报

- 标识、标志和片偏移用于IP分片,当IP数据报大于数据链路层能传输的最大数据单元的时候,就需要分片。
- 生存时间即TTL。每经过一个路由器TTL-1。当TTL等于0的时候,该报文就会被丢弃。
- 注意:校验和只是校验IP首部,不会去校验数据部分。
- 协议字段中,6表示TCP,17表示UDP。
TCP报文

- 序号以数据字节为单位(不含头部),比如序号301,数据100B,下个序号就从401开始。
- 确认号为N,表示N-1的数据包都已经收到。
- 数据偏移以4B为单位,比如偏移为15,表示数据部分在60B之后,也相当于首部大小为60B。
- 窗口用于滑动窗口协议的流量控制。如序号701,窗口大小1000,表示可以接受701~1700之间的报文。
- 检验和会校验头部和数据部分,此处跟IP的校验和不同。校验时会在TCP的头部前面添加12B的伪首部,然后进行校验和计算。
UDP报文

- UDP长度至少是8B,即只有首部。
- 校验和跟TCP的一样,也是校验首部和数据。校验时也需要添加12B的伪首部,再进行校验和计算。
TCP链接管理
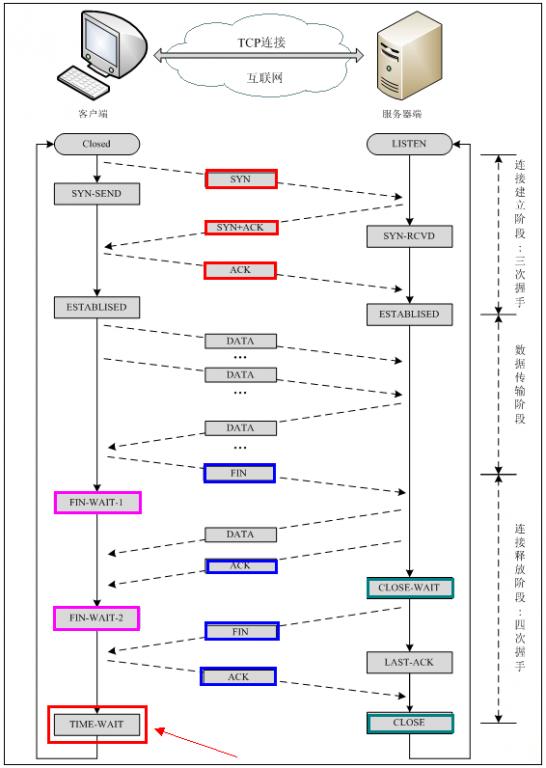
三次握手
- 客户端发送请求报文,设置初试序号,SYN=1,序号=x,状态=SYN-SEND。(第一次握手)
- 服务端接收报文,分配资源,发送确认,SYN=1,ACK=1,序号=y,确认号=x+1,状态=SYN-RCVD。(第二次握手)
- 客户端接收确认,发送确认,SYN=1,ACK=1,序号=x+1,确认号=y+1,状态=ESTABLISHED。(第三次握手)
- 服务端收到确认后,状态也变为ESTABLISHED,开始数据传输。
四次放手
- 客户端发送连接释放报文,FIN=1,序号=u,状态=FIN-WAIT1(第一次放手)
- 服务端接收到报文,ACK=1,序号是v,确认号是u+1,此时进入半连接状态,状态=CLOSE-WAIT。(第二次放手)
- 客户端接收到ACK之后,状态=FIN-WAIT2
- 服务端数据传输完毕之后,发送结束报文,FIN=1,ACK=1,确认号是u+1,序号是w(序号不是v+1是因为关闭前可能又传输若干数据)。状态=LAST-ACK。(第三次放手)
- 客户端接收到FIN之后,发送最后的ACK=1,序号=u+1,确认号=w+1,状态=TIME-WAIT,等待2MSL之后状态=CLOSED。(第四次放手)
- 服务端接收到ACK之后,状态=CLOSED。
应用层协议
在浏览器的地址栏中输入网站域名并回车后,都发生了哪些?
- url为http://www.blabla.com,浏览器分析url,使用http协议进行解析。
- 浏览器在本机DNS缓存中查找域名对应的ip,如果没查找到,则向DNS服务器发送DNS请求(基于UDP),最终得到域名对应的ip地址。
- 浏览器使用默认端口80,向该ip地址建立TCP链接,发送HTTP GET请求。
- 服务器检测GET请求,按照内部逻辑返回对应的状态码(200,301,302,304,400,401,404,500)。
- 假设服务器返回状态码200,将默认页面index.html返回给浏览器,浏览器按照http协议解析response,然后根据响应的内容决定如何去渲染(image,xml,html等)。
- 浏览器将渲染后的结果显示给用户,并在浏览器中缓存一部分数据。
DNS是如何解析的?
- www.abc.com从左到右依次是三级域名,二级域名和顶级域名。
- 全球13个跟域名服务器负责顶级域名管理。但是他们并不负责域名解析,而是给出应该去查询哪个顶级域名服务器。
域名解析过程如下: 
1. 首先向本地域名服务器进行域名解析(我们填ip地址时的域名服务器地址)。
2. 如果没查到,则本地域名服务器会向跟域名服务器进行迭代查找,跟服务器返回顶级域名服务器地址
3. 本地域名服务器向顶级域名服务器查找,若顶级域名服务器找不到,则给出授权域名服务器地址。
4. 本地域名服务器向授权域名服务器查找,若找到则缓存并返回对应ip,否则返回DNS解析失败。
- [复习]计算机网络
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习
- 计算机网络复习系列:计算机网络体系结构
- 《计算机网络》基础知识复习
- 复习计算机网络【1】
- 《计算机网络基础》复习提纲
- 计算机网络复习重点
- 计算机网络--专业课复习
- 计算机网络复习要点
- 计算机网络复习选择题练习题
- Eclipse 快捷键
- 批量修改文件内容
- 看数据结构写代码(52) 广义表的扩展线性链表存储表示
- css常识
- 几何球
- 计算机网络复习
- hdu 1709 The Balance(母函数)
- Linux中断机制之三:中断的执行
- JUNHUANGSHIJIA
- 网络安全相关站点
- linux内核链表
- 区间调度问题详解
- 简单的倒计时软件的开发过程及心得
- unity 在移动平台中,文件操作路径详解


