Scala学习笔记
来源:互联网 发布:加拿大木结构设计软件 编辑:程序博客网 时间:2024/06/04 20:10
spray
Akka
Effective Scala
Scala school
Scala tutorial for Java programmers
stackoverflow
Scala By Example
http://learnxinyminutes.com/docs/scala/
String
// 字符串中内嵌表达式,这样的字符串要以s开头val n = 10val a = Array(10, 20, 30)s"hello world $n">> res4: String = hello world 10s"hello world ${a(1)}">> res4: String = hello world 20s"hello world ${a(2) - a(0)}">> res4: String = hello world 20s"hello world ${Math.pow(n, 2)}">> res6: String = hello world 100.0// 字符串格式化,这样的字符串以f开头,且格式化字符串必须紧跟在${}后面,不能有空格f"Square root of 10: ${Math.sqrt(10)}%1.4f">> String = Square root of 10: 3.1623// 此外还有raw前缀的字符串,表示忽略字符串内的特殊字符raw"\r\t\n">> String = \r\t\n// 还有类似python中的三个引号表示多行的字符串val html = """<><>"""函数
// 递归函数需要显示声明返回类型,编译器无法进行推导函数跟方法的不同
定义两个函数
def f1(x: Int) = x + 1val f2 = (x: Int) => x + 1其中,def f1(x: Int) = x + 1整体是一个函数,而单拿出来f1只是方法。方法加上参数构成函数。函数也是对象,也有方法,比如
scala> f1 // 只输入f1的话会报错,因为它是方法<console>:9: error: missing arguments for method f1;scala> f1 _ // f1加上一个参数占位符就成了函数,它可以当作参数传递,也可以赋值给变量res31: Int => Int = <function1>scala> val y = f1 _ // 比如另y=f1(x)y: Int => Int = <function1>scala> f2 // 而f2本身就是一个函数res32: Int => Int = <function1>// 他们在使用上都是相同的scala> f1(1) res33: Int = 2scala> y(1)res34: Int = 2scala> f2(1)res35: Int = 2// 函数也是对象,函数的调用是对象的方法的调用,f2(1)是语法糖scala> f2.apply(1)res36: Int = 2// 而方法的调用就不是对象scala> f1.apply(1)<console>:9: error: missing arguments for method f1;// 也可以很容易的把一个method转化成函数scala> val y2 = f1 _y2: Int => Int = <function1>按照数学上来理解,数学上可以定义f(x)=x+1,f(x)就是函数,但是f是什么?
我们可以令y=f(x),但是不能写成y=f,我们可以写成f(g(x)) = g(x) + 1,但是不能写成f(g),除非g是一个值。
函数是一个对象,它有很多方法
class test { def m1(x:Int) = x+3 val f1 = (x:Int) => x+3}// 编译以上代码生成两个class文件:test.class and test$$anonfun$1.class.Compiled from "test.scala"public class test extends java.lang.Object implements scala.ScalaObject{ public test(); public scala.Function1 f1(); public int m1(int); public int $tag() throws java.rmi.RemoteException;}Compiled from "test.scala"public final class test$$anonfun$1 extends java.lang.Object implements scala.Function1,scala.ScalaObject{ public test$$anonfun$1(test); public final java.lang.Object apply(java.lang.Object); public final int apply(int); public int $tag() throws java.rmi.RemoteException; public scala.Function1 andThen(scala.Function1); public scala.Function1 compose(scala.Function1); public java.lang.String toString();}既然函数也是对象,函数调用其实是封装的apply的语法糖,那么是不是随便定义一个类,只要实现了apply方法,就能像调用函数一样调用对象呢?答案是肯定的。
object play{ def apply(x: Int) = 1}play(1)> res0: Int = 2Functional Combinators
map
对列表中的每个元素应用一个函数,返回应用后的元素所组成的列表。
reduce, reduceLeft, reduceRight, fold, foldLeft, foldRight, scan, scanLeft, scanRight
// reduce 默认调用的reduceLeft,其签名为def reduce[A1 >: A](op: (A1, A1) => A1): A1 = reduceLeft(op)// reduceLeft默认调用的foldLeft,其签名为def reduceLeft[B >: A](f: (B, A) => B): B = if (isEmpty) throw new UnsupportedOperationException("empty.reduceLeft") else tail.foldLeft[B](head)(f)// 与reduce类似,fold默认调用的也是foldLeftdef fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = foldLeft(z)(op)// 而foldLeft的签名以及实现是这样def foldLeft[B](z: B)(f: (B, A) => B): B = { var acc = z var these = this while (!these.isEmpty) { acc = f(acc, these.head) these = these.tail } acc }// 同理scandef scan[B >: A, That](z: B)(op: (B, B) => B) = scanLeft(z)(op)// scanLeft 声明为def scanLeft[B, That](z: B)(op: (B, A) => B)(implicit bf: CanBuildFrom[Repr, B, That]): That = { val b = bf(repr) b.sizeHint(this, 1) var acc = z b += acc for (x <- this) { acc = op(acc, x); b += acc } b.result }// 举例val tmp = List("a", "b", "c")tmp reduce (_+_)>> abctmp reduceLeft(_+_)>> abctmp.foldLeft("z")(_+_)>> zabctmp.scan("z")(_+_)>> List(z, za, zab, zabc)tmp.scanRight("z")(_+_)>> List(z, az, abz, abcz)(1 to 100).foldRight(1)(_+_)>> 5051foreach
很像map,但没有返回值。
(1 to 100) foreach( 1+ ) >> 神马都没有输出filter
(1 to 100) filter (_ % 2 == 0) >> 输出所有偶数zip
将两个列表的内容聚合到一个对偶列表中。
('a' to 'z') zip (1 to 100)>> (a,1) .... (z, 26)('a' to 'z') zip (1 to 5)>> (a,1) .. (e, 5)partition
将使用给定的谓词函数分割列表
(1 to 100) partition (_ % 2 == 0)>> (偶数,奇数)find
类似filter,只不过find只返回一个
1 to 100 filter (_ % 2 == 0)>> 2drop, dropWhile
drop i 删除前i个元素
dropWhile(lambda) 删除直到找到符合lambda的元素为止
1 to 100 drop 5>> 删除1-51 to 100 dropWhile(_ != 10)>> 删除1-9flatten, flatMap
flatten将嵌套结构扁平化为一个层次的集合, flatMap是将嵌套结构先map再flatten
List(List(1, 2), List(3, 4)).flatten>> List(1, 2, 3, 4)List(List(1, 2), List(3, 4)).flatMap(_.map(1+))>> List(2, 3, 4, 5)Map
// 创建key-value集合val m = Map("fork" -> "tenedor", "spoon" -> "cuchara", "knife" -> "cuchillo")m("fork")m("spoon")// 如果key不存在,则抛出异常m("bottle") // Throws an exception// 如果不想抛出异常,可以使用默认值val safeMap = m.withDefaultValue("sb") safeMap("111") // String = sbTuple
val t = (1, 2, "three") t._1 t._2 t._3 面向对象
Class
- 与Java,C++等语言的class一样
- 类的构造参数直接在类的后面
- 构造函数直接在类体里面
class Dog(br: String){ // 构造函数 val bark: String = br; // 默认为public def fuck() = println("What the fuck") // 声明为private private def shit(x: Int) = println("eat shit "+ x)}val dog = new dog("hi")dog.barkdog.fuck()dog.shit(1) // throw exceptionobject
类似static class,object里面的成员变量可以直接使用object名来访问
object Dog{ def fuck() = println("what the fuck") def shit(x: Int) = println(s"eat shit$x") def createDog(x: String) = new Dog(x) private def sayHi() = println("hi master")}Dog.fuck //> what the fuckDog.shit(1) //> eat shit1Dog.createDog("hi").fuck() //> What the fuckDog.sayHi() // throw exception用object可以实现工厂模式
class Car(name: String)object Car{ def apply(name: String) = new Car(name)}case class CCar(name: String)val car = Car("haha") val car2 = Car("haha") car == car2 // false val car3 = CCar("haha") val car4 = CCar("haha") car3 == car4 // true 所以可以用来模式匹配case class
class:关注于封装(encapsulation),多态(polymorphism),行为(behavior)
case class:存放不变的数据(immutable),函数无副作用(no side effect),模式匹配
abstract class Termcase class Var(name: String) extends Termcase class Fun(arg: String, body: Term) extends Termcase class App(f: Term, v: Term) extends Term// 生成实例不需要使用newprintln(Var("1")) //> Var(1)// 自动生成toString方法和equal方法println(Var("1") == Var("2")) //> falseprintln(Var("2") == Var("2")) //> true// 为构造参数自动生成get方法val t1 = App(Var("1"), Fun("2", Var("3")))t1.f //> res0: org.sample.scala1.Term = Var(1)// 模式匹配def checkTerm(t: Term): Unit = t match { case Var(v) => println(v) case Fun(v, t1) => println(v) checkTerm(t1) case App(t1, t2) => checkTerm(t1) checkTerm(t2) } checkTerm(t1) //> 1 //| 2 //| 3traits
类似于abstract class
trait Similarity { def isSimilar(x: Any): Boolean def isNotSimilar(x: Any): Boolean = !isSimilar(x)}什么时候应该使用特质而不是抽象类? 如果你想定义一个类似接口的类型,你可能会在特质和抽象类之间难以取舍。这两种形式都可以让你定义一个类型的一些行为,并要求继承者定义一些其他行为。一些经验法则:
- 优先使用特质。一个类扩展多个特质是很方便的,但却只能扩展一个抽象类。 (当interface用)
- 如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行。例如,你不能说trait t(i: Int) {},参数i是非法的。
模式匹配
注意不需要break,参考上面的模式匹配case class。
但是和switch case不同,它更强大
// 定义正则表达式val regEmail = "(.*)@(.*)".r //> regEmail : scala.util.matching.Regex = (.*)@(.*)def matchEverything(obj: Any): String = obj match{ case "fuch" => "want to fuck who?" case x: Double => s"get a double number $x" case x: Int if x > 1000 => s"get a big number $x" case Var(x) => s"get a variable $x" case regEmail(name, domain) => s"get email $name@$domain" case (x: Int, y: Double, z: String) => s"get tuble $x $y $z" case _:List[_] => "get a list" case _ => "what the fuck?"} matchEverything("123@qq.com") //> res1: String = get email 123@qq.commatchEverything(List(1, 2, 3)) //> res2: String = get a listmatchEverything("fuck") //> res3: String = want to fuck who?matchEverything(Var("1")) //> res4: String = get a variable 1For 循环
For循环可以这样描述
for([pattern <- generator; definition*]+; filter* ) [yield] expressionFor循环中,<-左侧的是一个val,而不是var。
例如
for(i <- List(1,2,3) ) {println(i)} for(i <- List(1, 2, 3) if i % 2 == 0) println(i)for(i <- List(1, 2, 3) if i != 1; if i != 2) println(i)for(i <- List(1,2,3); j <- List(3, 2, 1) ) println(i+j) 相当于for(i <- List(1,2,3)) for(j <- List(3, 2, 1)) println(i+j)在for循环中使用模式匹配
for ((name,"female") <- Set("wang"->"male","zhang"->"female") ) print(name) // zhangfor((k,v:Int) <- List(("A"->2),("B"->"C"))) {println(k)} // Ato 和 until的差别
for(i <- 1 to 10) println(i) // 输出1到10for(i <- 1 until 10) println(i) // 输出1到9隐式的(implicit)
don’t use it until you really understand it
任何val,function,object都可以声明为implicit,意为隐含变量,例如
implicit val you = "yourself" // 注意变量名跟函数的变量名是不一样的def fuck(implicit name: String) = println(s"fuck $name")fuck("me") // 正常函数调用,fuck mefuck // 隐含的,类型相同的变量you被使用,结果为fuck yourself// 如果有多个隐含的,类型相同的变量,则会报错implicit val me = "myself" fuck // 会报错,不知道应该是fuck you 还是 fuck me了有神马用?暂时还不清楚
有关import那些事
// 导入1个import scala.collection.immutable.List// 导入所有import scala.collection.immutable._// 导入多个import scala.collection.immutable.{List, Map}// 重命名导入import scala.collection.immutable.{List => FuckList}// 除了xx外导入所有import scala.collection.immutable.{Map => _, set => _, _ }泛型
参数化多态性 粗略地说,就是泛型编程,例如,如果没有参数化多态性,一个通用的列表数据结构总是看起来像这样
scala> 2 :: 1 :: "bar" :: "foo" :: Nilres5: List[Any] = List(2, 1, bar, foo)// 这样我们就丢失了类型信息scala> res5.headres6: Any = 2所以我们的应用程序将会退化为一系列类型转换(“asInstanceOf[]”),并且会缺乏类型安全的保障(因为这些都是动态的)。一个简单的例子看泛型
scala> def length[T](x: T) = x.toString().length()length: [T](x: T)Intscala> length(123)res40: Int = 3scala> length("abc")res41: Int = 3逆变,协变和不变
Scala的类型系统必须同时解释类层次和多态性。类层次结构可以表达子类关系。在混合OO和多态性时,一个核心问题是:如果T’是T一个子类,Container[T’]应该被看做是Container[T]的子类吗?
class Aclass B extends Aval b: B = new Bval a: A = b // 子类对象可以赋值给父类引用,没有问题。不变(Invariant)的例子
class Invariant[A]val f: Invariant[A] = new Invariant[B] // 这样就会报错协变(Covariant)的例子
_____ _____________ | | | || A | | List[ A ] ||_____| |_____________| ^ ^ | | _____ _____________ | | | || B | | List[ B ] ||_____| |_____________| class Covariant[+A]val f: Covariant[A] = new Covariant[B] // 这样就不会报错了逆变(Contravariant)的例子
_____ _____________ | | | || A | | List[ B ] ||_____| |_____________| ^ ^ | | _____ _____________ | | | || B | | List[ A ] ||_____| |_____________| class Contravariant[-A]val f1: Contravariant[A] = new Contravariant[B] // 这样会报错val f2: Contravariant[B] = new Contravariant[A] // 这样才不会报错,即看上去是父类泛型对象赋值给子类泛型引用。如果一个类型支持协变或逆变,则称这个类型为variance(翻译为可变的或变型),否则称为invariant(不可变的)
逆变似乎很奇怪。什么时候才会用到它呢?令人惊讶的是,函数特质的定义就使用了它!
// 函数入参和出参分别是“逆变”和“协变”的trait Function1 [-T1, +R] extends AnyRef// 所以A=>B这样的函数类型,也可以有继承关系的。class A; class B; class C extends Bval t1 = (p: A)=> new C // t1: A => C = <function1>val t2 : A => B = t1 // t2: A => B = <function1>// 函数返回类型是协变的,C是B的子类,因此A=>C可以赋值给A=>Bval t3 = (p: B)=> new A // t3: B => A = <function1>val t4 : C => A = t3 // t4: C => A = <function1>// 函数的参数类型是逆变的,C是B的子类,因此B=>A可以赋值给C=>A类型边界
泛型有逆变和协变,同样也有变化的上界和下界,这样可以用来限制泛化能力
class A { def say() = println("This is A")}class B extends A{ override def say() = println("This is B")}class C extends B{ override def say() = println("This is C")}class D extends C{ override def say() = println("This is D")}// 此时D < C < B < Aclass BaBaBa[+T<:C](x: T) { def say() = x.say()}val b: BaBaBa[B] = new BaBaBa[B](new B()) // 报错,B不满足<C的条件val c: BaBaBa[C] = new BaBaBa[C](new C()) // 没问题c.say() // This is Cval cd: BaBaBa[C] = new BaBaBa[D](new D()) // 没问题,因为它是协变的cd.say() // This is D// 换一下逆变class BiuBiu[-T <: C](x: T){ def say() = x.say()}val c: BiuBiu[C] = new BiuBiu[C](new C)c.say() // This is Cval dc: BiuBiu[D] = new BiuBiu[C](new C) // 没问题,因为它是逆变的dc.say() // This is C类型视界
类型有边界,同样也有视界,表示类型必须遵守的一些准则,继续限制泛化能力。
class Container[A <% Int] { def addIt(x: A) = 123 + x }scala> (new Container[String]).addIt("123")res11: Int = 246scala> (new Container[Int]).addIt(123) res12: Int = 246scala> (new Container[Float]).addIt(123.2F)<console>:8: error: could not find implicit value for evidence parameter of type (Float) => Int (new Container[Float]).addIt(123.2) ^异常
try{ do some stupid}catch{ case e: fuckYouException => {do something more stupid} case e: assholeException => {I mean it}}finally{ clean it up}Process
import scala.sys.process._// 运行一个命令并返回结果的状态码val result = "ls".! // result = 0val result = Process("ls").! // result = 0// 运行一个命令,并将返回值作为字符串val result = "ls -l".!! // result = String(.......)val result = Process("ls -l").!! // result = String(.......)// 得到一个process对象val p = Process("ls -l")// 在后台启动进程p.run// 运行并得到返回值val pr = p.runpr.exitValueMutable and Immutable collection
对于mutable的集合,表示对collection的修改都是in place的,这种修改作用称为side effect
对于immutable的集合,表示对collection的修改都是生成一个新的collection,而对原来的collection是不可变的,这称为no side effect。
scala.collection既包含了mutable collection也包含了immutable collection 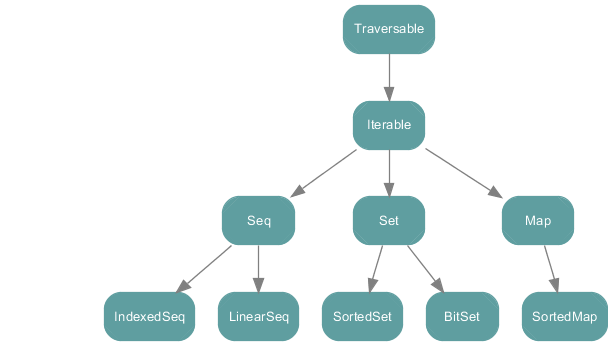
scala.collection.immutable只包含immutable collection 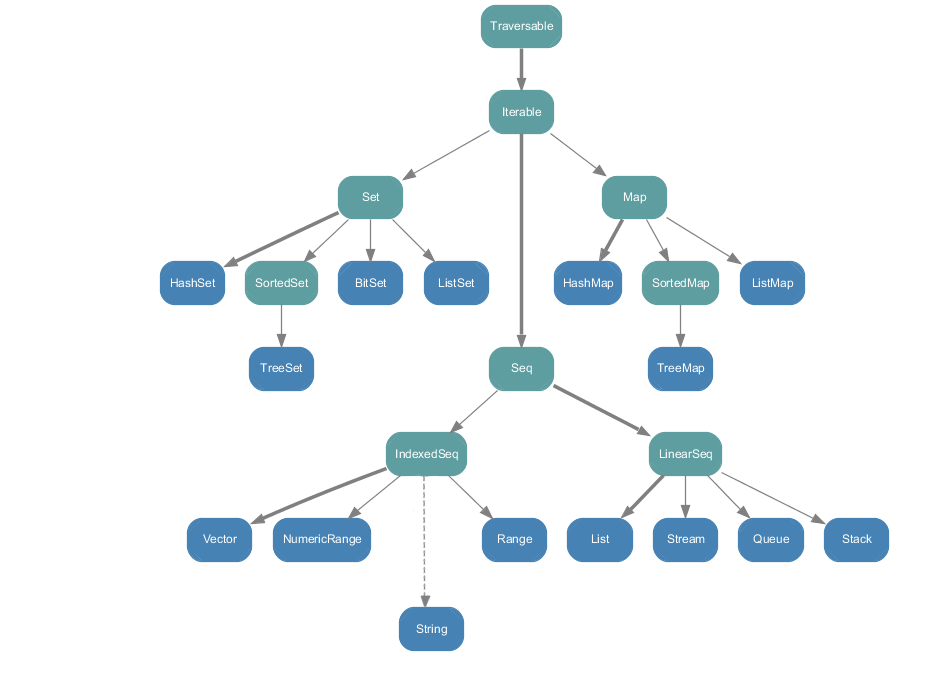
scala.collection.mutable只包含mutable collection 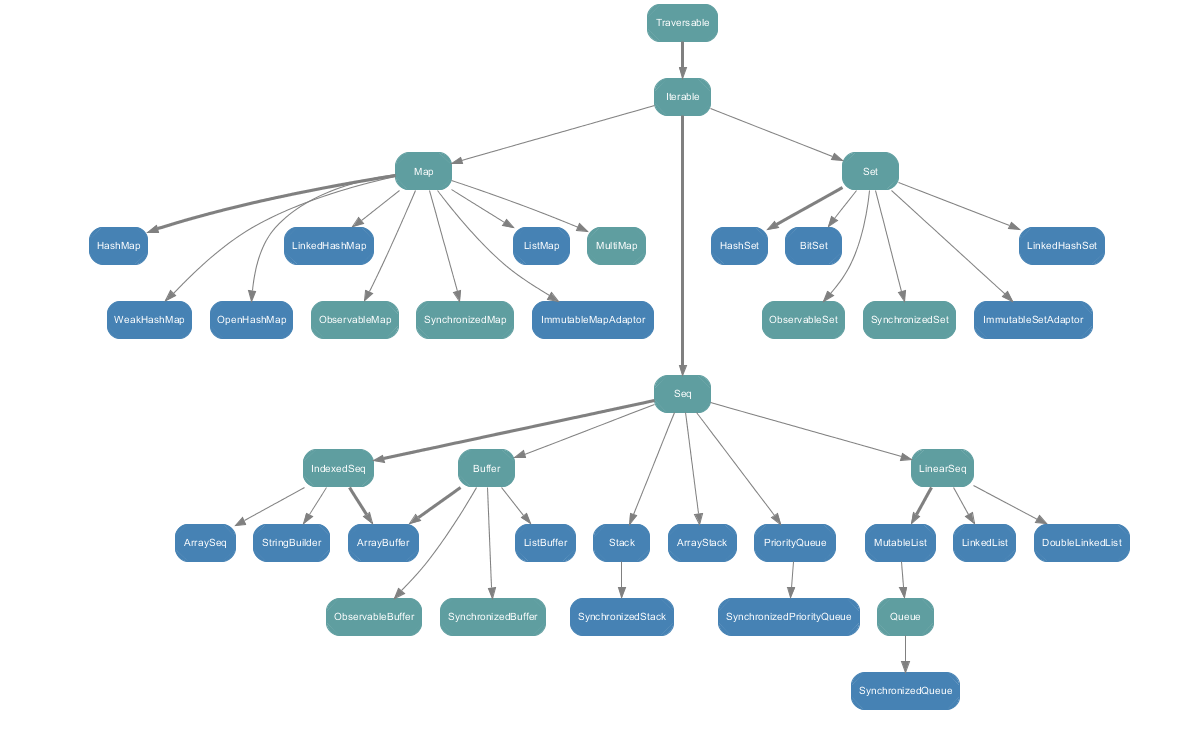
- Scala学习笔记1
- Scala学习笔记2
- scala语言学习笔记
- Scala学习笔记
- scala学习笔记01
- Scala学习笔记02
- Scala学习笔记03
- Scala学习笔记04
- scala学习笔记:集合
- scala学习笔记01
- Scala学习笔记02
- Scala学习笔记03
- Scala学习笔记04
- Scala学习笔记
- Scala开发学习笔记
- Scala学习笔记一
- Scala学习笔记二
- Scala学习笔记三
- 2015/4/18(2)
- 再读 K-Means
- poj1068
- HTML编码规范
- 向WCF服务提交Stream类型的数据
- Scala学习笔记
- Oracle数据库PL/SQL学习笔记——函数定义
- 安卓开发中用volley框架请时,中文返回乱码问题
- VI中的多行删除与复制 [转载]
- 想听懂用户的声音,至少得先学会数据分析吧
- 数学逻辑
- Mac下Lua Sublime Text2/3 开发环境搭建(补充)
- 习题7-6 重叠的正方形 UVa12113
- MatrixState的用法


