数据结构第一章 绪论
来源:互联网 发布:thunderbolt 3 端口 编辑:程序博客网 时间:2024/05/16 05:57
一、基本术语:
数据:在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。是计算机加工的原料。
数据元素:数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。一个数据元素可由若干个数据项组成。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。根据数据元素之间的不同的特性,通常有四类基本结构:集合、线性结构、树形结构、图状结构或网状结构。
数据元素之间的关系在计算机中有两种不同的表示方法:顺序映象和非顺序映象,并由此得到两种不同的存储结构:顺序存储结构和链式存储结构。
数据类型:是一个值得集合和定义在这个值集上的一组操作的总称。
数据抽象类型:是指一个数学模型以及定义在该模型上的一组操作。抽象数据类型的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关,即不论其内部结构如何变化,只要它的数学特性不变,都不影响其外部的使用。
抽象数据类型可用以下三元组表示(D,S,P),其中D是数据对象,S是D上的关系集,P是对D的基本操作集。
ADT抽象数据类型名{
数据对象:(数据对象的定义)
数据关系:(数据关系的定义)
基本操作:(基本操作的定义)
}ADT抽象数据类型名;
二、算法
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个活多个操作)
算法的五个特性:有穷性、确定性、可行性、输入、输出。
算法设计的要求:正确性、可读性、健壮性、高效率低存储
算法效率的度量:
(1)事后统计法
(2)事前分析估算的方法。一个用高级程序语言编写的程序在计算机上运行时所消耗的时间取决于以下因素:
a:依据的算法选用何种策略
b:问题的规模
c:书写程序的语言
d:编译程序所产生的机器代码的质量
e:机器执行指令的速度
一个算法是由控制结构和原操作构成的,则算法时间取决于两者的综合效果。
三、冒泡排序
转自:http://blog.csdn.net/cjf_iceking/article/details/7911027
一、算法描述
冒泡排序:依次比较相邻的数据,将小数据放在前,大数据放在后;即第一趟先比较第1个和第2个数,大数在后,小数在前,再比较第2个数与第3个数,大数在后,小数在前,以此类推则将最大的数"滚动"到最后一个位置;第二趟则将次大的数滚动到倒数第二个位置......第n-1(n为无序数据的个数)趟即能完成排序。
以下面5个无序的数据为例:
40 8 15 18 12 (文中仅细化了第一趟的比较过程)
第1趟: 8 15 18 12 40
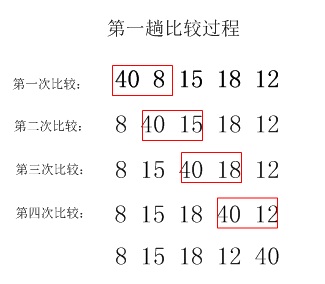
第2趟: 8 15 12 18 40
第3趟: 8 12 15 18 40
第4趟: 8 12 15 18 40
二. 算法分析
平均时间复杂度:O(n2)
空间复杂度:O(1) (用于交换)
稳定性:稳定
三. 算法实现
- //交换data1和data2所指向的整形
- void DataSwap(int* data1, int* data2)
- {
- int temp = *data1;
- *data1 = *data2;
- *data2 = temp;
- }
- /********************************************************
- *函数名称:BubbleSort
- *参数说明:pDataArray 无序数组;
- * iDataNum为无序数据个数
- *说明: 冒泡排序
- *********************************************************/
- void BubbleSort(int* pDataArray, int iDataNum)
- {
- for (int i = 0; i < iDataNum - 1; i++) //走iDataNum-1趟
- for (int j = 0; j < iDataNum - i - 1; j++)
- if (pDataArray[j] > pDataArray[j + 1])
- DataSwap(&pDataArray[j], &pDataArray[j + 1]);
- }
四. 算法优化
还可以对冒泡排序算法进行简单的优化,用一个标记来记录在一趟的比较过程中是否存在交换,如果不存在交换则整个数组已经有序退出排序过程,反之则继续进行下一趟的比较。- /********************************************************
- *函数名称:BubbleSort
- *参数说明:pDataArray 无序数组;
- * iDataNum为无序数据个数
- *说明: 冒泡排序
- *********************************************************/
- void BubbleSort(int* pDataArray, int iDataNum)
- {
- BOOL flag = FALSE; //记录是否存在交换
- for (int i = 0; i < iDataNum - 1; i++) //走iDataNum-1趟
- {
- flag = FALSE;
- for (int j = 0; j < iDataNum - i - 1; j++)
- if (pDataArray[j] > pDataArray[j + 1])
- {
- flag = TRUE;
- DataSwap(&pDataArray[j], &pDataArray[j + 1]);
- }
- if (!flag) //上一趟比较中不存在交换,则退出排序
- break;
- }
- }
更加优化的方法
在第一步优化的基础上发进一步思考:如果R[0..i]已是有序区间,上次的扫描区间是R[i..n],记上次扫描时最后 一次执行交换的位置为lastSwapPos,则lastSwapPos在i与n之间,不难发现R[i..lastSwapPos]区间也是有序的,否则这个区间也会发生交换;所以下次扫描区间就可以由R[i..n] 缩减到[lastSwapPos..n]。
- void BubbleSort_3(int a[], int size)
- {
- int lastSwapPos = 0,lastSwapPosTemp = 0;
- for (int i = 0; i < size - 1; i++)
- {
- lastSwapPos = lastSwapPosTemp;
- for (int j = size - 1; j >lastSwapPos; j--)
- {
- if (a[j - 1] > a[j])
- {
- int temp = a[j - 1];
- a[j - 1] = a[j];
- a[j] = temp;
- lastSwapPosTemp = j;
- }
- }
- if (lastSwapPos == lastSwapPosTemp)
- break;
- }
- }
转自:http://blog.csdn.net/shuilan0066/article/details/6599905
选择排序
选择排序(Selection Sort)的基本思想是:每一趟从待排序的记录中选出关键字最小的记录,顺序放在已排好序的子文件的最后,直到全部记录排序完毕。
常用的选择排序方法有简单选择排序和堆排序。
一、简单选择排序
在介绍选择排序算法前,我们再回顾下冒泡算法。
冒泡算法是通过两两比较,不断交换,逐个推进的方式,来进行排序的。
一次遍历,得到一个最值。
冒泡算法最费时的是什么?
一是两两比较
一是两两交换, 交换要比比较费时多了。
在冒泡算法一篇中,介绍了几种改进方法,那几种改进方法为什么放在冒泡算法中一篇中,而不另一一篇介绍?
原因就是:无论那几种方法怎么改进,都还是基于两两交换不断推进的冒泡算法。从广义上说,都是属于冒泡算法。
那还有没有其它改进的余地呢?
冒泡算法两两交换的目的是什么?-------找出最值。
而通过这种方式取得最值得代价是很大的,因为,每次遍历,可能需要很多次交换才能找到最值,而这些交换都是很浪费时间的。
如果能减少交换次数,同时又能取得最值,那么这就是一种改进。
因此问题便转换为:如何求最值?求最值得方法有几种?
正所谓条条大路通罗马All RoadsLead to Rome,做成一件事的方法不只一种,人生的路也不只一条。
因此,除了使用两两交换的算法找出最值外,或许还有其它方式。
如果有的话,就是通过另外的思路求得最值,于是便跳出了冒泡的思维模式。
好了,大家想想有没有其他的方法遍历一次就可求出最值?
求最值,需要比较,但不一定非得通过不断推进的方式。
那如何能更好的求得最值呢?
很自然的一种想法便是:
每次遍历,只选择最值元素进行交换,这样一次遍历,只需进行一次交换即可,从而避免了其它无价值的交换操作。
如何求得最值元素所在位置呢?
这还得通过遍历比较。
具体方法为:
遍历一次,记录下最值元素所在位置,遍历结束后,将此最值元素调整到合适的位置
这样一次遍历,只需一次交换,便可将最值放置到合适位置
这便是 简单选择排序算法。


- template<class T>
void SelectSort(T a[], int iLen)
{
T temp;
int iIndex = 0;
for(int i = 0; i < iLen -1; ++i)
{
iIndex = i;
for(int j = i + 1; j < iLen; ++j)
{
if (a[j] < a[iIndex])
{
iIndex = j;
}
}
if (iIndex != i)
{
temp = a[i];
a[i] = a [iIndex];
a[iIndex] = temp;
}
}
}
- 数据结构第一章 数据结构绪论
- 数据结构 第一章 绪论
- [数据结构]第一章--绪论(读书笔记)
- 《数据结构》第一章绪论学习指南
- 数据结构 第一章 绪论
- 数据结构第一章 绪论
- 数据结构 第一章 绪论
- 数据结构 第一章 绪论
- 数据结构 第一章 绪论
- 数据结构第一章绪论
- 《数据结构》第一章绪论总结
- 数据结构 第一章绪论
- 数据结构 第一章绪论
- 《数据结构》 笔记 第一章 绪论
- 数据结构第一章绪论
- 数据结构第一章绪论
- 数据结构第一章 绪论
- 数据结构 ,第一章,绪论
- Hadoop web页面的授权设定
- 基于按annotation的hibernate主键生成策略
- Eclipse下配置主题颜色
- 常见错误
- 如何找到链表的倒数第k个元素
- 数据结构第一章 绪论
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
- linux下IPTABLES配置详解
- opencv 多种数据类型的转换
- Centos Python 开发平台搭建
- Android系统学习网址
- Linux流量监控工具 - iftop
- 用CSS设计类似条状统计表效果
- .NET学习之路C#(1)


