GuozhongCrawler实现一个完整爬虫
来源:互联网 发布:xyz域名 co 编辑:程序博客网 时间:2024/05/17 08:06
原文转载自:http://my.oschina.net/u/1377701/blog/403282
由于版本问题,此项目API已过时。
经过上一节开发环境搭建中的百度新闻的爬虫例子,相信大家已经对GuozhongCrawler简洁的API产生浓厚兴趣了。不过这个还不算一个入门例子。只是完成了简单的下载和解析。现在我们来完成一个比较完整的爬虫吧。
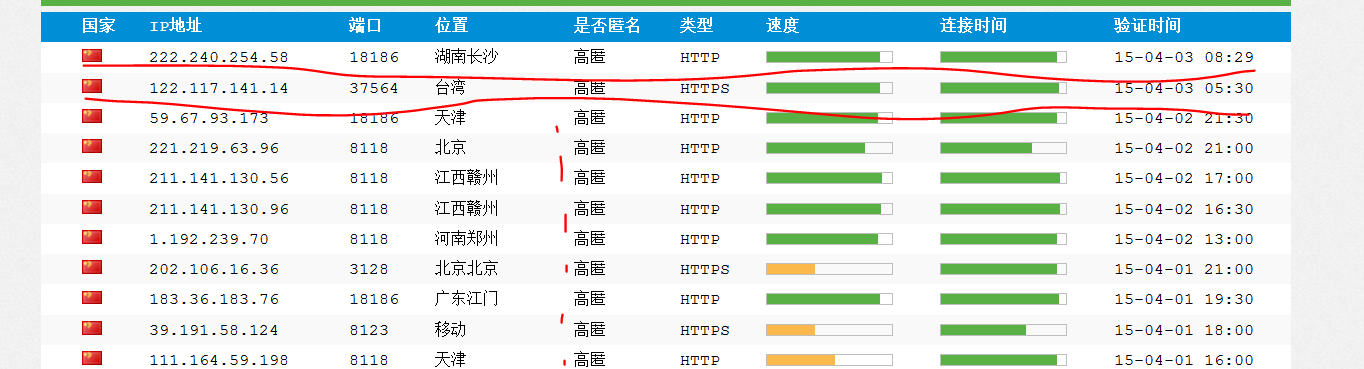
为了体现GuozhongCrawler适应业务灵活性。我们以抓取西刺代理(http://www.xici.net.co/nn/1)的代理IP为需求。需要遍历每一页所有的IP并抓取下来,直到抓完所有的IP为止。
网页如下:
1、新建一个Java项目命名为XiciCrawler并且添加依赖项目为GuozhongCrawler或者直接加入GuozhongCrawler.jar为依赖库。如果大家不知道怎么建依赖项目请看我的GuozhongCrawler开发环境搭建。
2、新建一个爬虫入口Class名为StartCrawXici.java。包名自行拟定。这里命名为guozhong.crawler.impl。选中public static void main(String[]args)生成main方法。StartCrawXici.java代码如下
public class StartCrawXici {
/**
* @param args
*/
public static void main(String[] args) {
CrawlTask task = new CrawlTask("西刺抓代理IP");//给任务取个名字
CrawlManager.prepareCrawlTask(task)
.withThread(5)//设置下载线程数5. 默认值是5
.withStartUrl("http://www.xici.net.co/nn/1", "utf-8")//设置入口URL 并设置页面编码
.addPageProccess(new ParseProxyIpPage())//抓取过程中的页面解析器
.withPipeline(new XiciPipeLine())//离线管道
.start();//启动
}
}
3、ParseProxyIpPage.java是处理页面的实现类。需要实现一个PageProcessor Interface。PageProcessor接口设计如下:
/**
* 网页处理接口
* @author Administrator
*
*/
public interface PageProcessor {
/**
* 标记这个PageProcessor,应该处理哪种Request请求的页面 初始URL可以返回null
* @return
*/
public String getTag();
/**
* 如果需要页面动态交互JS,定义一个PageScript返回
* @return
*/
public PageScript getJavaScript();
/**
* 当启动代理Ip访问时需要重写此方法,返回正常网页应该带有的字符串标识。比如www.baidu.com带有“百度”
* @return
*/
public Pattern getNormalContain();
/**
* 处理一个页面
* @param page
* @param context
* @return
*/
public void process(OkPage page,StartContext context,List<Proccessable> result)throws Exception;
/**
* 处理错误页面
* @param page
* @param context
*/
public void proccessErrorPage(Page page,StartContext context)throws Exception;
}
因为这里是处理入口URL页面。且不需要使用到JS和代理IP。所以getTag()、getJavaScript()和getNormalContain()都不需要实现。本节重点解释process()方法如何使用。至于proccessErrorPage()方法实现和process大同小异。无非是处理错误的内容的html罢了。process()实现如下:
@Override
public void process(OkPage page, StartContext context,
List<Proccessable> result) throws Exception {
System.out.println("该页面的URL:"+page.getRequest().getUrl());
Document doc = Jsoup.parse(page.getContent());
Pattern pattern = Pattern.//抽取代理IP的正则
compile("([\\d]{1,3}\\.[\\d]{1,3}\\.[\\d]{1,3}\\.[\\d]{1,3})\\s*(\\d+)\\s*([^\\s]+)\\s*([^\\s]+)\\s*([^\\s]+)");
Matcher matcher = pattern.matcher(doc.text());
XiciProxy proxy = null;
while(matcher.find()){
proxy = new XiciProxy();
proxy.setIp(matcher.group(1));
proxy.setPort(matcher.group(2));
proxy.setPosition(matcher.group(3));
proxy.setAnonymity("高匿".equals(matcher.group(4)));
proxy.setType(matcher.group(5));
result.add(proxy);//加入到界面处理结果的集合中
}
//判断有没有下一页的URL。有则取得下一页的URL
Element next_a = doc.select("a[class=next_page]").first();
if(next_a != null){
String next_url = next_a.attr("href");
Request req = context.createRequest(next_url, null, 0, "utf-8");//第二个参数传Tag因为这里一直是用初始页面处理器也就是ParseProxyIpPage本身。所以可以传null
//第三个参数是设置request的优先级只有使用PriorityRequestQueue或者DelayedPriorityRequestQueue才有效
result.add(req);//添加到跟进URL队列
}
}
4、XiciPipeLine是实现离线存储的管道类。需要实现一个PipeLine Interface。PipeLine接口设计如下:
public interface Pipeline extends Serializable{
/**
* 所有的结构化数据将流向这里。在这里存储你的bean
* @param procdata
*/
public void proccessData(List<Proccessable> procdata);
}
XiciPipeLine.java实现如下;
public class XiciPipeLine implements Pipeline {
@Override
public void proccessData(List<Proccessable> arg0) {
if(ProccessableUtil.instanceOfClass(arg0, XiciProxy.class)){//判断集合类型是否是XiciProxy
List<XiciProxy> list = ProccessableUtil.convert(arg0, XiciProxy.class);//转换
for (XiciProxy proxy : list) {
//在这里存储到你想要的任何数据库
System.out.println("save:"+proxy);
}
}
}
}
至此完成了一个花刺代理的爬虫。现在把项目图贴出来给大家看看吧
是的4个类完成一个爬虫。屌不屌!
在这里补充XiciProxy.java实体类的代码
public class XiciProxy implements Proccessable{
/**
*
*/
private static final long serialVersionUID = 1L;
private String ip;
private String port;
private String position;
private boolean isAnonymity;
private String type;
//后面getter setter忽略...
}
注:所有实体类都要实现Proccessable接口。只是为了标记作用。让引擎可以统一处理。无其他作用
- GuozhongCrawler实现一个完整爬虫
- GuozhongCrawler看准网爬虫动态切换IP漫爬虫
- GuozhongCrawler实现的基于redis的队列
- 一个爬虫的实现
- 一个完整项目的实现
- 爬虫实战:一个简易 Java 爬虫程序的实现
- 实现了一个完整的chain 链表
- 一个完整托盘程序的实现
- 一个完整托盘程序的实现
- 一个比较完整的WindowsFormsApplication实现
- 一个完整托盘程序的实现
- Android实现对话框-附一个完整例子
- python实现一个完整的blog网站
- html实现一个完整的注册页面
- Tensorflow实现一个完整的CNN例子
- 用React实现一个完整的TodoList
- 一个简单的爬虫技术实现
- 一个简单的爬虫的实现
- Java中计算百分比的方式以及js中
- Java 类的热替换 —— 概念、设计与实现
- Stanford机器学习---第四讲. 神经网络的表示 Neural Networks representation
- 详解Andorid下SQLite存储方式
- 剑指offer 面试题3—二维数组中找数
- GuozhongCrawler实现一个完整爬虫
- 第八周 项目一-复数类中的运算符重载(2)友元函数实现
- linux 主机 新加虚拟ip 网卡别名
- python调试工具----pycharm快捷键及一些常用设置
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
- Spring Security 3 用户信息的问题
- linux 修改用户默认shell(转)
- 高并发,大数据
- 【c++】实现一个函数重载


