HDU 3407 String-Matching Automata
来源:互联网 发布:淘宝网秋装搭配 编辑:程序博客网 时间:2024/05/16 15:58
Problem Description
The finite state automaton (FSA) is an important model of behavioral investigations in computer science, linguistics and many other areas. A FSA can be typically modeled as a string pattern recognizer described by a quintuple <Σ, S, s0, δ, F>, where:
Σ is the input alphabet (a finite nonempty set of symbols).
S is a finite nonempty set of states.
s0 is an element in S designated as the initial state.
δ is a function δ: S × Σ → S known as the transition function.
F is a (possibly empty) subset of S whose elements are designated as the final states.
An FSA with the above description operates as follows:
At the beginning, the automaton starts in the initial state s0.
The automaton continuously reads symbols from its input, one symbol at a time, and transits between states according to the transition function δ. To be specific, let s be the current state and w the symbol just read, the automaton moves to the state given by δ(s, w).
When the automaton reaches the end of the input, if the current state belongs to F, the string consisting sequentially of the symbols read by the automaton is declared accepted, otherwise it is declared rejected.
Just as the name implies, a string-matching automaton is a FSA that is used for string matching and is very efficient: they examine each character exactly once, taking constant time per text character. The matching time used (after the automaton is built) is therefore Θ(n). However, the time to build the automaton can be large.
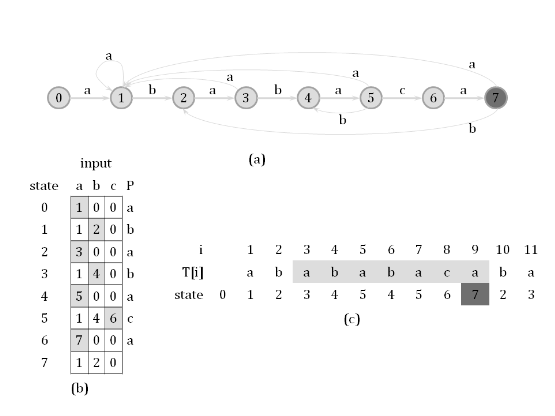
Precisely, there is a string-matching automaton for every pattern P that you search for in a given text string T. For a given pattern of length m, the corresponding automaton has (m + 1) states {q0, q1, …, qm}: q0 is the start state, qm is the only final state, and for each i in {0, 1, …, m}, if the automaton reaches state qi, it means the length of the longest prefix of P that is also a suffix of the input string is i. When we reaches state qm, it means P is a suffix of the currently input string, which suggest we find an occurrence of P.
The following graph shows a string-matching automaton for the pattern “ababaca”, and illustrates how the automaton works given an input string “abababacaba”.
Apparently, the matching process using string-matching automata is quite simple (also efficient). However, building the automaton efficiently seems to be tough, and that’s your task in this problem.
Σ is the input alphabet (a finite nonempty set of symbols).
S is a finite nonempty set of states.
s0 is an element in S designated as the initial state.
δ is a function δ: S × Σ → S known as the transition function.
F is a (possibly empty) subset of S whose elements are designated as the final states.
An FSA with the above description operates as follows:
At the beginning, the automaton starts in the initial state s0.
The automaton continuously reads symbols from its input, one symbol at a time, and transits between states according to the transition function δ. To be specific, let s be the current state and w the symbol just read, the automaton moves to the state given by δ(s, w).
When the automaton reaches the end of the input, if the current state belongs to F, the string consisting sequentially of the symbols read by the automaton is declared accepted, otherwise it is declared rejected.
Just as the name implies, a string-matching automaton is a FSA that is used for string matching and is very efficient: they examine each character exactly once, taking constant time per text character. The matching time used (after the automaton is built) is therefore Θ(n). However, the time to build the automaton can be large.
Precisely, there is a string-matching automaton for every pattern P that you search for in a given text string T. For a given pattern of length m, the corresponding automaton has (m + 1) states {q0, q1, …, qm}: q0 is the start state, qm is the only final state, and for each i in {0, 1, …, m}, if the automaton reaches state qi, it means the length of the longest prefix of P that is also a suffix of the input string is i. When we reaches state qm, it means P is a suffix of the currently input string, which suggest we find an occurrence of P.
The following graph shows a string-matching automaton for the pattern “ababaca”, and illustrates how the automaton works given an input string “abababacaba”.
Apparently, the matching process using string-matching automata is quite simple (also efficient). However, building the automaton efficiently seems to be tough, and that’s your task in this problem.
Input
Several lines, each line has one pattern consist of only lowercase alphabetic characters. The length of the longest pattern is 10000. The input ends with a separate line of ‘0’.
Output
For each pattern, output should contain (m + 1) lines(m is the length of the pattern). The nth line describes how the automaton changes its state from state (n-1) after reading a character. It starts with the state number (n – 1), and then 26 state numbers follow. The 1st state number p1 indicates that when the automaton is in state (n-1), it will transit to state p1 after reading a character ‘a’. The 2nd state number p2 indicates that when the automaton is in state (n-1), it will transit to state p2 after reading a character ‘b’… And so on.
Sample Input
ababaca0
Sample Output
0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 01 1 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 02 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 03 1 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 04 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 05 1 4 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 06 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 07 1 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
直接建立ac自动机输出答案即可。
#include<stdio.h>#include<string.h>#include<queue>#include<malloc.h>using namespace std;const int maxn = 1000005;class tire{public: tire *down[26], *next; int end; tire(){ next = NULL; end = 0; memset(down, 0, sizeof(down)); } void assign(){ next = NULL; end = 0; memset(down, 0, sizeof(down)); }};class ac_automaton{private: tire *root; char s[maxn]; char S[maxn];public: ac_automaton(){ root = new tire; } bool insert() { if (scanf("%s", s), s[0] == '0') return false; root = new tire; tire* j = root; for (int i = 0, k; s[i]; i++) { k = s[i] - 'a'; if (!j->down[k]) j->down[k] = new tire; j = j->down[k]; j->end = i + 1; } } void getnext() { queue<tire*> p; tire *q, *k, *j; root->next = root; for (int i = 0; i < 26; i++) if (root->down[i]) { q = root->down[i]; q->next = root; p.push(q); } else root->down[i] = root; while (!p.empty()) { q = p.front(); p.pop(); k = q->next; for (int i = 0; i < 26; i++) if (q->down[i]) { j = q->down[i]; j->next = k->down[i]; p.push(q->down[i]); } else q->down[i] = k->down[i]; } } void work_out() { getnext(); strcpy(S, s); tire *j = root, *u; for (int i = 0, k; ; i++) { printf("%d ", i); k = S[i] - 'a'; for (int son = 0; son < 26; son++) { printf("%d", j->down[son]->end); if (son < 25) printf(" "); else printf("\n"); } j = j->down[k]; if (!S[i]) break; } }};ac_automaton f;int main(){ while (f.insert()) f.work_out(); return 0;}
0 0
- HDU 3407 String-Matching Automata
- HDU--3407[String-Matching Automata] AC自动机或kmp
- hdu-1306- String Matching
- HDU-1306-String Matching
- hdu 1306 String Matching
- hdu 1036 String Matching
- hdu 3259 Just Another String Matching Problem
- KMP Matching: String Matching
- String Matching
- String Matching
- String Matching
- Naive String Matching: String Matching
- POJ 1580 && HDU 1306 String Matching(水~)
- Finite Automaton Matching: String Matching
- Rabin Karp Matching: String Matching
- PKU 1580 String Matching
- String matching with simmetrics
- Binary String Matching
- 杭电ACM1039——Easier Done Than Said?
- 社説 20150503 憲法記念日 まず改正テーマを絞り込もう
- Linux LinkFile
- 字符串查找替换操作
- cocos2dx3.5 studio c++简单功能实现
- HDU 3407 String-Matching Automata
- 【转载】 J2SE知识点归纳笔记(五)---Java多线程(一)
- HDU 2955 Robberies (01背包)
- java 简单排序
- 不容易系列之一
- 手机刷机过程
- AAA Spring中常用的hql查询方法(getHibernateTemplate()的find方法大全
- 正确使用ngrok穿透内网
- VS2010中自制8*8字模提取


