序列化和反序列化
来源:互联网 发布:费马的房间 知乎 编辑:程序博客网 时间:2024/05/22 08:18
一,几种常见的序列化和反序列化协议
互联网早期的序列化协议主要有COM和CORBA。
COM主要用于Windows平台,并没有真正实现跨平台,另外COM的序列化的原理利用了编译器中虚表,使得其学习成本巨大(想一下这个场景, 工程师需要是简单的序列化协议,但却要先掌握语言编译器)。由于序列化的数据与编译器紧耦合,扩展属性非常麻烦。
CORBA是早期比较好的实现了跨平台,跨语言的序列化协议。COBRA的主要问题是参与方过多带来的版本过多,版本之间兼容性较差,以及使用复杂晦涩。这些政治经济,技术实现以及早期设计不成熟的问题,最终导致COBRA的渐渐消亡。J2SE 1.3之后的版本提供了基于CORBA协议的RMI-IIOP技术,这使得Java开发者可以采用纯粹的Java语言进行CORBA的开发。
这里主要介绍和对比几种当下比较流行的序列化协议,包括XML、JSON、Protobuf、Thrift和Avro。
XML&SOAP
XML是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点。 XML历史悠久,其1.0版本早在1998年就形成标准,并被广泛使用至今。XML的最初产生目标是对互联网文档(Document)进行标记,所以它的设计理念中就包含了对于人和机器都具备可读性。 但是,当这种标记文档的设计被用来序列化对象的时候,就显得冗长而复杂(Verbose and Complex)。 XML本质上是一种描述语言,并且具有自我描述(Self-describing)的属性,所以XML自身就被用于XML序列化的IDL。 标准的XML描述格式有两种:DTD(Document Type Definition)和XSD(XML Schema Definition)。作为一种人眼可读(Human-readable)的描述语言,XML被广泛使用在配置文件中,例如O/R mapping、 Spring Bean Configuration File 等。
SOAP(Simple Object Access protocol) 是一种被广泛应用的,基于XML为序列化和反序列化协议的结构化消息传递协议。SOAP在互联网影响如此大,以至于我们给基于SOAP的解决方案一个特定的名称--Web service。SOAP虽然可以支持多种传输层协议,不过SOAP最常见的使用方式还是XML+HTTP。SOAP协议的主要接口描述语言(IDL)是WSDL(Web Service Description Language)。SOAP具有安全、可扩展、跨语言、跨平台并支持多种传输层协议。如果不考虑跨平台和跨语言的需求,XML的在某些语言里面具有非常简单易用的序列化使用方法,无需IDL文件和第三方编译器, 例如Java+XStream。
自我描述与递归
SOAP是一种采用XML进行序列化和反序列化的协议,它的IDL是WSDL. 而WSDL的描述文件是XSD,而XSD自身是一种XML文件。 这里产生了一种有趣的在数学上称之为“递归”的问题,这种现象往往发生在一些具有自我属性(Self-description)的事物上。
IDL文件举例
采用WSDL描述上述用户基本信息的例子如下:
<xsd:complexType name='Address'> <xsd:attribute name='city' type='xsd:string' /> <xsd:attribute name='postcode' type='xsd:string' /> <xsd:attribute name='street' type='xsd:string' /></xsd:complexType><xsd:complexType name='UserInfo'> <xsd:sequence> <xsd:element name='address' type='tns:Address'/> <xsd:element name='address1' type='tns:Address'/> </xsd:sequence> <xsd:attribute name='userid' type='xsd:int' /> <xsd:attribute name='name' type='xsd:string' /> </xsd:complexTyp>典型应用场景和非应用场景
SOAP协议具有广泛的群众基础,基于HTTP的传输协议使得其在穿越防火墙时具有良好安全特性,XML所具有的人眼可读(Human-readable)特性使得其具有出众的可调试性,互联网带宽的日益剧增也大大弥补了其空间开销大(Verbose)的缺点。对于在公司之间传输数据量相对小或者实时性要求相对低(例如秒级别)的服务是一个好的选择。由于XML的额外空间开销大,序列化之后的数据量剧增,对于数据量巨大序列持久化应用常景,这意味着巨大的内存和磁盘开销,不太适合XML。另外,XML的序列化和反序列化的空间和时间开销都比较大,对于对性能要求在ms级别的服务,不推荐使用。WSDL虽然具备了描述对象的能力,SOAP的S代表的也是simple,但是SOAP的使用绝对不简单。对于习惯于面向对象编程的用户,WSDL文件不直观。
JSON(Javascript Object Notation)
JSON起源于弱类型语言Javascript, 它的产生来自于一种称之为"Associative array"的概念,其本质是就是采用"Attribute-value"的方式来描述对象。实际上在Javascript和PHP等弱类型语言中,类的描述方式就是Associative array。JSON的如下优点,使得它快速成为最广泛使用的序列化协议之一。
- 这种Associative array格式非常符合工程师对对象的理解。
- 它保持了XML的人眼可读(Human-readable)的优点。
- 相对于XML而言,序列化后的数据更加简洁。 来自于的以下链接的研究表明:XML所产生序列化之后文件的大小接近JSON的两倍。http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity
- 它具备Javascript的先天性支持,所以被广泛应用于Web browser的应用常景中,是Ajax的事实标准协议。
- 与XML相比,其协议比较简单,解析速度比较快。
- 松散的Associative array使得其具有良好的可扩展性和兼容性。
典型应用场景和非应用场景
JSON在很多应用场景中可以替代XML,更简洁并且解析速度更快。典型应用场景包括:
- 公司之间传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
- 基于Web browser的Ajax请求。
- 由于JSON具有非常强的前后兼容性,对于接口经常发生变化,并对可调式性要求高的场景,例如Mobile app与服务端的通讯。
- 由于JSON的典型应用场景是JSON+HTTP,适合跨防火墙访问。总的来说,采用JSON进行序列化的额外空间开销比较大,对于大数据量服务或持久化,这意味着巨大的内存和磁盘开销,这种场景不适合。没有统一可用的IDL降低了对参与方的约束,实际操作中往往只能采用文档方式来进行约定,这可能会给调试带来一些不便,延长开发周期。 由于JSON在一些语言中的序列化和反序列化需要采用反射机制,所以在性能要求为ms级别,不建议使用。
IDL文件举例
以下是UserInfo序列化之后的一个例子:
{"userid":1,"name":"messi","address":[{"city":"北京","postcode":"1000000","street":"wangjingdonglu"}]}Thrift
Thrift是Facebook开源提供的一个高性能,轻量级RPC服务框架,其产生正是为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求。 但是,Thrift并不仅仅是序列化协议,而是一个RPC框架。相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用(例如HTTP)。
典型应用场景和非应用场景
对于需求为高性能,分布式的RPC服务,Thrift是一个优秀的解决方案。它支持众多语言和丰富的数据类型,并对于数据字段的增删具有较强的兼容性。所以非常适用于作为公司内部的面向服务构建(SOA)的标准RPC框架。
不过Thrift的文档相对比较缺乏,目前使用的群众基础相对较少。另外由于其Server是基于自身的Socket服务,所以在跨防火墙访问时,安全是一个顾虑,所以在公司间进行通讯时需要谨慎。 另外Thrift序列化之后的数据是Binary数组,不具有可读性,调试代码时相对困难。最后,由于Thrift的序列化和框架紧耦合,无法支持向持久层直接读写数据,所以不适合做数据持久化序列化协议。
IDL文件举例
struct Address{ 1: required string city;2: optional string postcode;3: optional string street;} struct UserInfo{ 1: required string userid;2: required i32 name;3: optional list<address> address;}</address>Protobuf
Protobuf具备了优秀的序列化协议的所需的众多典型特征。
- 标准的IDL和IDL编译器,这使得其对工程师非常友好。
- 序列化数据非常简洁,紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10。
- 解析速度非常快,比对应的XML快约20-100倍。
- 提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
Protobuf是一个纯粹的展示层协议,可以和各种传输层协议一起使用;Protobuf的文档也非常完善。 但是由于Protobuf产生于Google,所以目前其仅仅支持Java、C#### 典型应用场景和非应用场景 Protobuf具有广泛的用户基础,空间开销小以及高解析性能是其亮点,非常适合于公司内部的对性能要求高的RPC调用。由于Protobuf提供了标准的IDL以及对应的编译器,其IDL文件是参与各方的非常强的业务约束,另外,Protobuf与传输层无关,采用HTTP具有良好的跨防火墙的访问属性,所以Protobuf也适用于公司间对性能要求比较高的场景。由于其解析性能高,序列化后数据量相对少,非常适合应用层对象的持久化场景。
它的主要问题在于其所支持的语言相对较少,另外由于没有绑定的标准底层传输层协议,在公司间进行传输层协议的调试工作相对麻烦。
IDL文件举例
message Address{required string city=1;optional string postcode=2;optional string street=3;}message UserInfo{required string userid=1;required string name=2;repeated Address address=3;}Avro
Avro的产生解决了JSON的冗长和没有IDL的问题,Avro属于Apache Hadoop的一个子项目。 Avro提供两种序列化格式:JSON格式或者Binary格式。Binary格式在空间开销和解析性能方面可以和Protobuf媲美,JSON格式方便测试阶段的调试。 Avro支持的数据类型非常丰富,包括C#### 典型应用场景和非应用场景 Avro解析性能高并且序列化之后的数据非常简洁,比较适合于高性能的序列化服务。
由于Avro目前非JSON格式的IDL处于实验阶段,而JSON格式的IDL对于习惯于静态类型语言的工程师来说不直观。
IDL文件举例
protocol Userservice { record Address { string city; string postcode; string street; } record UserInfo { string name; int userid; array<Address> address = []; }}所对应的JSON Schema格式如下:
{ "protocol" : "Userservice", "namespace" : "org.apache.avro.ipc.specific", "version" : "1.0.5", "types" : [ {"type" : "record","name" : "Address","fields" : [ { "name" : "city", "type" : "string"}, { "name" : "postcode", "type" : "string"}, { "name" : "street", "type" : "string"} ] }, {"type" : "record","name" : "UserInfo","fields" : [ { "name" : "name", "type" : "string"}, { "name" : "userid", "type" : "int"}, { "name" : "address", "type" : {"type" : "array","items" : "Address" }, "default" : [ ]} ] } ], "messages" : { }}Benchmark以及选型建议
Benchmark
以下数据来自https://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking。
解析性能
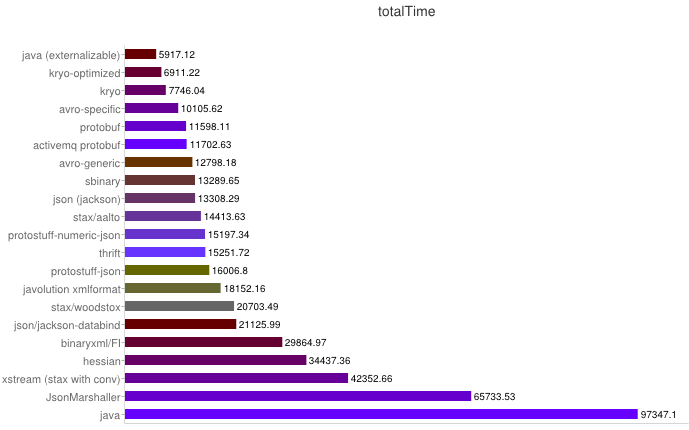
序列化之空间开销
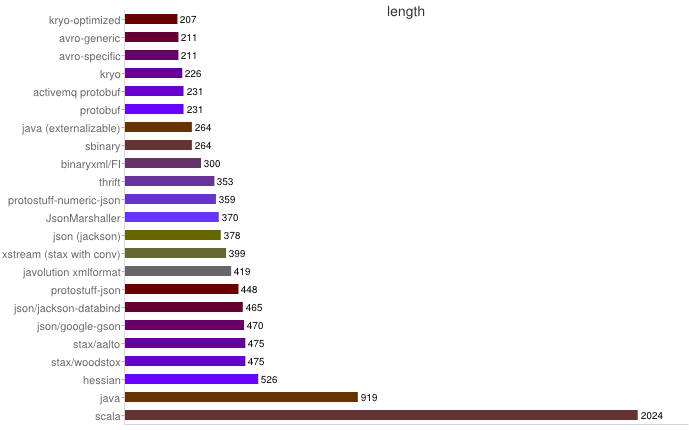
从上图可得出如下结论:
- XML序列化(Xstream)无论在性能和简洁性上比较差;
- Thrift与Protobuf相比在时空开销方面都有一定的劣势;
- Protobuf和Avro在两方面表现都非常优越。
选型建议
以上描述的五种序列化和反序列化协议都各自具有相应的特点,适用于不同的场景。
- 对于公司间的系统调用,如果性能要求在100ms以上的服务,基于XML的SOAP协议是一个值得考虑的方案。
- 基于Web browser的Ajax,以及Mobile app与服务端之间的通讯,JSON协议是首选。对于性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON也是非常不错的选择。
- 对于调试环境比较恶劣的场景,采用JSON或XML能够极大的提高调试效率,降低系统开发成本。
- 当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro之间具有一定的竞争关系。
- 对于T级别的数据的持久化应用场景,Protobuf和Avro是首要选择。如果持久化后的数据存储在Hadoop子项目里,Avro会是更好的选择。
- 由于Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
- 对于持久层非Hadoop项目,以静态类型语言为主的应用场景,Protobuf会更符合静态类型语言工程师的开发习惯。
- 如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
- 如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。
- 序列和反序列化
- 序列和反序列化
- 序列化和反序列化
- 序列化和反序列化
- 序列化和反序列化
- c# 序列化和反序列化
- .NET序列化和反序列化
- .net序列化和反序列化
- 序列化和反序列化
- C#序列化和反序列化
- XML序列化和反序列化
- Serializable,序列化和反序列化
- C#序列化和反序列化
- Java序列化和反序列化
- C#序列化和反序列化
- 序列化和反序列化
- c#序列化和反序列化
- XML序列化和反序列化
- Java语言考核方式的选择
- java简单ping其他Ip是否可以ping通
- VC编程使用HSB(HSV)色彩空间实现色差比较
- ModelAndView解析
- 【iOS解决方案】iPhone走马灯控件实现
- 序列化和反序列化
- 下拉刷新问题记录
- 入门级linux下C++的多文件编译
- Java语言系列课程的设置
- HttpClient3.0入门
- c语言函数参数传递
- 关于查阅资料
- 【iOS学习笔记】UIlabel文字自适应
- 2015中国高校毕业生薪酬排行榜


