Cassandra in Spring
来源:互联网 发布:智联招聘 java开发 编辑:程序博客网 时间:2024/06/06 19:50
最近在学习Cassandra,发现只有安装配置的教程,但是对于如何实际使用介绍的很少,即使有也是非常间的示例,或者通过EasyCassandra的方案无法继续。找到下面的文章,非常难得,转过来,希望给大家帮助。
转载自:http://middlewaresnippets.blogspot.com/2015/02/cassandra-in-spring.html
Cassandra in Spring
In this post we set-up Apache Cassandra. In order to do this in a consistent manner across multiple hosts (using a tarball), we create templates. After we have set-up a Cassandra cluster, we will use Spring Data to create Java clients.
Cassandra uses a storage structure similar to a Log-Structured Merge Tree (The Log-Structured Merge-Tree (LSM-Tree)), unlike a typical relational database that uses aB-Tree (B-Tree Visualization). Cassandra avoids reading before writing. Read-before-write, especially in a large distributed system, can produce stalls in read performance and other problems. Reading before writing also corrupts caches and increases IO requirements. To avoid a read-before-write condition, the storage engine groups inserts/updates to be made, and sequentially writes only the updated parts of a row in append mode. Cassandra never re-writes or re-reads existing data, and never overwrites the rows in place. More information can be read in thedatabase internals.
Understanding the performance characteristics of the Cassandra cluster is critical to diagnosing issues and planning capacity. Cassandra exposes a number of statistics and management operations via JMX. During operation, Cassandra outputs information and statistics that can be monitored using JMX-compliant tools, for example,
In the
A keyspace is the CQL counterpart to an SQL database, but a little different. The Cassandra keyspace is a namespace that defines how data is replicated on nodes. Typically, a cluster has one keyspace per application. Replication is controlled on a per-keyspace basis, so data that has different replication requirements typically resides in different keyspaces. Keyspaces are not designed to be used as a significant map layer within the data model. Keyspaces are designed to controldata replication for a set of tables.
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. Note that we canincrease the replication factor and add the desired number of nodes later. Two replication strategies are available:
The driver discovers nodes that constitute a cluster by querying the contact points used in building the cluster object. After this it is up to the cluster's load balancing policy to keep track of node events. If a Cassandra node fails or becomes unreachable, the Java driver automatically and transparently tries other nodes in the cluster and schedules reconnections to the dead nodes in the background. More information on the driver can be found in thedriver reference.
As an example, we can use the following
When the example is run, we get the following output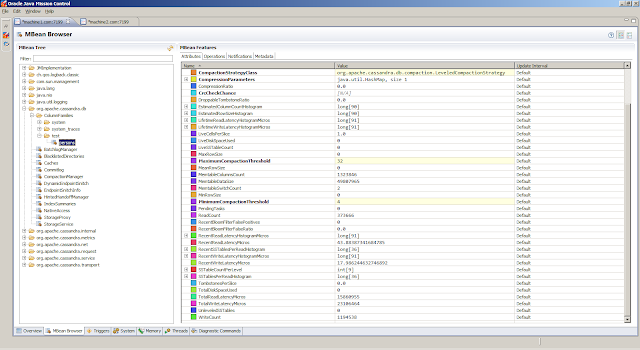
 On Linux we can use
On Linux we can use 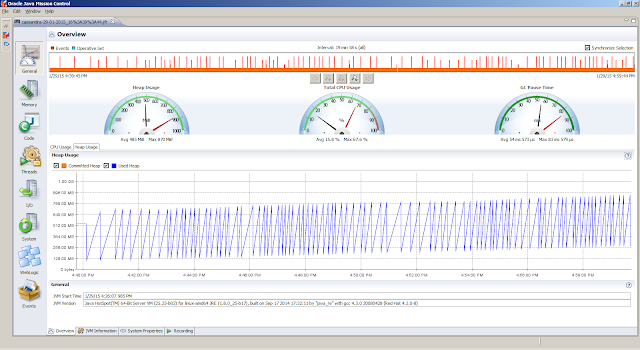
 The
The 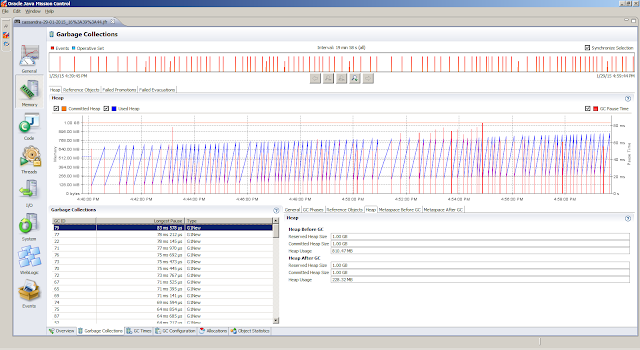 The
The 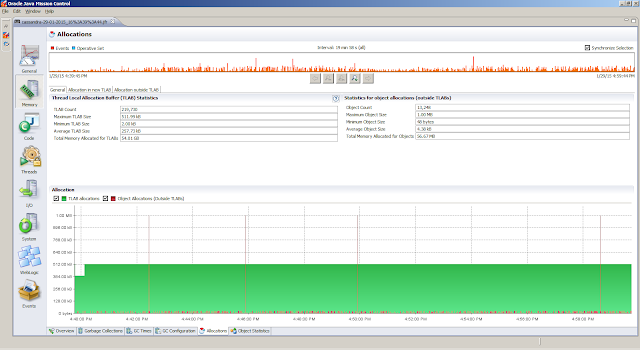
 The
The 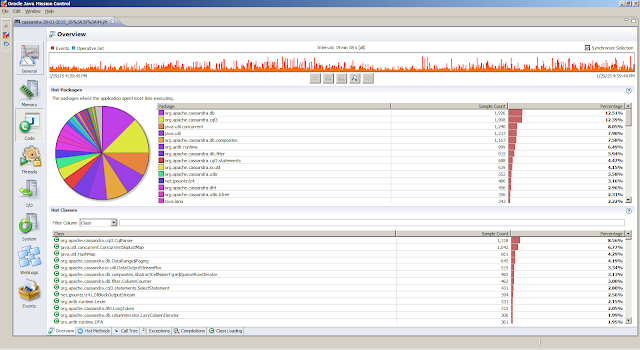 The
The 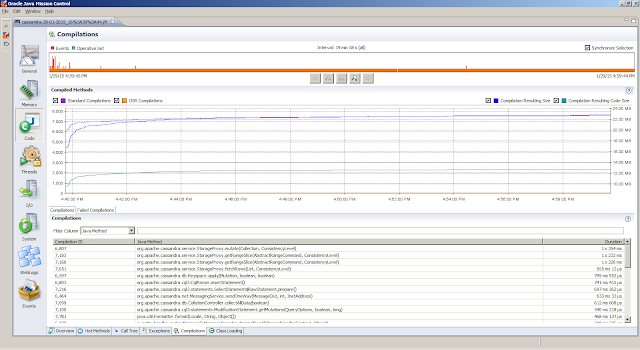 The
The 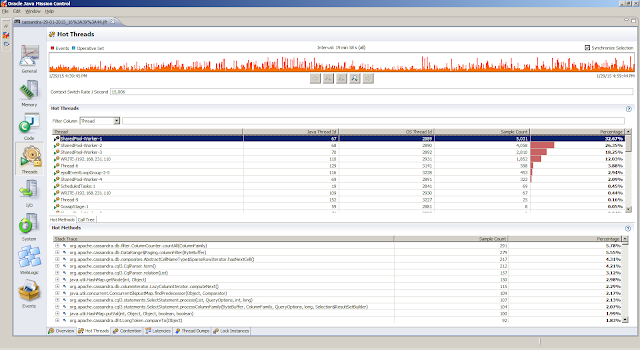
 Great stuff! As a last remark, SANs were designed to solve problems Cassandra does not have, i.e., Cassandra was designed from the start for commodity hardware.
Great stuff! As a last remark, SANs were designed to solve problems Cassandra does not have, i.e., Cassandra was designed from the start for commodity hardware.
[2] Spring Data Cassandra - Reference Documentation.
Introduction
Cassandra is designed to handle big data workloads across multiple nodes with no single point of failure. Its architecture is based on the understanding that system and hardware failures can and do occur. Cassandra addresses the problem of failures by employing a peer-to-peer distributed system across homogeneous nodes where data is distributed among all nodes in the cluster. A commit log on each node captures write activity to ensure data durability. Data is then indexed and written to an in-memory structure, called a memtable, which resembles a write-back cache. Once the memory structure is full, the data is written to disk in anSSTable (Sorted String Table) data file. All writes are automatically partitioned and replicated throughout the cluster. Using a process called compaction Cassandra periodically consolidates SSTables, discarding obsolete data and tombstones (an indicator that data was deleted). More information can be read in the write path to compaction.Cassandra uses a storage structure similar to a Log-Structured Merge Tree (The Log-Structured Merge-Tree (LSM-Tree)), unlike a typical relational database that uses aB-Tree (B-Tree Visualization). Cassandra avoids reading before writing. Read-before-write, especially in a large distributed system, can produce stalls in read performance and other problems. Reading before writing also corrupts caches and increases IO requirements. To avoid a read-before-write condition, the storage engine groups inserts/updates to be made, and sequentially writes only the updated parts of a row in append mode. Cassandra never re-writes or re-reads existing data, and never overwrites the rows in place. More information can be read in thedatabase internals.
Install and configure Cassandra
Choosing appropriate hardware depends on selecting the right balance of the following resources: memory, CPU, disks, number of nodes, and network:- Memory, the more memory a Cassandra node has, the better the read performance. More RAM also allows memory tables (memtables - a table-specific in-memory data structure that resembles a write-back cache) to hold more recently written data. Larger memtables lead to a fewer number of SSTables being flushed to disk and fewer files to scan during a read. The ideal amount of RAM depends on the anticipated size of the hot data.
- CPU, insert-heavy workloads are CPU-bound in Cassandra before becoming memory-bound (all writes go to the commit log - a file to which Cassandra appends changed data for recovery in the event of a hardware failure).
- Disk, disk space depends on usage, so it is important to understand the mechanism. Cassandra writes data to disk when appending data to the commit log for durability and when flushing the memtable to SSTable data files for persistent storage. The commit log has a different access pattern (read/writes ratio) than the pattern for accessing data from SSTables. SSTables are periodically compacted. Compaction improves performance by merging and rewriting data and discarding old data. Depending on the type of compaction strategy and size of the compactions, compaction increases disk utilization, and we should leave an adequate amount of free disk space available on the node.
- Network, since Cassandra is a distributed data store, it puts load on the network to handle read/write requests and replication of data across nodes. Be sure that the network can handle traffic between nodes without bottlenecks. Cassandra routes requests to replicas that are geographically closest to the coordinator node.
Understanding the performance characteristics of the Cassandra cluster is critical to diagnosing issues and planning capacity. Cassandra exposes a number of statistics and management operations via JMX. During operation, Cassandra outputs information and statistics that can be monitored using JMX-compliant tools, for example,
- the nodetool command-line utility;
- the DataStax OpsCenter management console; or
- JMX clients such as JConsole, Java VisualVM, and Java Mission Control. More information can be found in the post Monitoring with JMX.
conf/cassandra.yaml, is the main configuration file.conf/cassandra-env.shcontains Java Virtual Machine configuration settings.bin/cassandra.in.shsets up environment variables such asCLASSPATHandJAVA_HOME.
cassandra.yaml file we haveAs we will be running on Java 8, we use the Garbage First Collector and
- # The name of the cluster. This is mainly used to prevent machines in
- # one logical cluster from joining another.
- cluster_name: '<%= @CLUSTER_NAME %>'
- # This defines the number of tokens randomly assigned to this node on the ring
- # The more tokens, relative to other nodes, the larger the proportion of data
- # that this node will store. You probably want all nodes to have the same number
- # of tokens assuming they have equal hardware capability.
- #
- # If you leave this unspecified, Cassandra will use the default of 1 token for legacy compatibility,
- # and will use the initial_token as described below.
- #
- # Specifying initial_token will override this setting on the node's initial start,
- # on subsequent starts, this setting will apply even if initial token is set.
- #
- # If you already have a cluster with 1 token per node, and wish to migrate to
- # multiple tokens per node, see http://wiki.apache.org/cassandra/Operations
- num_tokens: <%= @NUM_TOKENS %>
- ...
- # any class that implements the SeedProvider interface and has a
- # constructor that takes a Map<String, String> of parameters will do.
- seed_provider:
- # Addresses of hosts that are deemed contact points.
- # Cassandra nodes use this list of hosts to find each other and learn
- # the topology of the ring. You must change this if you are running
- # multiple nodes!
- - class_name: org.apache.cassandra.locator.SimpleSeedProvider
- parameters:
- # seeds is actually a comma-delimited list of addresses.
- # Ex: "<ip1>,<ip2>,<ip3>"
- - seeds: "<%= @SEED_ADDRESSES %>"
- ...
- # TCP port, for commands and data
- storage_port: <%= @STORAGE_PORT %>
- # SSL port, for encrypted communication. Unused unless enabled in
- # encryption_options
- ssl_storage_port: <%= @SSL_STORAGE_PORT %>
- # Address or interface to bind to and tell other Cassandra nodes to connect to.
- # You _must_ change this if you want multiple nodes to be able to communicate!
- #
- # Set listen_address OR listen_interface, not both. Interfaces must correspond
- # to a single address, IP aliasing is not supported.
- #
- # Leaving it blank leaves it up to InetAddress.getLocalHost(). This
- # will always do the Right Thing _if_ the node is properly configured
- # (hostname, name resolution, etc), and the Right Thing is to use the
- # address associated with the hostname (it might not be).
- #
- # Setting listen_address to 0.0.0.0 is always wrong.
- listen_address: <%= @LISTEN_ADDRESS %>
- # listen_interface: eth0
- ...
- # Whether to start the native transport server.
- # Please note that the address on which the native transport is bound is the
- # same as the rpc_address. The port however is different and specified below.
- start_native_transport: true
- # port for the CQL native transport to listen for clients on
- native_transport_port: <%= @NATIVE_TRANSPORT_PORT %>
- ...
- # The address or interface to bind the Thrift RPC service and native transport
- # server to.
- #
- # Set rpc_address OR rpc_interface, not both. Interfaces must correspond
- # to a single address, IP aliasing is not supported.
- #
- # Leaving rpc_address blank has the same effect as on listen_address
- # (i.e. it will be based on the configured hostname of the node).
- #
- # Note that unlike listen_address, you can specify 0.0.0.0, but you must also
- # set broadcast_rpc_address to a value other than 0.0.0.0.
- rpc_address: <%= @RPC_ADDRESS %>
- # rpc_interface: eth1
- # port for Thrift to listen for clients on
- rpc_port: <%= @RPC_PORT %>
- # RPC address to broadcast to drivers and other Cassandra nodes. This cannot
- # be set to 0.0.0.0. If left blank, this will be set to the value of
- # rpc_address. If rpc_address is set to 0.0.0.0, broadcast_rpc_address must
- # be set.
- broadcast_rpc_address: <%= @BROADCAST_RPC_ADDRESS %>
- ...
- # endpoint_snitch -- Set this to a class that implements
- # IEndpointSnitch. The snitch has two functions:
- # - it teaches Cassandra enough about your network topology to route
- # requests efficiently
- # - it allows Cassandra to spread replicas around your cluster to avoid
- # correlated failures. It does this by grouping machines into
- # "datacenters" and "racks." Cassandra will do its best not to have
- # more than one replica on the same "rack" (which may not actually
- # be a physical location)
- #
- # IF YOU CHANGE THE SNITCH AFTER DATA IS INSERTED INTO THE CLUSTER,
- # YOU MUST RUN A FULL REPAIR, SINCE THE SNITCH AFFECTS WHERE REPLICAS
- # ARE PLACED.
- #
- # Out of the box, Cassandra provides
- # - SimpleSnitch:
- # Treats Strategy order as proximity. This can improve cache
- # locality when disabling read repair. Only appropriate for
- # single-datacenter deployments.
- # - GossipingPropertyFileSnitch
- # This should be your go-to snitch for production use. The rack
- # and datacenter for the local node are defined in
- # cassandra-rackdc.properties and propagated to other nodes via
- # gossip. If cassandra-topology.properties exists, it is used as a
- # fallback, allowing migration from the PropertyFileSnitch.
- # - PropertyFileSnitch:
- # Proximity is determined by rack and data center, which are
- # explicitly configured in cassandra-topology.properties.
- # - Ec2Snitch:
- # Appropriate for EC2 deployments in a single Region. Loads Region
- # and Availability Zone information from the EC2 API. The Region is
- # treated as the datacenter, and the Availability Zone as the rack.
- # Only private IPs are used, so this will not work across multiple
- # Regions.
- # - Ec2MultiRegionSnitch:
- # Uses public IPs as broadcast_address to allow cross-region
- # connectivity. (Thus, you should set seed addresses to the public
- # IP as well.) You will need to open the storage_port or
- # ssl_storage_port on the public IP firewall. (For intra-Region
- # traffic, Cassandra will switch to the private IP after
- # establishing a connection.)
- # - RackInferringSnitch:
- # Proximity is determined by rack and data center, which are
- # assumed to correspond to the 3rd and 2nd octet of each node's IP
- # address, respectively. Unless this happens to match your
- # deployment conventions, this is best used as an example of
- # writing a custom Snitch class and is provided in that spirit.
- #
- # You can use a custom Snitch by setting this to the full class name
- # of the snitch, which will be assumed to be on your classpath.
- endpoint_snitch: <%= @ENDPOINT_SNITCH %>
TieredCompilation (which is the default in Java 8). More information on howTieredCompilation works and how to tune the Garbage First Collector can be found in the postJava Virtual Machine Code Generation and Optimization. For the cassandra-env.sh file we have (the options that are not shown are disabled)Note that, we have also disabled the new generation setting (
- MAX_HEAP_SIZE=<%= @HEAP_SIZE %>
- HEAP_NEWSIZE=<%= @NURSERY_SIZE %>
- # Specifies the default port over which Cassandra will be available for JMX connections.
- JMX_PORT=<%= @JMX_PORT %>
- JVM_OPTS="$JVM_OPTS -Xms${MAX_HEAP_SIZE}"
- JVM_OPTS="$JVM_OPTS -Xmx${MAX_HEAP_SIZE}"
- # Larger interned string table, for gossip's benefit (CASSANDRA-6410)
- JVM_OPTS="$JVM_OPTS -XX:StringTableSize=1000003"
- # GC tuning options
- JVM_OPTS="$JVM_OPTS -XX:+UseG1GC"
- JVM_OPTS="$JVM_OPTS -XX:MaxGCPauseMillis=<%= @PAUSE_TIME_GOAL_MILLIS %>"
- # Settings to be able to take flight recordings (optional, needs the JavaSE Advanced license in production environments)
- JVM_OPTS="$JVM_OPTS -XX:+UnlockCommercialFeatures -XX:+FlightRecorder -Dname=<%= @SERVER_NAME %>"
- JVM_OPTS="$JVM_OPTS -Djava.net.preferIPv4Stack=true"
- JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT"
- JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
- JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.ssl=false"
- JVM_OPTS="$JVM_OPTS -Dcom.sun.management.jmxremote.authenticate=false"
Xmn). As we are working with a pause time goal we must avoid explicitly setting the new generation size, as this overrides the pause time goal. The experimental flagsG1NewSizePercent (default 5%) and G1MaxNewSizePercent (default 60%) can be used to respectively set minimum and maximum for the new generation size. Values for experimental flags can be changed by enablingUnlockExperimentalVMOptions. To see what the default values of command-line options are (such as the thread stack size) refer to thecommand-line options reference. For information on the use of thread priorities refer to the documentMap Thread priorities to system thread/process priorities. In the
cassandra.in.sh file we only change the JAVA_HOME variable (the rest remains unchanged)To install and configure Cassandra on a particular host, we can use
- ...
- # JAVA_HOME can optionally be set here
- JAVA_HOME="<%= @JAVA_HOME_DIRECTORY %>"
- ...
The last step in the script creates a boot script, such that Cassandra starts when the host is started.
- #!/bin/sh
- # directory where the tar file is located
- SOFTWARE_DIRECTORY="/u01/software/apache/cassandra/2.1.2"
- # user and group that will be the owner of Apache Cassandra
- USER_NAME="weblogic"
- GROUP_NAME="javainstall"
- # directory where Apache Cassandra will be installed
- CASSANDRA_ROOT="/u01/app/apache/cassandra2.1.2"
- # the name of the cluster
- CLUSTER_NAME="TestCluster"
- # the name of the cassandra instance (only used for flight recording purposes)
- SERVER_NAME="cassandra"
- # the number of tokens randomly assigned to the node on the ring
- NUM_TOKENS="256"
- # address to bind to and tell other Cassandra nodes to connect to
- LISTEN_ADDRESS=$(hostname)
- # address to bind the Thrift RPC service and native transport server to
- RPC_ADDRESS="0.0.0.0"
- # if rpc_address is set to 0.0.0.0, broadcast_rpc_address must be set to a value other than 0.0.0.0
- BROADCAST_RPC_ADDRESS=$(hostname)
- # comma-delimited list of hosts that are deemed contact points (this list is used to find nodes and learn the topology of the ring)
- SEED_ADDRESSES="machine1.com"
- # endpoint snitch, the snitch has two functions:
- # - teach Cassandra about the network topology to route requests efficiently
- # - allow Cassandra to spread replicas around the cluster to avoid correlated failures.
- ENDPOINT_SNITCH="SimpleSnitch"
- # storage port
- STORAGE_PORT="7080"
- # ssl storage port
- SSL_STORAGE_PORT="7443"
- # native transport server port
- NATIVE_TRANSPORT_PORT="9042"
- # port for Thrift to listen for clients on
- RPC_PORT="9160"
- # Java settings
- # directory such that JAVA_HOME_DIRECTORY/bin contains the java executable
- JAVA_HOME_DIRECTORY="/u01/app/oracle/weblogic12.1.3/jdk1.8.0_31"
- # heap size (Xmx and Xms are set to equal sizes
- HEAP_SIZE="1024m"
- # nursery size (Xmn)
- NURSERY_SIZE="256m"
- # as we are using the garbage first collector give a goal for the pause times
- PAUSE_TIME_GOAL_MILLIS="200"
- # port over which JMX connections are accepted
- JMX_PORT="7199"
- extract_template() {
- echo "EXTRACTING TEMPLATE"
- # the apache-cassandra-2.1.2.tar.gz contains the following directory structure
- # /CASSANDRA_ROOT
- # /bin
- # cassandra (used to start apache cassandra)
- # cassandra.in.sh (sets environment variables, such as CASSANDRA_HOME and JAVA_HOME)
- # /conf
- # cassandra.yaml (apache cassandra storage configuration)
- # cassandra-env.sh (sets the JVM options)
- # /data (contains data files)
- # /lib (contains libraries)
- if [ ! -d "${CASSANDRA_ROOT}" ]; then
- mkdir -p ${CASSANDRA_ROOT}
- fi
- tar xf ${SOFTWARE_DIRECTORY}/apache-cassandra-2.1.2.tar.gz -C ${CASSANDRA_ROOT}
- ROOT_CASSANDRA_ROOT=$(echo ${CASSANDRA_ROOT} | cut -d "/" -f2)
- chown -R ${USER_NAME}:${GROUP_NAME} /${ROOT_CASSANDRA_ROOT}
- }
- edit_files() {
- echo "EDITING cassandra.in.sh"
- sed -i -e '/<%= @JAVA_HOME_DIRECTORY %>/ s;<%= @JAVA_HOME_DIRECTORY %>;'${JAVA_HOME_DIRECTORY}';g' ${CASSANDRA_ROOT}/bin/cassandra.in.sh
- echo "EDITING cassandra.yaml"
- sed -i -e '/<%= @CLUSTER_NAME %>/ s;<%= @CLUSTER_NAME %>;'${CLUSTER_NAME}';g' \
- -e '/<%= @NUM_TOKENS %>/ s;<%= @NUM_TOKENS %>;'${NUM_TOKENS}';g' \
- -e '/<%= @SEED_ADDRESSES %>/ s;<%= @SEED_ADDRESSES %>;'${SEED_ADDRESSES}';g' \
- -e '/<%= @STORAGE_PORT %>/ s;<%= @STORAGE_PORT %>;'${STORAGE_PORT}';g' \
- -e '/<%= @SSL_STORAGE_PORT %>/ s;<%= @SSL_STORAGE_PORT %>;'${SSL_STORAGE_PORT}';g' \
- -e '/<%= @LISTEN_ADDRESS %>/ s;<%= @LISTEN_ADDRESS %>;'${LISTEN_ADDRESS}';g' \
- -e '/<%= @NATIVE_TRANSPORT_PORT %>/ s;<%= @NATIVE_TRANSPORT_PORT %>;'${NATIVE_TRANSPORT_PORT}';g' \
- -e '/<%= @RPC_ADDRESS %>/ s;<%= @RPC_ADDRESS %>;'${RPC_ADDRESS}';g' \
- -e '/<%= @BROADCAST_RPC_ADDRESS %>/ s;<%= @BROADCAST_RPC_ADDRESS %>;'${BROADCAST_RPC_ADDRESS}';g' \
- -e '/<%= @RPC_PORT %>/ s;<%= @RPC_PORT %>;'${RPC_PORT}';g' \
- -e '/<%= @ENDPOINT_SNITCH %>/ s;<%= @ENDPOINT_SNITCH %>;'${ENDPOINT_SNITCH}';g' ${CASSANDRA_ROOT}/conf/cassandra.yaml
- echo "EDITING cassandra-env.sh"
- sed -i -e '/<%= @HEAP_SIZE %>/ s;<%= @HEAP_SIZE %>;'${HEAP_SIZE}';g' \
- -e '/<%= @NURSERY_SIZE %>/ s;<%= @NURSERY_SIZE %>;'${NURSERY_SIZE}';g' \
- -e '/<%= @JMX_PORT %>/ s;<%= @JMX_PORT %>;'${JMX_PORT}';g' \
- -e '/<%= @PAUSE_TIME_GOAL_MILLIS %>/ s;<%= @PAUSE_TIME_GOAL_MILLIS %>;'${PAUSE_TIME_GOAL_MILLIS}';g' \
- -e '/<%= @SERVER_NAME %>/ s;<%= @SERVER_NAME %>;'${SERVER_NAME}';g' ${CASSANDRA_ROOT}/conf/cassandra-env.sh
- }
- create_boot_script() {
- echo "CREATING BOOT SCRIPT"
- touch /etc/rc.d/init.d/cassandra
- chmod u+x /etc/rc.d/init.d/cassandra
- echo '#!/bin/sh
- #
- # chkconfig: - 95 20
- #
- # description: controls the Cassandra runtime lifecycle
- # processname: cassandra
- #
- # Source function library.
- . /etc/rc.d/init.d/functions
- RETVAL=0
- SERVICE="cassandra"
- USER="'${USER_NAME}'"
- CASSANDRA_HOME="'${CASSANDRA_ROOT}'"
- LOCK_FILE="/var/lock/subsys/${SERVICE}"
- start() {
- echo "Starting Cassandra"
- su - ${USER} -c "${CASSANDRA_HOME}/bin/cassandra -p ${CASSANDRA_HOME}/cassandra.pid" >/dev/null 2>/dev/null &
- RETVAL=$?
- [ $RETVAL -eq 0 ] && success || failure
- echo
- [ $RETVAL -eq 0 ] && touch ${LOCK_FILE}
- return $RETVAL
- }
- stop() {
- echo "Stopping Cassandra"
- su - ${USER} -c "kill -TERM $(cat ${CASSANDRA_HOME}/cassandra.pid)"
- RETVAL=$?
- [ $RETVAL -eq 0 ] && success || failure
- echo
- [ $RETVAL -eq 0 ] && rm -r ${LOCK_FILE}
- return $RETVAL
- }
- check() {
- echo "Checking Cassandra"
- PID=$(pgrep -of org.apache.cassandra.service.CassandraDaemon)
- RETVAL=$?
- if [ $RETVAL -eq 0 ]; then
- echo "Cassandra is running on this host with PID=$PID"
- netstat -anp | grep $PID
- else
- echo "Cassandra is not running on this host"
- fi
- return $RETVAL
- }
- case "$1" in
- start)
- start
- ;;
- stop)
- stop
- ;;
- restart)
- check
- stop
- start
- check
- ;;
- check)
- check
- ;;
- *)
- echo $"Usage: $0 {start|stop|restart|check}"
- exit 1
- esac
- exit $?' > /etc/rc.d/init.d/cassandra
- chkconfig --add cassandra
- chkconfig cassandra on
- }
- extract_template
- edit_files
- create_boot_script
Set-up data model
Cassandra's data model is a partitioned row store with tunable consistency. Rows are organized into tables; the first component of a table's primary key is the partition key; within a partition, rows are clustered by the remaining columns of the key. Other columns can be indexed separately from the primary key. Tables can be created, dropped, and altered at runtime without blocking updates and queries.A keyspace is the CQL counterpart to an SQL database, but a little different. The Cassandra keyspace is a namespace that defines how data is replicated on nodes. Typically, a cluster has one keyspace per application. Replication is controlled on a per-keyspace basis, so data that has different replication requirements typically resides in different keyspaces. Keyspaces are not designed to be used as a significant map layer within the data model. Keyspaces are designed to controldata replication for a set of tables.
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. Note that we canincrease the replication factor and add the desired number of nodes later. Two replication strategies are available:
SimpleStrategy, use for a single data center only. In the case of more than one data center, use theNetworkTopologyStrategy.NetworkTopologyStrategy, recommended for most deployments because it is much easier to expand to multiple data centers when necessary.
- [weblogic@machine1 bin]$ ./cqlsh machine1.com 9042
- Connected to TestCluster at machine1.com:9042.
- [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
- Use HELP for help.
- # create keyspace
- cqlsh> CREATE KEYSPACE IF NOT EXISTS test WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 2};
- # create table
- cqlsh> CREATE TABLE IF NOT EXISTS test.persons ( sofinummer int PRIMARY KEY , naam text ) WITH compression = {'sstable_compression': 'LZ4Compressor' } AND compaction = {'class': 'LeveledCompactionStrategy'};
- # check created keyspace
- cqlsh> SELECT * FROM system.schema_keyspaces;
- keyspace_name | durable_writes | strategy_class | strategy_options
- ---------------+----------------+---------------------------------------------+----------------------------
- test | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
- system | True | org.apache.cassandra.locator.LocalStrategy | {}
- system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
- (3 rows)
- # check created table
- cqlsh> SELECT * FROM system.schema_columnfamilies WHERE columnfamily_name = 'persons' ALLOW FILTERING;
- keyspace_name | columnfamily_name | bloom_filter_fp_chance | caching | cf_id | column_aliases | comment | compaction_strategy_class | compaction_strategy_options | comparator | compression_parameters | default_time_to_live | default_validator | dropped_columns | gc_grace_seconds | index_interval | is_dense | key_aliases | key_validator | local_read_repair_chance | max_compaction_threshold | max_index_interval | memtable_flush_period_in_ms | min_compaction_threshold | min_index_interval | read_repair_chance | speculative_retry | subcomparator | type | value_alias
- ---------------+-------------------+------------------------+---------------------------------------------+--------------------------------------+----------------+---------+--------------------------------------------------------------+-----------------------------+-----------------------------------------------------------------------------------------+--------------------------------------------------------------------------+----------------------+-------------------------------------------+-----------------+------------------+----------------+----------+----------------+-------------------------------------------+--------------------------+--------------------------+--------------------+-----------------------------+--------------------------+--------------------+--------------------+-------------------+---------------+----------+-------------
- test | persons | 0.1 | {"keys":"ALL", "rows_per_partition":"NONE"} | 296a2de0-a6ea-11e4-a8b4-b97fe3ba0f40 | [] | | org.apache.cassandra.db.compaction.LeveledCompactionStrategy | {} | org.apache.cassandra.db.marshal.CompositeType(org.apache.cassandra.db.marshal.UTF8Type) | {"sstable_compression":"org.apache.cassandra.io.compress.LZ4Compressor"} | 0 | org.apache.cassandra.db.marshal.BytesType | null | 864000 | null | False | ["sofinummer"] | org.apache.cassandra.db.marshal.Int32Type | 0.1 | 32 | 2048 | 0 | 4 | 128 | 0 | 99.0PERCENTILE | null | Standard | null
- (1 rows)
- cqlsh> SELECT * FROM system.schema_columns WHERE columnfamily_name = 'persons' ALLOW FILTERING;
- keyspace_name | columnfamily_name | column_name | component_index | index_name | index_options | index_type | type | validator
- ---------------+-------------------+-------------+-----------------+------------+---------------+------------+---------------+-------------------------------------------
- test | persons | naam | 0 | null | null | null | regular | org.apache.cassandra.db.marshal.UTF8Type
- test | persons | sofinummer | null | null | null | null | partition_key | org.apache.cassandra.db.marshal.Int32Type
- (2 rows)
- # to check the cluster we can use nodetool (nodetool help status, provides more information)
- [weblogic@machine1 bin]$ ./nodetool --host machine1.com --port 7199 status test
- Datacenter: datacenter1
- =======================
- Status=Up/Down
- |/ State=Normal/Leaving/Joining/Moving
- -- Address Load Tokens Owns (effective) Host ID Rack
- UN 192.168.231.110 77.89 KB 256 100.0% 6f563cc6-3e2f-4089-b28c-bdb58959c214 rack1
- UN 192.168.231.100 104.46 KB 256 100.0% 0eddc3ea-6692-4c62-9135-67ef37d655b5 rack1
Test
To test the set-up we use a Java client. For the Java client to be able to connect, we need theCassandra Java Driver. The driver uses the binary protocol (start_native_transport: true,native_transport_port: 9042, and rpc_address: <hostname reachable from the client> must be set in thecassandra.yaml file). The document Writing your first client describes a step-by-step example.The driver discovers nodes that constitute a cluster by querying the contact points used in building the cluster object. After this it is up to the cluster's load balancing policy to keep track of node events. If a Cassandra node fails or becomes unreachable, the Java driver automatically and transparently tries other nodes in the cluster and schedules reconnections to the dead nodes in the background. More information on the driver can be found in thedriver reference.
As an example, we can use the following
- # obtain a Cluster and a Session instance, and make those available for future use
- package model.utils;
- import com.datastax.driver.core.Cluster;
- import com.datastax.driver.core.ProtocolOptions;
- import com.datastax.driver.core.Session;
- import java.net.InetSocketAddress;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.concurrent.TimeUnit;
- public class CassandraUtil {
- private static final Cluster cluster;
- private static final Session session;
- private static final String[] HOST_NAMES = {"machine1.com","machine2.com"};
- private static final Integer PORT = ProtocolOptions.DEFAULT_PORT;
- private static final String KEYSPACE = "test";
- private CassandraUtil() {
- }
- static {
- try {
- List<InetSocketAddress> addresses = new ArrayList<>();
- for (String host: HOST_NAMES) {
- InetSocketAddress address = new InetSocketAddress(host, PORT);
- addresses.add(address);
- }
- System.out.println("initializing");
- long start_time = System.nanoTime();
- //cluster = Cluster.builder().addContactPoints(HOST_NAMES).build();
- cluster = Cluster.builder().addContactPointsWithPorts(addresses).build();
- session = cluster.connect(KEYSPACE);
- long end_time = System.nanoTime();
- System.out.println("done initializing");
- long total_time = TimeUnit.NANOSECONDS.toMillis(end_time - start_time);
- System.out.println("initializing took: " + total_time + " ms.");
- } catch (Throwable ex) {
- ex.printStackTrace();
- throw new ExceptionInInitializerError(ex);
- }
- }
- public static Cluster getCluster() {
- return cluster;
- }
- public static Session getSession() {
- return session;
- }
- }
- # entity representing our table (used by Spring Data)
- package model.entities;
- import org.springframework.data.cassandra.mapping.PrimaryKey;
- import org.springframework.data.cassandra.mapping.Table;
- @Table("persons")
- public class Person implements Comparable<Person> {
- @PrimaryKey
- private Integer sofinummer;
- private String naam;
- public Integer getSofinummer() {
- return sofinummer;
- }
- public void setSofinummer(Integer sofinummer) {
- this.sofinummer = sofinummer;
- }
- public String getNaam() {
- return naam;
- }
- public void setNaam(String naam) {
- this.naam = naam;
- }
- @Override
- public boolean equals(Object object) {
- if (this == object) {
- return true;
- }
- if (object == null) {
- return false;
- }
- if (!(object instanceof Person)) {
- return false;
- }
- Person person = (Person) object;
- return getSofinummer().equals(person.getSofinummer());
- }
- @Override
- public int hashCode() {
- return getSofinummer().hashCode();
- }
- @Override
- public String toString() {
- return getNaam() + " " + getSofinummer();
- }
- @Override
- public int compareTo(Person other) {
- return this.getNaam().compareTo(other.getNaam());
- }
- }
in which we have also used Spring Data, and in particular Spring Data Cassandra. In order to run the example above, we need to have the following .jar files in the class path
- package test;
- import com.datastax.driver.core.*;
- import com.datastax.driver.core.querybuilder.Batch;
- import com.datastax.driver.core.querybuilder.QueryBuilder;
- import com.datastax.driver.core.querybuilder.Select;
- import model.entities.Person;
- import model.utils.CassandraUtil;
- import org.springframework.data.cassandra.core.CassandraOperations;
- import org.springframework.data.cassandra.core.CassandraTemplate;
- import java.util.List;
- public class Test {
- public static void main(String[] args) {
- try {
- Test test = new Test();
- test.getMetaData();
- test.useCQL();
- test.useSpring();
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- CassandraUtil.getSession().close();
- CassandraUtil.getCluster().close();
- }
- }
- public void getMetaData() {
- Configuration configuration = CassandraUtil.getCluster().getConfiguration();
- Metadata metadata = CassandraUtil.getCluster().getMetadata();
- System.out.println("Connected to cluster: " + metadata.getClusterName());
- for (Host host : metadata.getAllHosts()) {
- System.out.println("- host: " + host.getDatacenter() + ", " +
- host.getRack() + ", " +
- host.getAddress() + ", " +
- configuration.getPolicies().getLoadBalancingPolicy().distance(host));
- }
- Metrics metrics = CassandraUtil.getCluster().getMetrics();
- System.out.println("- connected to hosts: " + metrics.getConnectedToHosts().getValue());
- System.out.println("- open connections: " + metrics.getOpenConnections().getValue());
- TableMetadata.Options options = metadata.getKeyspace("test").getTable("persons").getOptions();
- System.out.println("Table options:");
- System.out.println("- " + options.getCaching());
- System.out.println("- " + options.getCompaction());
- System.out.println("- " + options.getCompression());
- }
- public void useCQL() {
- CassandraUtil.getSession().execute("INSERT INTO test.persons (sofinummer, naam) VALUES (123456789, 'John Zorn');");
- CassandraUtil.getSession().execute("INSERT INTO test.persons (sofinummer, naam) VALUES (987654321, 'Frank Zappa');");
- ResultSet results = CassandraUtil.getSession().execute("SELECT * FROM test.persons");
- for (Row row : results) {
- System.out.println(row.getInt("sofinummer") + ", " + row.getString("naam"));
- }
- }
- public void useSpring() {
- Person johnzorn = new Person();
- johnzorn.setSofinummer(123456789);
- johnzorn.setNaam("John Zorn");
- Person frankzappa = new Person();
- frankzappa.setSofinummer(987654321);
- frankzappa.setNaam("Frank Zappa");
- CassandraOperations operations = new CassandraTemplate(CassandraUtil.getSession());
- operations.insert(johnzorn);
- operations.insert(frankzappa);
- Select select = QueryBuilder.select().from("test", "persons");
- List<Person> persons = operations.select(select, Person.class);
- persons.forEach(System.out::println);
- }
- }
The Cassandra Driver (and related .jar files) can be obtained here. The Spring .jar files can be obtained from the Spring Repository. We can also obtain the .jar files using Maven, for example, when using IntelliJ IDEA, click
- aopalliance-1.0.jar
- cassandra-driver-core-2.1.4.jar
- commons-logging-1.1.3.jar
- guava-14.0.1.jar
- metrics-core-3.0.2.jar
- slf4j-api-1.7.5.jar
- spring-aop-4.1.4.RELEASE.jar
- spring-beans-4.1.4.RELEASE.jar
- spring-context-4.1.4.RELEASE.jar
- spring-core-4.1.4.RELEASE.jar
- spring-cql-1.1.2.RELEASE.jar
- spring-data-cassandra-1.1.2.RELEASE.jar
- spring-data-commons-1.9.2.RELEASE.jar
- spring-expression-4.1.4.RELEASE.jar
- spring-tx-4.1.4.RELEASE.jar
File, Project Structure and chooseLibraries; click + and choose from maven. In theDownload Library from Maven Repository screen, enter the artifact id (spring-data-cassandra), press search, select the version to be used (org.springframework.data:spring-data-cassandra:1.1.2.RELEASE), optionallly choose to download the library to a project directory, and click ok.When the example is run, we get the following output
- initializing
- ...
- done initializing
- initializing took: 745 ms.
- Connected to cluster: TestCluster
- - host: datacenter1, rack1, machine2.com/192.168.231.110, LOCAL
- - host: datacenter1, rack1, machine1.com/192.168.231.100, LOCAL
- - connected to hosts: 2
- - open connections: 3
- Table options:
- - {keys=ALL, rows_per_partition=NONE}
- - {class=org.apache.cassandra.db.compaction.LeveledCompactionStrategy}
- - {sstable_compression=org.apache.cassandra.io.compress.LZ4Compressor}
- 123456789, John Zorn
- 987654321, Frank Zappa
- John Zorn 123456789
- Frank Zappa 987654321
Spring
Spring offers the very handy CassandraOperations API, which we can use to create a generic DAO approach as was done in the postFun with Spring. The Spring Data Commons module offers so-called repositories. The central interface in Spring Data repository abstraction is theRepository interface. It takes the domain class to manage as well as the id type of the domain class as type arguments. This interface acts primarily as a marker interface to capture the types to work with and to help discover interfaces that extend this one. The CrudRepository interface provides CRUD functionality for the entity class that is being managed. To implement theCrudRepository we can use something likeIn the constructor we use Generics to retrieve information about the persistent entity class, i.e., find the class of the
- package model.logic;
- import org.springframework.cassandra.core.util.CollectionUtils;
- import org.springframework.data.cassandra.core.CassandraOperations;
- import org.springframework.data.repository.CrudRepository;
- import java.io.Serializable;
- import java.lang.reflect.ParameterizedType;
- import java.lang.reflect.Type;
- public abstract class GenericCassandraRepository<T, ID extends Serializable> implements CrudRepository<T, ID> {
- private Class<T> persistentClass;
- private CassandraOperations operations;
- public GenericCassandraRepository(CassandraOperations operations) {
- Type type = getClass().getGenericSuperclass();
- if (type instanceof ParameterizedType) {
- ParameterizedType parameterizedType = (ParameterizedType) type;
- setPersistentClass((Class<T>) parameterizedType.getActualTypeArguments()[0]);
- } else {
- System.out.println("Not an instance of parameterized type: " + type);
- }
- setOperations(operations);
- }
- public Class<T> getPersistentClass() {
- return persistentClass;
- }
- public void setPersistentClass(Class<T> persistentClass) {
- this.persistentClass = persistentClass;
- }
- public CassandraOperations getOperations() {
- return operations;
- }
- public void setOperations(CassandraOperations operations) {
- this.operations = operations;
- }
- @Override
- public <S extends T> S save(S entity) {
- return getOperations().insert(entity);
- }
- @Override
- public <S extends T> Iterable<S> save(Iterable<S> entities) {
- return getOperations().insert(CollectionUtils.toList(entities));
- }
- @Override
- public T findOne(ID id) {
- return getOperations().selectOneById(getPersistentClass(), id);
- }
- @Override
- public boolean exists(ID id) {
- return getOperations().exists(getPersistentClass(), id);
- }
- @Override
- public Iterable<T> findAll() {
- return getOperations().selectAll(getPersistentClass());
- }
- @Override
- public Iterable<T> findAll(Iterable<ID> entities) {
- return getOperations().selectBySimpleIds(getPersistentClass(), entities);
- }
- @Override
- public long count() {
- return getOperations().count(getPersistentClass());
- }
- @Override
- public void delete(ID id) {
- getOperations().deleteById(getPersistentClass(), id);
- }
- @Override
- public void delete(T entity) {
- getOperations().delete(entity);
- }
- @Override
- public void delete(Iterable<? extends T> entities) {
- getOperations().delete(CollectionUtils.toList(entities));
- }
- @Override
- public void deleteAll() {
- getOperations().deleteAll(getPersistentClass());
- }
- }
T generic argument. If we look at the JavaDocs the following can be expected:- If the superclass is a parameterized type, the
Typeobject returned must accurately reflect the actual type parameters used in the source code. The parameterized type representing the superclass is created if it had not been created before. - A parameterized type is created the first time it is needed by a reflective method, as specified in this package. When a parameterized type
pis created, the generic type declaration thatpinstantiates is resolved, and all type arguments ofpare created recursively. - A type variable is created the first time it is needed by a reflective method, as specified in this package. If a type variable
tis referenced by a type (i.e, class, interface or annotation type)T, andTis declared by the n-th enclosing class ofT, then the creation oftrequires the resolution of the i-th enclosing class of T, for i = 0 to n, inclusive.
CrudInterface interface can be extended for particular entities, for example,with the corresponding implementation:
- package model.logic;
- import model.entities.Person;
- import org.springframework.data.repository.CrudRepository;
- public interface PersonRepository extends CrudRepository<Person, Integer> {
- public void sortAllPersons();
- }
- package model.logic;
- import model.entities.Person;
- import org.springframework.cassandra.core.util.CollectionUtils;
- import org.springframework.data.cassandra.core.CassandraOperations;
- import java.util.List;
- import java.util.concurrent.TimeUnit;
- public class PersonRepositoryImpl extends GenericCassandraRepository<Person, Integer> implements PersonRepository {
- public PersonRepositoryImpl(CassandraOperations operations) {
- super(operations);
- }
- @Override
- public void sortAllPersons() {
- List<Person> persons = CollectionUtils.toList(super.findAll());
- long sequential_start_time = System.nanoTime();
- persons.stream().sorted().count();
- long sequential_end_time = System.nanoTime();
- long sequential_total_time = TimeUnit.NANOSECONDS.toMillis(sequential_end_time - sequential_start_time);
- System.out.println("sequential sort took: " + sequential_total_time + " ms.");
- long parallel_start_time = System.nanoTime();
- persons.parallelStream().sorted().count();
- long parallel_end_time = System.nanoTime();
- long parallel_total_time = TimeUnit.NANOSECONDS.toMillis(parallel_end_time - parallel_start_time);
- System.out.println("parallel sort took: " + parallel_total_time + " ms.");
- }
- }
Using Spring configuration
We can also configure Cassandra (create aCluster and Session instance; create aCassandraOperations instance, and inject that into our PersonRepository) by using Spring configuration, for example,
- # cassandra.properties
- cassandra.contactpoints=machine1.com,machine.com
- cassandra.port=9042
- cassandra.keyspace=test
- # spring configuration
- <beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
- xmlns:cassandra="http://www.springframework.org/schema/data/cassandra"
- xmlns:context="http://www.springframework.org/schema/context"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
- http://www.springframework.org/schema/data/cassandra http://www.springframework.org/schema/data/cassandra/spring-cassandra.xsd
- http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
- <context:property-placeholder location="classpath:cassandra.properties"/>
- <cassandra:cluster id="cluster" contact-points="${cassandra.contactpoints}" port="${cassandra.port}"/>
- <cassandra:session id="session" cluster-ref="cluster" keyspace-name="${cassandra.keyspace}"/>
- <cassandra:mapping entity-base-packages="model.entities"/>
- <cassandra:converter/>
- <cassandra:template id="operations" session-ref="session"/>
- <beans:bean id="personrepository" class="model.logic.PersonRepositoryImpl">
- <beans:constructor-arg ref="operations"/>
- </beans:bean>
- </beans:beans>
Which can be used in the following manner
- # SpringUtil class used to obtain instances from the Spring ApplicationContext
- package model.util;
- import com.datastax.driver.core.Cluster;
- import com.datastax.driver.core.Session;
- import model.logic.PersonRepository;
- import org.springframework.context.ApplicationContext;
- import org.springframework.context.support.ClassPathXmlApplicationContext;
- import java.util.concurrent.TimeUnit;
- public class SpringUtil {
- private static ApplicationContext applicationContext;
- private SpringUtil(){
- }
- static {
- System.out.println("initializing");
- long start_time = System.nanoTime();
- applicationContext = new ClassPathXmlApplicationContext("spring-config.xml");
- long end_time = System.nanoTime();
- System.out.println("done initializing");
- long total_time = TimeUnit.NANOSECONDS.toMillis(end_time - start_time);
- System.out.println("initializing took: " + total_time + " ms.");
- }
- public static PersonRepository getPersonRepository() {
- return applicationContext.getBean("personrepository", PersonRepository.class);
- }
- public static Cluster getCluster() {
- return applicationContext.getBean("cluster", Cluster.class);
- }
- public static Session getSession() {
- return applicationContext.getBean("session", Session.class);
- }
- }
When the example is run, we get the following output
- package test;
- import model.entities.Person;
- import model.logic.PersonRepository;
- import model.util.SpringUtil;
- import java.util.Random;
- public class Test {
- private Random generator = new Random();
- public static void main(String[] args) {
- Test test = new Test();
- try {
- test.doSomeTest(SpringUtil.getPersonRepository());
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- SpringUtil.getSession().close();
- SpringUtil.getCluster().close();
- }
- }
- private void doSomeTest(PersonRepository repository) {
- for (int i = 0; i < 10; i++) {
- // generate a random data
- Person person = createPerson();
- // insert or update a person
- repository.save(person);
- if (generator.nextDouble() < 0.001) {
- // remove a person
- repository.delete(generateSofinummer());
- // get all persons
- System.out.println("number of persons: " + repository.count());
- repository.sortAllPersons();
- } else {
- // find a person by ID
- repository.findOne(generateSofinummer());
- }
- }
- }
- private Person createPerson() {
- Person person = new Person();
- person.setSofinummer(generateSofinummer());
- person.setNaam(Long.toString(Math.abs(generator.nextLong()), 36));
- return person;
- }
- private Integer generateSofinummer() {
- return generator.nextInt(100000);
- }
- }
Initialization using the Spring configuration is much slower than the direct approach as was done in the
- initializing
- ...
- done initializing
- initializing took: 6511 ms.
CassandraUtil class. So in the test below, we will stick to the 'CassandraUtil'-approach.Test
To test it all we can use something likeWe also start a flight recording on the Cassandra nodes, in order to see how the JVM is doing. To create flight recordings we will use the script presented in the postJava Virtual Machine Code Generation and Optimization (this is also the reason why we set the extra parameter
- package test;
- import model.entities.Person;
- import model.logic.PersonRepository;
- import model.logic.PersonRepositoryImpl;
- import model.utils.CassandraUtil;
- import org.springframework.data.cassandra.core.CassandraOperations;
- import org.springframework.data.cassandra.core.CassandraTemplate;
- import java.util.Random;
- public class LoadTest {
- private Random generator = new Random();
- public static void main(String[] args) {
- LoadTest test = new LoadTest();
- try {
- CassandraOperations operations = new CassandraTemplate(CassandraUtil.getSession());
- PersonRepository repository = new PersonRepositoryImpl(operations);
- test.doRandomReadWriteTest(repository);
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- CassandraUtil.getSession().close();
- CassandraUtil.getCluster().close();
- }
- }
- private void doRandomReadWriteTest(PersonRepository repository) {
- while (true) {
- // generate a random data
- Person person = createPerson();
- // insert or update a person
- repository.save(person);
- if (generator.nextDouble() < 0.001) {
- // remove a person
- repository.delete(generateSofinummer());
- // get all persons
- System.out.println("number of persons: " + repository.count());
- repository.sortAllPersons();
- } else {
- // find a person by ID
- repository.findOne(generateSofinummer());
- }
- }
- }
- private Person createPerson() {
- Person person = new Person();
- person.setSofinummer(generateSofinummer());
- person.setNaam(Long.toString(Math.abs(generator.nextLong()), 36));
- return person;
- }
- private Integer generateSofinummer() {
- return generator.nextInt(100000);
- }
- }
-Dname=<%= @SERVER_NAME %> in the cassandra-env.sh file, such that we can easily find the process id of the Cassandra process by using the provided name), i.e.,When the test is run, the following output is observed (nice to see what parallel sorting can do)
- [weblogic@machine1 monitor]$ ./FlightRecording.sh
- Provide an <ACTION> and a <SERVER_NAME>
- Usage FlightRecording.sh <ACTION> <SERVER_NAME>, <ACTION> must be one of {start|stop|dump|check|clean}
- [weblogic@machine1 monitor]$ ./FlightRecording.sh start cassandra
- Starting Flight Recording for server: cassandra with PID 2783
- 2783:
- Started recording 1. The result will be written to: /home/weblogic/cassandra-29-01-2015_16:39:44.jfr
- [weblogic@machine1 monitor]$ ./FlightRecording.sh check cassandra
- 2783:
- Recording: recording=1 name="cassandra" duration=20m filename="/home/weblogic/cassandra-29-01-2015_16:39:44.jfr" compress=false (running)
Monitoring results. To set-up an MBean Browser we have to provide a JMX URL, i.e,
- number of persons: 1377
- sequential sort took: 11 ms.
- parallel sort took: 12 ms.
- number of persons: 1694
- sequential sort took: 3 ms.
- parallel sort took: 4 ms.
- number of persons: 4916
- sequential sort took: 8 ms.
- parallel sort took: 9 ms.
- ...
- number of persons: 10128
- sequential sort took: 6 ms.
- parallel sort took: 6 ms.
- ...
- number of persons: 20018
- sequential sort took: 13 ms.
- parallel sort took: 6 ms.
- ...
- number of persons: 30236
- sequential sort took: 17 ms.
- parallel sort took: 6 ms
- ...
- number of persons: 40829
- sequential sort took: 20 ms.
- parallel sort took: 7 ms.
- ...
- number of persons: 51534
- sequential sort took: 26 ms.
- parallel sort took: 9 ms.
- ...
- number of persons: 60884
- sequential sort took: 36 ms.
- parallel sort took: 13 ms.
- ...
- number of persons: 70080
- sequential sort took: 51 ms.
- parallel sort took: 17 ms.
- ...
- number of persons: 80022
- sequential sort took: 60 ms.
- parallel sort took: 21 ms.
- ...
- number of persons: 90167
- sequential sort took: 56 ms.
- parallel sort took: 20 ms.
- ...
- number of persons: 95031
- sequential sort took: 66 ms.
- parallel sort took: 22 ms
- ...
- number of persons: 99390
- sequential sort took: 59 ms.
- parallel sort took: 19 ms.
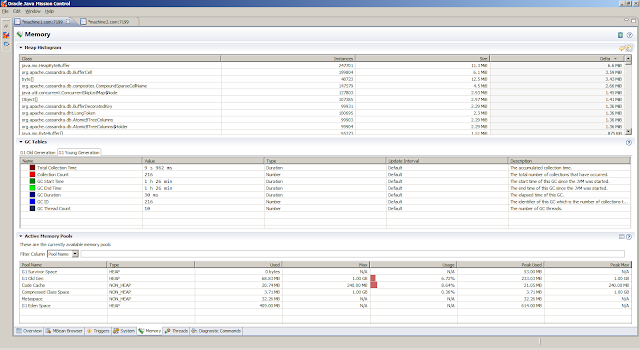
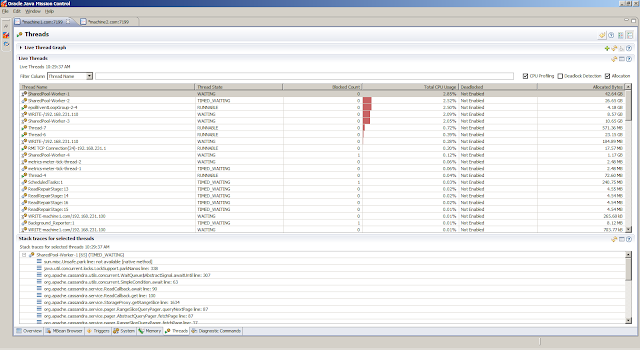
service:jmx:rmi:///jndi/rmi://<HOSTNAME>:<JMX_PORT>/jmxrmi. The following shows snapshots from the JMX Console in Java Mission Controllsof to get insight in the open files, and sar to obtain statistics related to the disk.From the Flight Recording, we can obtain detailed information on how the Java Virtual Machine is doing. The
- # list open files
- [weblogic@machine1 cassandra2.1.2]$ lsof -i -a -p 2783
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- java 2783 weblogic 53u IPv4 14637 0t0 TCP *:7199 (LISTEN)
- java 2783 weblogic 54u IPv4 14640 0t0 TCP *:44168 (LISTEN)
- java 2783 weblogic 59u IPv4 18410 0t0 TCP machine1.com:35531->machine2.com:empowerid (ESTABLISHED)
- java 2783 weblogic 60u IPv4 18411 0t0 TCP machine1.com:empowerid->machine1.com:39417 (ESTABLISHED)
- java 2783 weblogic 61r IPv6 19642 0t0 TCP machine1.com:9042->192.168.231.1:53436 (ESTABLISHED)
- java 2783 weblogic 75r IPv4 19619 0t0 TCP machine1.com:39418->machine1.com:empowerid (ESTABLISHED)
- java 2783 weblogic 88u IPv4 14894 0t0 TCP machine1.com:empowerid (LISTEN)
- java 2783 weblogic 90u IPv6 15012 0t0 TCP machine1.com:9042 (LISTEN)
- java 2783 weblogic 91u IPv4 15014 0t0 TCP machine1.com:apani1 (LISTEN)
- java 2783 weblogic 92u IPv4 18409 0t0 TCP machine1.com:empowerid->machine2.com:57281 (ESTABLISHED)
- java 2783 weblogic 95u IPv4 19603 0t0 TCP machine1.com:35536->machine2.com:empowerid (ESTABLISHED)
- java 2783 weblogic 96u IPv4 19606 0t0 TCP machine1.com:39417->machine1.com:empowerid (ESTABLISHED)
- java 2783 weblogic 97u IPv4 19607 0t0 TCP machine1.com:empowerid->machine1.com:39418 (ESTABLISHED)
- java 2783 weblogic 99u IPv4 19620 0t0 TCP machine1.com:empowerid->machine2.com:57291 (ESTABLISHED)
- # i/o statistics
- [weblogic@machine1 cassandra2.1.2]$ sar -b
- Linux 2.6.32-504.3.3.el6.x86_64 (machine1.com) 01/29/2015 _x86_64_ (4 CPU)
- 04:30:01 PM tps rtps wtps bread/s bwrtn/s
- 04:40:01 PM 4.43 1.82 2.61 70.90 29.22
- 04:50:01 PM 18.95 0.04 18.91 1.82 279.62
- 05:00:01 PM 31.86 0.45 31.41 132.36 478.27
- Average: 18.15 0.79 17.36 68.57 257.92
- # individual block device i/o
- [weblogic@machine1 cassandra2.1.2]$ sar -p -d
- Linux 2.6.32-504.3.3.el6.x86_64 (machine1.com) 01/29/2015 _x86_64_ (4 CPU)
- 04:30:01 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
- 04:40:01 PM sda 1.57 35.45 14.67 31.86 0.03 16.66 8.14 1.28
- 04:40:01 PM vg_machine1-lv_root 2.86 35.45 14.55 17.49 0.07 24.30 4.48 1.28
- 04:40:01 PM vg_machine1-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- 04:50:01 PM sda 1.45 0.91 139.81 96.75 0.03 23.39 13.28 1.93
- 04:50:01 PM vg_machine1-lv_root 17.49 0.91 139.81 8.04 0.84 48.16 1.10 1.93
- 04:50:01 PM vg_machine1-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- 05:00:01 PM sda 1.74 66.18 239.14 175.20 0.11 62.79 15.40 2.68
- 05:00:01 PM vg_machine1-lv_root 30.12 66.18 239.14 10.14 8.58 284.98 0.89 2.68
- 05:00:01 PM vg_machine1-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- Average: sda 1.59 34.29 128.98 102.68 0.06 35.24 12.28 1.95
- Average: vg_machine1-lv_root 16.56 34.29 128.94 9.86 3.11 187.95 1.18 1.95
- Average: vg_machine1-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- # swap space
- [weblogic@machine1 cassandra2.1.2]$ sar -S
- Linux 2.6.32-504.3.3.el6.x86_64 (machine1.com) 01/29/2015 _x86_64_ (4 CPU)
- 04:30:01 PM kbswpfree kbswpused %swpused kbswpcad %swpcad
- 04:40:01 PM 4194300 0 0.00 0 0.00
- 04:50:01 PM 4194300 0 0.00 0 0.00
- 05:00:01 PM 4194300 0 0.00 0 0.00
- Average: 4194300 0 0.00 0 0.00
- # CPU and memory usage by the JVM
- [weblogic@machine1 cassandra2.1.2]$ ps -p 2783 -o %cpu,%mem,cmd
- %CPU %MEM CMD
- 39.8 26.3 /u01/app/oracle/weblogic12.1.3/jdk1.8.0_25/bin/java -Xms1024m -Xmx1024m -XX:StringTableSize=1000003 -XX:+UseG1GC
- # run queue and load average
- [weblogic@machine1 cassandra2.1.2]$ sar -q
- Linux 2.6.32-504.3.3.el6.x86_64 (machine1.com) 01/29/2015 _x86_64_ (4 CPU)
- 04:30:01 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
- 04:40:01 PM 0 379 0.09 0.10 0.10
- 04:50:01 PM 0 382 0.00 0.04 0.06
- 05:00:01 PM 0 383 0.29 0.11 0.06
- 05:10:01 PM 0 379 0.00 0.04 0.05
- Average: 0 381 0.10 0.07 0.07
- # after we shutdown machine1.com, we check the status of the cluster
- [weblogic@machine2 bin]$ ./nodetool --host machine2.com --port 7199 status test
- Datacenter: datacenter1
- =======================
- Status=Up/Down
- |/ State=Normal/Leaving/Joining/Moving
- -- Address Load Tokens Owns (effective) Host ID Rack
- UN 192.168.231.110 136.14 KB 256 100.0% 6f563cc6-3e2f-4089-b28c-bdb58959c214 rack1
- DN 192.168.231.100 141.25 KB 256 100.0% 0eddc3ea-6692-4c62-9135-67ef37d655b5 rack1
- [weblogic@machine2 bin]$ ./cqlsh machine2.com 9042
- Connected to TestCluster at machine2.com:9042.
- [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
- Use HELP for help.
- cqlsh> SELECT count(*) FROM test.persons;
- count
- -------
- 99399
- (1 rows)
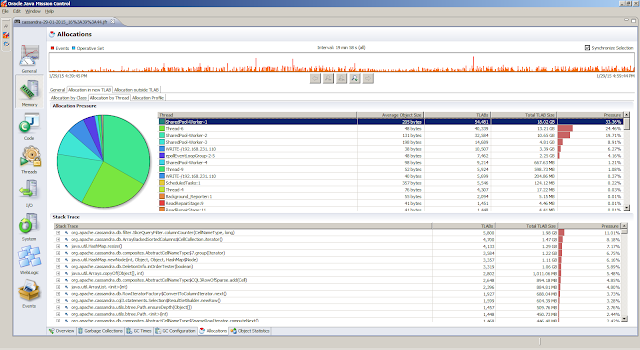
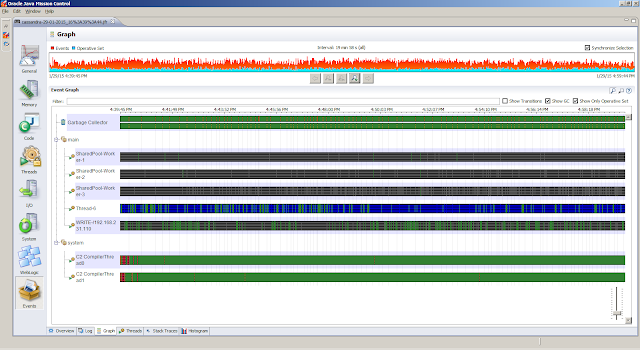
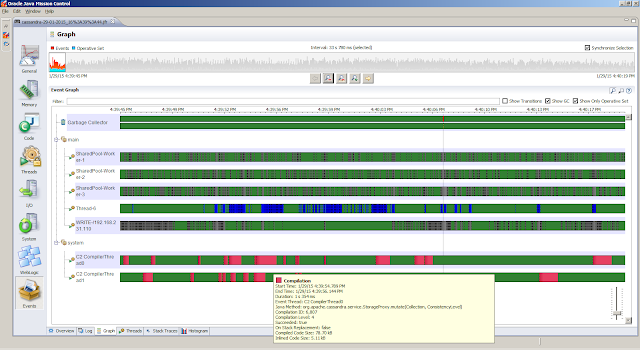
General, Overview tab provides a first peak (the JVM Information tab provides the information about the Java Virtual Machine settings)Memory, Garbage Collections tab provides information regarding the individual garbage collections (such as pause times)Memory, Allocations tab shows information about object allocationsCode, Overview tab shows were the hot spots areCode, Compilations tab gives insight in compilation timesEvents, Graph tab gives insight in how the threads are doing. But first we obtain the top 5 threads from theThreads, Hot Threads tabReferences
[1] Cassandra Documentation.[2] Spring Data Cassandra - Reference Documentation.
0 0
- Cassandra in Spring
- Caching in Cassandra 1.1
- Data Partitioning in Cassandra
- Spring Data Cassandra 说明文档
- What’s new in Cassandra 1.1
- Cassandra
- cassandra
- cassandra
- Cassandra
- Cassandra
- cassandra
- Cassandra
- Cassandra
- cassandra
- Cassandra
- Cassandra
- Cassandra
- Cassandra
- HTM中的TComPicYuv和TVideoIOYuv类(一)
- C/C++刁钻问题各个击破之细说sizeof
- 【leetcode】Isomorphic Strings
- php设计模式之策略模式
- 软件项目估算之代码行估算方法
- Cassandra in Spring
- mysql 1449 : The user specified as a definer ('root'@'%') does not exist 解决方法
- ERROR 1370 (42000): execute command denied to user backupAccount@'localhost' for routine 'databaseNa
- JAVA随记(3)
- HTM中的TComPicYuv和TVideoIOYuv类(二)
- 力所能及之ireport 启动错误cannot find java.exe
- #if, #elif, #else, #endif 使用
- scanf、sscanf中的正则表达式
- 再水一道并查集,hdu1856


