海量数据处理面试题整理
来源:互联网 发布:企业网络架构图 编辑:程序博客网 时间:2024/06/08 14:54
本文整理自July的博客:http://blog.csdn.net/v_JULY_v
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
或者如下阐述(雪域之鹰):
算法思想:分而治之+Hash
(1)IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
(2)可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
(3)对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
(4)可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP。
2、寻找热门查询
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
典型的Top K算法。
文中,给出的最终算法是:
第一步,先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计;
第二步,借助堆这个数据结构,找出Top K,时间复杂度为N'logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N)+ N'*O(logK),(N为1000万,N'为300万)。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案:
(1)顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。
(2)如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
(3)对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似于归并排序)的过程了。
4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
还是典型的TOP K算法,解决方案如下:
方案1:
(1)顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
(2)找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件。
(3)对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
5、给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url。
方案1:
(1)可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
(2)遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
(3)遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0 vs b0,a1 vs b1,...,a999 vs b999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
(4)求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:
如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
6、在2.5亿个整数中找出不重复的整数,注意内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与前面类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
7、腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
(1)因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;这里我们把40亿个数中的每一个用32位的二进制来表示。假设这40亿个数开始放在一个文件中。
(2)然后将这40亿个数分成两类:最高位为0;最高位为1。并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);与要查找的数的最高位比较并接着进入相应的文件再查找。
(3)再然后把这个文件为又分成两类:次最高位为0;次最高位为1。并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了);与要查找的数的次最高位比较并接着进入相应的文件再查找。
(4)以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
附:这里再简单介绍下位图方法:
使用位图法判断整形数组是否存在重复。
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值,即能事先给新数组定长的话效率还能提高一倍。
8、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
9、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
10、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
11、100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
12、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
方案1:这题用trie树比较合适,hash_map也应该能行。
13、一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有2^32个)。我们把0到2^32-1的整数划分为N个范围段,每个段包含(2^32)/N个整数。比如,第一个段位0到2^32/N-1,第二段为(2^32)/N到(2^32)/N-1,…,第N个段为(2^32)(N-1)/N到2^32-1。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于(N^2)/2,而在第k-1个机器上的累加数小于(N^2)/2,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第(N^2)/2-x位。然后我们对第k个机器的数排序,并找出第(N^2)/2-x个数,即为所求的中位数的复杂度是O(N^2)的。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第(N^2)/2个便是所求。复杂度是O(N^2*lgN^2)的。
14、最大间隙问题
给定n个实数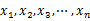 ,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
(1)找到n个数据中最大和最小数据max和min。
(2)用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为 ,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:
,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为: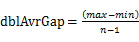 。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为
。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为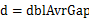 ),且认为将min放入第一个桶,将max放入第n-1个桶。
),且认为将min放入第一个桶,将max放入第n-1个桶。
(3)将n个数放入n-1个桶中:将每个元素x[i] 分配到某个桶(编号为index),其中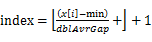 (这括号里多了个“+”),并求出分到每个桶的最大最小数据。
(这括号里多了个“+”),并求出分到每个桶的最大最小数据。
(4)最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和某个桶的下界之间隙,且该两桶之间的桶一定是空桶。也就是说,最大间隙在桶 i 的上界和桶 j 的下界之间产生j>=i+1。一遍扫描即可完成。
15、将多个集合合并成没有交集的集合
给定一个字符串的集合,格式如: 。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出
。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出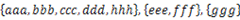 。
。
(1)请描述你解决这个问题的思路;
(2)给出主要的处理流程,算法,以及算法的复杂度;
(3)请描述可能的改进。
方案1:采用并查集。首先所有的字符串都在单独的并查集中。然后依扫描每个集合,顺序合并将两个相邻元素合并。例如,对于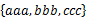 ,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
16、最大子序列与最大子矩阵问题
数组的最大子序列问题:给定一个数组,其中元素有正,也有负,找出其中一个连续子序列,使和最大。
方案1:这个问题可以动态规划的思想解决。设b[i]表示以第i个元素a[i]结尾的最大子序列,那么显然。基于这一点可以很快用代码实现。
最大子矩阵问题:给定一个矩阵(二维数组),其中数据有大有小,请找一个子矩阵,使得子矩阵的和最大,并输出这个和。
方案2:可以采用与最大子序列类似的思想来解决。如果我们确定了选择第i列和第j列之间的元素,那么在这个范围内,其实就是一个最大子序列问题。如何确定第i列和第j列可以词用暴搜的方法进行。
海量数据处理方法总结
(整理自http://duanple.blog.163.com/blog/static/7097176720091026458369/)
大数据量的问题是很多面试笔试中经常出现的问题,比如百度,Google,腾讯,阿里这样的一些涉及到海量数据的公司经常会问到。
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论。
1. Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些url ip是一一对应的,就可以转换成ip,则大大简单了。
2. Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:.海量日志数据,提取出某日访问百度次数最多的那个IP。IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
3. bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码。
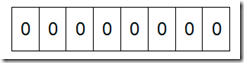
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。如果说了这么多还没明白什么是Bit-map,那么我们来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0(如下图)。
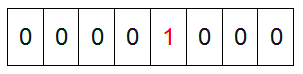
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作p+(i/8)|(0×01<<(i%8)) ,当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending)。因为是从零开始的,所以要把第五位置为一(如下图):
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
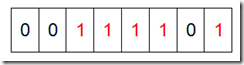
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。下面的代码给出了一个BitMap的用法:排序。
- //定义每个Byte中有8个Bit位
- #include <memory.h>
- #define BYTESIZE 8
- void SetBit(char *p, int posi)
- {
- for(int i=0; i < (posi/BYTESIZE); i++)
- {
- p++;
- }
- *p = *p|(0x01<<(posi%BYTESIZE));//将该Bit位赋值1
- return;
- }
- void BitMapSortDemo()
- {
- //为了简单起见,我们不考虑负数
- int num[] = {3,5,2,10,6,12,8,14,9};
- //BufferLen这个值是根据待排序的数据中最大值确定的
- //待排序中的最大值是14,因此只需要2个Bytes(16个Bit)
- //就可以了。
- const int BufferLen = 2;
- char *pBuffer = new char[BufferLen];
- //要将所有的Bit位置为0,否则结果不可预知。
- memset(pBuffer,0,BufferLen);
- for(int i=0;i<9;i++)
- {
- //首先将相应Bit位上置为1
- SetBit(pBuffer,num[i]);
- }
- //输出排序结果
- for(int i=0;i<BufferLen;i++)//每次处理一个字节(Byte)
- {
- for(int j=0;j<BYTESIZE;j++)//处理该字节中的每个Bit位
- {
- //判断该位上是否是1,进行输出,这里的判断比较笨。
- //首先得到该第j位的掩码(0x01<<j),将内存区中的
- //位和此掩码作与操作。最后判断掩码是否和处理后的
- //结果相同
- if((*pBuffer&(0x01<<j)) == (0x01<<j))
- {
- printf("%d ",i*BYTESIZE + j);
- }
- }
- pBuffer++;
- }
- }
- int _tmain(int argc, _TCHAR* argv[])
- {
- BitMapSortDemo();
- return 0;
- }
bloom filter可以看做是对bit-map的扩展
问题实例:
1) 已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位数最大是99 999 999,大概需要99m个bit,大概10几m字节的内存即可。(可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)。
2) 2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
4. 堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1) 100w个数中找最大的前100个数。用一个100个元素大小的最小堆即可。
5. 双层桶划分
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。双层桶划分其实本质上就是【分而治之】的思想,重在“分”的技巧上!
扩展:
问题实例:
1). 2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2). 5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
6. 数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据库的设计实现方法,对海量数据的增删改查进行处理。
扩展:
问题实例:
7. 倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what", "is" 和 "it" 将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
8. 外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择 败者树原理,最优归并树
扩展:
问题实例:
1). 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
9. trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1). 有10个文件,每个文件1G, 每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序 。
2). 1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3). 寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
10. 分布式处理mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1). The canonical example application of MapReduce is a process to count the appearances of each different word in a set of documents:
- void map(String name, String document):
- // name: document name
- // document: document contents
- for each word w in document:
- EmitIntermediate(w, 1);
- void reduce(String word, Iterator partialCounts):
- // key: a word
- // values: a list of aggregated partial counts
- int result = 0;
- for each v in partialCounts:
- result += ParseInt(v);
- Emit(result);
2). 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3). 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以放入内存,我们可以为数据建立字典,比如通过 map,hashmap,trie,然后直接进行统计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多的前N个数据,当然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程,首先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最好可以让数据划分后可以一次读入内存,这样不同的机子负责处理各种的数值范围,实际上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是reduce过程。
实际上如果直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。因为一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我们将1000万的数据分布到10台机器上,找到每台出现次数最多的前 100个,归并之后这样不能保证找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了10台机子,这样在每台上只有1千个,假设这些机子排名在1000个之前的那些都是单独分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们让每台机子选出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash后的值将它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
而外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归并过程。
另外还可以考虑近似计算,也就是我们可以通过结合自然语言属性,只将那些真正实际中出现最多的那些词作为一个字典,使得这个规模可以放入内存。
面试时算法题的解答思路
(整理自http://www.cnblogs.com/winter-cn/archive/2011/03/01/1960267.html)
面试中纯粹考算法的问题一般是让很多程序员朋友痛恨的,这里分享下我对于解答算法题的一些思路和技巧。
一般关于算法的文章,都是从经典算法讲起,一种一种算法介绍,见得算法多了,自然就有了感悟,但如此学习花费的时间和精力却是过于巨大,也不适合在博客里面交流。这一篇文,却是专门讲快捷思路的,很多人面对算法题的时候几乎是脑子里一片空白,这一篇文章讲的就是从题目下手,把毫无思路的题目打开一个缺口的几种常见技巧。
1、由简至繁
事实上,很多问题确实是很难在第一时间内得到正确的思路的,这时候可以尝试一种由简至繁的思路。首先把问题规模缩小到非常容易解答的地步。
[题目]:有足够量的2分、5分、1分硬币,请问凑齐1元钱有多少种方法?
此题乍看上去,只会觉得完全无法入手,但是按照由简至繁的思路,我们可以先考虑极端简单的情况,假如把问题规模缩小成:有足够量的1分硬币,请问凑齐1分钱有多少种方法?毫无疑问,答案是1。
得到这一答案之后,我们可以略微扩大问题的规模: 有足够量的1分硬币,凑齐2分钱有多少种方法?凑齐n分钱有多少种方法?答案仍然是1。
接下来,我们可以从另一个角度来扩大问题,有足够量的1分硬币和2分硬币,凑齐n分钱有多少种方法?这时我们手里已经有了有足够量的1分硬币,凑齐任意多钱都只有1种方法,那么只用1分钱凑齐n-2分钱,有1种方法,只用1分钱凑齐n-4分钱,有1种方法,只用1分钱凑齐n-6分钱,有1种方法......
而凑齐这些n-2、n-4、n-6这些钱数,各自补上2分钱,会产生一种新的凑齐n分钱的方法,这些方法的总数+1,就是用1分硬币和2分硬币,凑齐n分钱的方法数了。
在面试时,立刻采用这种思路是一种非常有益的尝试,解决小规模问题可以让你更加熟悉问题,并且慢慢发现问题的特性,最重要的是给你的面试官正面的信号——立即动手分析问题比皱眉冥思苦想看起来好得多。
对于此题而言,我们可以很快发现问题的规模有两个维度:用a1-ak种硬币和凑齐n分钱,所以我们可以记做P(k,n)。当我们发现递归公式 P(k,n) = P(k-1,n - ak) + P(k-1,n - 2*ak) + P(k-1,n - 3*ak) ... ... 时,这个问题已经是迎刃而解了。
通常由简至繁的思路,用来解决动态规划问题是非常有效的,当积累了一定量简单问题的解的时候,往往通向更高一层问题的答案已经摆在眼前了。
2、一分为二(分治然后递归)
另一种思路,就是把问题一刀斩下,把问题分为两半,变成两个与原来问题同构的问题,能把问题一分为2,就能再一分为4,就能再一分为8,直到分成我们容易解决的问题。当尝试这种思路时,其实只需要考虑两个问题:1.一分为二以后,问题是否被简化了? 2.根据一分为二的两个问题的解,能否方便地得出整个问题的解?
[题目]:将一个数组排序。
这个经典算法肯定所有人都熟悉的不能再熟悉了,不过若是从头开始思考这个问题,倒也不是所有人都能想出几种经典的排序算法之一的,这里仅仅是用来做例子说明一分为二的思路的应用。
最简单的一分为二,就是将数组分成两半,分别排序。对于两个有序数组,我们有办法将它合并成一个有序数组,所以这个一分为二的思路是可行的,同样对于已经分成两半的数组,我们还可以将这个数组分作两半,直到我们分好的数组仅有1个元素,1个元素的数组天然就是有序的。不难看出,按这种思路我们得出的是经典数组排序算法中的“归并排序”。
还有另一种一分为二的思路,考虑到自然将数组分成两半合并起来比较复杂,我们可以考虑将数组按照大于和小于某个元素分成两半,这样只要分别解决就可以直接连接成一个有序数组了,同样这个问题也是能够再次一分为二。按照这个思路,则可以得出经典数组排序算法中的“快速排序”。
3、化虚为实
这种思路针对的是浮点数有关的特殊问题,因为无论是穷举还是二分,对于浮点数相关的计算问题(尤其是计算几何)都难以启效,所以化虚为实,指的是把有点"虚"的浮点数,用整数来替代。具体做法是,把题目中给出的一些浮点数(不限于浮点数,我们不关心其具体大小的整数也可以)排序,然后用浮点数的序号代替本身来思考问题,等到具体计算时再替换回来。
[题目]:已知n个边水平竖直的矩形(用四元组 [x1, y1, x2, y2] 表示),求它们的总共覆盖面积。
因为坐标可能出现浮点数,所以此题看起来十分繁复(可以实践上面由简至繁和一分为二的思路都基本无效),略一思考,矩形的覆盖关系其实只跟矩形坐标的大小有关,所以我们尝试思考将矩形的所有x值排序,然后用序号代替具体竖直,y值亦然,于是我们得到所有矩形其实处于一个2nx2n的区块当中,这样我们用最简单的穷举办法,可以计算出每一个1x1的格子是否被覆盖住了。至此,只要我们计算面积的时候,把格子的真实长宽换算回来,就已经得到题目的答案了。
- 海量数据处理面试题整理
- 海量数据处理面试题整理
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 面试题:海量数据处理
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 海量数据处理面试题
- 面试题------海量数据处理
- 海量数据处理 面试题
- android ksoap2调用webservice
- Hibernate和IBatis对比(优缺点)
- [LeetCode] Balanced Binary Tree
- Core Animation动画技术
- rhel7中vsftp服务的三种认证登陆方式
- 海量数据处理面试题整理
- PhoneGap—双击返回按钮程序退出—Navigator—.mobile理解
- [Apache POI] 操作Excel
- Nova镜像使用方法
- C语言实训学完之后
- Java编程中“为了性能”需做的26件事
- 窗前好风光 家具布局让你宅家晒太阳
- VB6中Round(1.245,2)居然不是等于1.24,你造吗?
- BZOJ 1857: [Scoi2010]传送带


