bag of words model 应用于图像
来源:互联网 发布:网络星河 pdf 编辑:程序博客网 时间:2024/05/16 13:07
本文记录bag of words(BOW)在图像中的应用相关思路。
1. 简介
bag of words是文档的一种建模方法,它可以把一个文档表示成向量数据,从而使计算机处理文档数据更加方便。
wiki的例子很清晰的描述了BOW对一个文档建模的过程。
http://en.wikipedia.org/wiki/Bag-of-words_model
现有如下两个文档:
John likes to watch movies. Mary likes movies too.
John also likes to watch football games.
把文档中的单词抽取出来,可以构成一个单词表:
{ "John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10}这个单词表中有10个不同的词,根据单词表中每个词的索引号,可以把两个文档表示成如下的两个含有10个元素的向量:
[1, 2, 1, 1, 2, 0, 0, 0, 1, 1][1, 1, 1, 1, 0, 1, 1, 1, 0, 0]其中,元素值代表其索引号在单词表中对应的词在文档中出现的次数。比如第一个文档对应的向量,前两个元素值为1和2,1代表“John”在该文档中的出现1次,2代表“likes”在该文档中出现2次。
这样的建模,只提取了单词,忽略了语法和语序,等于把单词一个一个放进一个袋子里,所以是词袋模型。
2, BOW在图像中的应用
此部分描述参考文章:http://blog.sina.com.cn/s/blog_65f81ec601012sd5.html
要应用到图像中,我们要把一幅图看成一个文档,图片分割成的patch对应的sift特征看成单词。所以首先要做的是单词表的构造。
用人脸,自行车,和吉他,三张图片举例。
主要有以下3步:
1)把图像分割成一个个patch,并对每个patch的中心点计算sift特征。sift算法可以提取图像中的局部不变特征,这一步是做dense sift.

2)利用kmeans算法,将这些patch的中心点的sift特征聚成为k个类,用这k个聚类中心来构造单词表。因为一幅图像中能提取出成千上万个sift向量,而每个sift向量是128维的,为了减小计算量,需要对这些sift向量做聚类,把相似的patch合并,取聚类中心作代表,构造单词表。

以上的众多patch中可以看到有一些是相似的,设定k=4,则聚类后的单词表如下:

3)利用单词表表示每幅图像,则每幅图像被表示成了一个与词序列相对应的词频向量(k维的)。
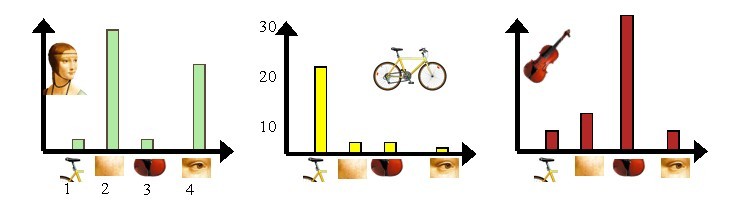
人脸图:[3,30,3,20] 自行车图:[20,3,3,2] 吉他图:[8,12,32,7]
其他参考资料:
http://en.wikipedia.org/wiki/Bag-of-words_model_in_computer_vision
http://www.douban.com/note/310140053/
http://blog.csdn.net/pupu_2009/article/details/6427222
- bag of words model 应用于图像
- bag of words model 应用于图像
- Bag-of-words model
- Bag-of-words model
- Bag-of-words model
- Bag-of-words model
- Bag-of-words model
- Bag of words model (词袋模型)
- Bag-of-words model in computer vision
- Bag-of-words model in computer vision
- Bag-of-words model in computer vision
- bag-of-words model的java实现
- Bag-of-words model (BoW模型)
- Bag-of-words model in computer vision
- 基于BOW模型的图像分类Bag Of Visual Words model for image classification
- 图像检索:Bag-of-words模型简介
- 图像特征提取方法:Bag-of-words
- 图像检索:Bag-of-words模型简介
- HDOJ-1847畅通工程续(Floyd)
- 《算法导论》7、堆排序实现(C++)
- xp系统扩展虚拟内存的方法
- php文件开发时显示报错信息
- 设计模式之适配器模式
- bag of words model 应用于图像
- 反转链表(递归实现)
- Oracle Exadata一体机与云计算应用(三)
- CSS 圣杯布局和双飞翼布局
- iOS:Error Domain=WebKitErrorDomain Code=101 "The operation couldn’t be completed. (WebKitErrorDomain
- 配置 Transact-SQL 调试器
- UVA 11178-Morley's Theorem(计算几何_莫雷定理)
- C++缺省参数的函数
- Android 开发 pull解析器解析xml文件


