浅谈php-Memcached常规应用与分布式部署方案-
来源:互联网 发布:5个数相加等于100算法 编辑:程序博客网 时间:2024/05/21 06:37
1、Memcached常规应用
使用Memcached缓存MySQL查询结果减轻数据库压力,下面直接上代码,后面做简单说明。
说明:首先通过md5()将SQL语句转化成一个唯一的KEY,并用此KEY查询Memcached检测是否已经缓存,是的话在直接返回结果,否则先查询数据库再缓存,并返回结果。这样,下次使用此KEY就可以直接返回结果了。另外值得一提的是,看代码中SQL语句的组合部分,用到了sprintf()函数,简单高效,来自白菜指南推荐。
2、Memcached分布式部署方案
通常较小的应用一台Memcached服务器就可以满足需求,但是大中型项目可能就需要多台Memcached服务器了,这就牵涉到一个分布式部署的问题。
对于多台Memcached服务器,怎么确定一个数据应该保存到哪台服务器呢?有两种方案,一是普通Hash分布,二是一致性Hash分布。下面详细说明。
[1]Memcached分布式部署之普通Hash分布
普通Hash分布对于Memcached服务器数量固定的情况推荐使用,比较简单,但是可想而知扩展性不好。
说明:首先通过MD5函数把KEY处理成32位字符串,然后截取前8位,再经过Hash算法处理成一个整数并返回。利用这个整数与Memcached服务器数量取模,决定当前KEY存储于哪台Memcached服务器,就完成了Memcached的分布式部署。可想而知,当要读取KEY的值时,依然是先要通过Hash算法判断存储于哪台服务器。这种方案整体来说比较简单容易理解。
[2]Memcached分布式部署之一致性Hash分布
当Memcached服务器数量固定时,普通Hash分布可以很好的运作。但是当服务器数量发生改变时,问题就出来了。因为同一个KEY经Hash算法处理后,与服务器数量取模,会导致结果与服务器数量未变化时不同,这就导致之前保存的数据丢失。采取一致性Hash分布可以有效的解决这个问题,把丢失的数据减到最小(注意这里并没有说完全不丢失)。
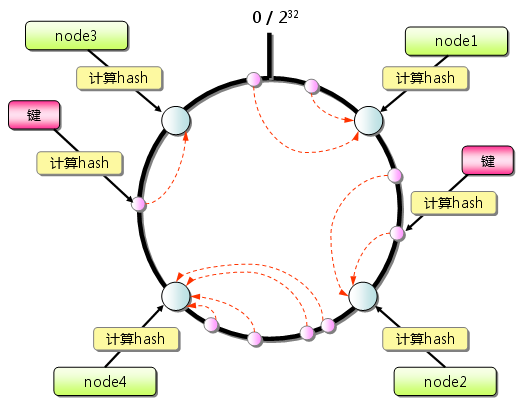
一致性Hash分布算法分4个步骤:
步骤1:将一个32位整数[0 ~ (2^32-1)]想象成一个环,0 作为开头,(2^32-1) 作为结尾,当然这只是想象。
步骤2:通过Hash函数把KEY处理成整数。这样就可以在环上找到一个位置与之对应。
步骤3:把Memcached服务器群映射到环上,使用Hash函数处理服务器对应的IP地址即可。
步骤4:把数据映射到Memcached服务器上。查找一个KEY对应的Memcached服务器位置的方法如下:从当前KEY的位置,沿着圆环顺时针方向出发,查找位置离得最近的一台Memcached服务器,并将KEY对应的数据保存在此服务器上。
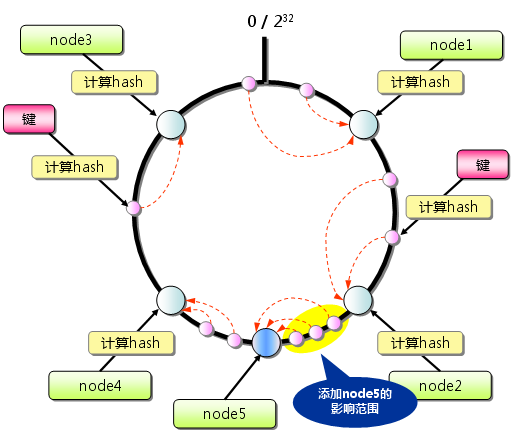
说明:这样一来,当添加或移除某一台服务器时,受影响的数据范围变的更小了。具体可以画个图更便于理解,这里我就不画了。
[3]一致性Hash分布算法实例
说明:其整体查找思路,已经在前面的一致性Hash分布部分进行了介绍,需要补充的是每次添加或移除服务器后需要对服务器列表这个序列就行一次排序。
下面是对上面的一致性Hash分布实例的相关测试代码:
- 浅谈php-Memcached常规应用与分布式部署方案-
- Memcached常规应用与分布式部署方案
- 分布式缓存redis方案与memcached方案的选择
- memcached分布式布置方案
- Memcached分布式布置方案
- memcached分布式部署
- memcached分布式部署
- Memcached分布式部署方案设计
- memcached分布式部署
- Memcached分布式部署方案设计(含PHP代码)
- 浅谈CAS在分布式ID生成方案上的应用
- 浅谈CAS在分布式ID生成方案上的应用
- 浅谈CAS在分布式ID生成方案上的应用
- Memcache分布式部署方案
- Memcache分布式部署方案
- Memcache分布式部署方案
- Memcache分布式部署方案
- Memcache分布式部署方案
- CvMat,Mat和IplImage之间的转化和拷贝
- hadoop中map和reduce的数量设置问题
- leetcode_Valid Parentheses
- easyui 创建datagrid
- Netty通信
- 浅谈php-Memcached常规应用与分布式部署方案-
- Remove Duplicates from Sorted List
- iOS开发 - 封装文件上传工具类
- hsql语言
- zend studio 的插件之一 Emmet
- 陈怡暖:2015.5.21早间最强现货黄金白银操作建议
- HBase 系统架构
- MyEclipse 设置快速复制一行
- C++学习 boost::apply_visitor说明


