Docker
来源:互联网 发布:禾赛科技李一帆 知乎 编辑:程序博客网 时间:2024/05/13 03:29
Docker 是容器管理工具
Docker 是一个轻量级、便携式、与外界隔离的容器,也是一个可以在容器中很方便地构建、传输、运行应用的引擎。和传统的虚拟化技术不同的是,Docker 引擎并不虚拟出一台虚拟机,而是直接使用宿主机的内核和硬件,直接在宿主机上运行容器内应用。也正是得益于此,Docker 容器内运行的应用和宿主机上运行的应用性能差距几乎可以忽略不计。
但是 Docker 本身并不是一个容器系统,而是一个基于原有的容器化工具 LXC用来创建虚拟环境的工具。类似 LXC 的工具已经在生产环境中使用多年,Docker 则基于此提供了更加友好的镜像管理工具和部署工具。
Docker 不是虚拟化引擎
Docker 第一次发布的时候,很多人都拿 Docker 和虚拟机 VMware、KVM 和 VirtualBox 比较。尽管从功能上看,Docker 和虚拟化技术致力于解决的问题都差不多,但是 Docker 却是采取了另一种非常不同的方式。虚拟机是虚拟出一套硬件,虚拟机的系统进行的磁盘操作,其实都是在对虚拟出来的磁盘进行操作。当运行 CPU 密集型的任务时,是虚拟机把虚拟系统里的 CPU 指令“翻译”成宿主机的CPU指令并进行执行。两个磁盘层,两个处理器调度器,两个操作系统消耗的内存,所有虚拟出的这些都会带来相当多的性能损失,一台虚拟机所消耗的硬件资源和对应的硬件相当,一台主机上跑太多的虚拟机之后就会过载。而 Docker 就没有这种顾虑。Docker 运行应用采取的是“容器”的解决方案:使用 namespace 和 CGroup 进行资源限制,和宿主机共享内核,不虚拟磁盘,所有的容器磁盘操作其实都是对 /var/lib/docker/ 的操作。简言之,Docker 其实只是在宿主机中运行了一个受到限制的应用程序。
从上面不难看出,容器和虚拟机的概念并不相同,容器也并不能取代虚拟机。在容器力所不能及的地方,虚拟机可以大显身手。例如:宿主机是 Linux,只能通过虚拟机运行 Windows,Docker 便无法做到。再例如,宿主机是 Windows,Windows 并不能直接运行 Docker,Windows上的 Docker 其实是运行在 VirtualBox 虚拟机里的。
Docker 使用层级的文件系统
前面提到过,Docker 和现有容器技术 LXC 等相比,优势之一就是 Docker 提供了镜像管理。对于 Docker 而言,镜像是一个静态的、只读的容器文件系统的快照。然而不仅如此,Docker 中所有的磁盘操作都是对特定的Copy-On-Write文件系统进行的。下面通过一个例子解释一下这个问题。
例如我们要建立一个容器运行 JAVA Web 应用,那么我们应该使用一个已经安装了 JAVA 的镜像。在 Dockerfile(一个用于生成镜像的指令文件)中,应该指明“基于 JAVA 镜像”,这样 Docker 就会去 Docker Hub Registry 上下载提前构建好的 JAVA 镜像。然后在Dockerfile 中指明下载并解压 Apache Tomcat 软件到 /opt/tomcat 文件夹中。这条命令并不会对原有的 JAVA 镜像产生任何影响,而仅仅是在原有镜像上面添加了一个改动层。当一个容器启动时,容器内的所有改动层都会启动,容器会从第一层中运行 /usr/bin/java 命令,并且调用另外一层中的 /opt/tomcat/bin 命令。实际上,Dockerfile 中每一条指令都会产生一个新的改动层,即便只有一个文件被改动。如果用过 Git 就能更清楚地认识这一点,每条指令就像是每次 commit,都会留下记录。但是对于 Docker 来说,这种文件系统提供了更大的灵活性,也可以更方便地管理应用程序。
我们Spantree的团队有一个自己维护的含有 Tomcat 的镜像。发布新版本也非常简单:使用 Dockerfile 将新版本拷贝进镜像从而创建一个新镜像,然后给新镜像贴上版本的标签。不同版本的镜像的不同之处仅仅是一个 90 MB 大小的 WAR 文件,他们所基于的主镜像都是相同的。如果使用虚拟机去维护这些不同的版本的话,还要消耗掉很多不同的磁盘去存储相同的系统,而使用 Docker 就只需要很小的磁盘空间。即便我们同时运行这个镜像的很多实例,我们也只需要一个基础的 JAVA / TOMCAT 镜像。
Docker 可以节约时间
很多年前我在为一个连锁餐厅开发软件时,仅仅是为了描述如何搭建环境都需要写一个 12 页的 Word 文档。例如本地 Oracle 数据库,特定版本的 JAVA,以及其他七七八八的系统工具和共享库、软件包。整个搭建过程浪费掉了我们团队每个人几乎一天的时间,如果用金钱衡量的话,花掉了我们上万美金的时间成本。虽然客户已经对这种事情习以为常,甚至认为这是引入新成员、让成员适应环境、让自己的员工适应我们的软件所必须的成本,但是相比较起来,我们宁愿把更多的时间花在为客户构建可以增进业务的功能上面。
如果当时有 Docker,那么构建环境就会像使用自动化搭建工具 Puppet / Chef / Salt / Ansible 一样简单,我们也可以把整个搭建时间周期从一天缩短为几分钟。但是和这些工具不同的地方在于,Docker 可以不仅仅可以搭建整个环境,还可以将整个环境保存成磁盘文件,然后复制到别的地方。需要从源码编译 Node.js 吗?Docker 做得到。Docker 不仅仅可以构建一个 Node.js 环境,还可以将整个环境做成镜像,然后保存到任何地方。当然,由于 Docker 是一个容器,所以不用担心容器内执行的东西会对宿主机产生任何的影响。
现在新加入我们团队的人只需要运行 docker-compose up 命令,便可以喝杯咖啡,然后开始工作了。
Docker 可以节省开销
当然,时间就是金钱。除了时间外,Docker 还可以节省在基础设施硬件上的开销。高德纳和麦肯锡的研究表明,数据中心的利用率在 6% - 12% 左右。不仅如此,如果采用虚拟机的话,你还需要被动地监控和设置每台虚拟机的 CPU 硬盘和内存的使用率,因为采用了静态分区(static partitioning)所以资源并不能完全被利用。。而容器可以解决这个问题:容器可以在实例之间进行内存和磁盘共享。你可以在同一台主机上运行多个服务、可以不用去限制容器所消耗的资源、可以去限制资源、可以在不需要的时候停止容器,也不用担心启动已经停止的程序时会带来过多的资源消耗。凌晨三点的时候只有很少的人会去访问你的网站,同时你需要比较多的资源执行夜间的批处理任务,那么可以很简单的便实现资源的交换。
虚拟机所消耗的内存、硬盘、CPU 都是固定的,一般动态调整都需要重启虚拟机。而用 Docker 的话,你可以进行资源限制,得益于 CGroup,可以很方便动态调整资源限制,让然也可以不进行资源限制。Docker 容器内的应用对宿主机而言只是两个隔离的应用程序,并不是两个虚拟机,所以宿主机也可以自行去分配资源。
Docker 有一个健壮的镜像托管系统
前面提到过,这个托管系统就叫做 Docker Hub Registry。截止到 2015年4月29日,互联网上大约有 14000 个公共的 Docker,而大部分都被托管在 Docker Hub 上面。和 Github 已经很大程度上成为开源项目的代表一样,Docker 官方的 Docker Hub 则已经是公共 Docker 镜像的代表。这些镜像可以作为你应用和数据服务的基础。
也正是得益于此,你可以随意尝试最新的技术:说不定有些人就把图形化数据库的实例打包成了 Docker 镜像托管在上面。再例如 Gitlab,手工搭建 Gitlab 非常困难,译者不建议普通用户去手工搭建,而如果使用 Docker Gitlab,这个镜像则会五秒内便搭建完成。再例如特定 Ruby 版本的 Rails 应用,再例如 Linux 上的 .NET 应用,这些都可以使用简单的一条 Docker 命令搭建完成。
Docker 官方镜像都有 official 标签,安全性可以保证。但是第三方镜像的安全性无法保证,所以请谨慎下载第三方镜像。生产环境下可以只使用第三方提供的 Dockerfile 构建镜像。
Docker Github 介绍:5 秒内搞定一个 Gitlab
关于 Linux 上的 .NET 应用和 Rails 应用,将会在以后的文章中做详细介绍。
Docker 可以避免产生 Bug
Spantree 一直是“固定基础设置”(immutable infrastructure)的狂热爱好者。换句话说,除非有心脏出血这种漏洞,我们尽量不对系统做升级,也尽量不去改变系统的设置。当添加新服务器的时候,我们也会从头构建服务器的系统,然后直接将镜像导入,将服务器放入负载均衡的集群里,然后对要退休的服务器进行健康检查,检查完毕后移除集群。得益于 Docker 镜像可以很轻松的导入导出,我们可以最大程度地减少因为环境和版本问题导致的不兼容,即便有不兼容了也可以很轻松地回滚。当然,有了 Docker,我们在生产、测试和开发中的运行环境得到统一。以前在协同开发时,会因为每个人开发的电脑配置不同而导致“在我的电脑上是能运行的,你的怎么不行”的情况,而如今 Docker 已经帮我们解决了这个问题。
Docker 目前只能运行在 Linux 上
前面也提到过,Docker 使用的是经过长时间生产环境检验的技术,虽然这些技术已经都出现很长时间了,但是大部分技术都还是 Linux 独有的,例如 LXC 和 Cgroup。也就是说,截止到现在,Docker 容器内只能在 Linux 上运行 Linux 上的服务和应用。Microsoft 正在和 Docker 紧密合作,并且已经宣布了下一个版本的 Windows Server 将会支持 Docker 容器,并且命名为 Windows Docker,估计采用的技术应该是Hyper-V Container,我们有望在未来的几年内看到这个版本。
除此之外,类似 boot2docker 和 Docker Machine 这种工具已经可以让我们在 Mac 和 Windows 下通过虚拟机运行 Docker 了。
Docker和LXC有什么不同
Docker不是LXC的一个替代方案。『LXC』是指Linux内核(尤指Namespace以及Cgroup)的一个特性,它允许一些sandbox进程运行在一块相对独立的空间,并且能够方便的控制他们的资源调度。

- 可移植的跨机器部署。Docker定义了一个将应用打包的规范,而它的所有依赖都被封装到了一个简单对象里,它可以被传输到任意一台能运行Docker的机器,并且在这里启动Docker的实例之后,它能够确保承载应用的执行环境将会与之前所定义的完全一致。Lxc实现了进程级的沙盒封装,它是可移植部署的一个重要前提,但是要想实现可移植部署,仅仅是这样可还不够。如果你发送给我一份安装到一个自定义LXC配置下的应用副本,那么几乎可以肯定的是,它在我的机器上运行的结果不会跟你的完全一样,因为它绑定了你机器的一些特殊配置:网络、存储、日志、Linux发行版本等等。Docker为这些机器的特定配置定义了一个抽象层,所以它使得这些相同的Docker容器能够一成不变的运行在多个不同的主机上,甚至带上各种不同的配置。
- 以应用为中心。相对于机器而言,Docker被用于优化应用的部署过程。这可以从它的API、UI、设计理念还有文档里得到体现。反之,lxc的辅助脚本专注在把容器作为一个轻量级的
机器使用 —— 基本上就是一堆启动更快并且内存需求更小的服务器。我们认为容器技术的内容远远不止这些。 - 自动构建。Docker为开发人员引入了一个可以用来把他们的源代码自动打包到容器里的工具,并且他们能够对于应用的依赖,构建工具,打包服务等有着完全的自主掌控能力。他们能够自由的使用make、Maven、Chef、Puppet、salt、debian包、RPM包,源码包,或者任意以上的结合,而无需关心机器本身的配置。
- 版本化。Docker引入了一个类似git的特性来完成一个容器的连续版本追踪,版本之间的差异diff,新的版本的提交,回滚等。历史记录信息里也包含了容器的用户信息以及他是如何构建它的,因此生产环境的服务器你都有充足的手段去一步步的定位到最上游的开发人员。Docker也实现了一个增量上传和下载功能,类似于git pull,所以更换到新版本的容器只需要传输增量部分就行。
- 组件的重用。任意容器都能用作“基础镜像”来创建更特定的组件。这可以手工完成也可以做成自动构建的一部分。例如,你可以准备一个理想的Python环境,并且把它用作10个不同的应用的基础镜像。你所定义的标准PostgreSQL设置可以被将来你手上的所有项目重用。诸如此类。
- 共享。Docker 有权访问一个公共的registry而这里有数以千计的业界人士上传各种各样有价值的容器:任一从Redis、Couchdb、Postgres到irc bouncers再到Rails应用服务器,Hadoop甚至是多个发行版本的基础镜像。该registry也包含了一个官方的“标准库”,这里提供了一些由Docker官方团队维护的实用容器。registry本身也是开源的,所以任何人都能部署他们自己的私有注册中心来存储和下发私有容器,例如用于内网服务器的部署。
- 工具生态圈。Docker定义了一个API来自动化和个性化的创建和部署容器。也因此催生了众多的工具集成到Docker,为之提供一些扩展特性。类PaaS的部署(Dokku、Deis、Flynn),多节点编排(Maestro、Salt、Mesos、OpenStack Nova),管理看板(Docker-UI、OpenStack Horizon、Shipyard),配置管理(Chef、Puppet),持续集成(Jenkins、Strider、Travis)等等。Docker正在迅速的建立以它本身为标准的基于容器的工具生态圈。
Docker 与vagrant在团队开发中的比较
Docker 与vagrant在团队开发中的比较
在之前的一篇博客vagrant中提到了用vagrant来统一开发团队的开发环境。用vagrant基本上解决了开发环境异构的问题,但VM(vagrant使用virtual box)footprint很大,不便于频繁更新,启动销毁速度还很慢。所以,对并行开发的场景,尤其是快速迭代的开发周期,支持起来还是很别扭:
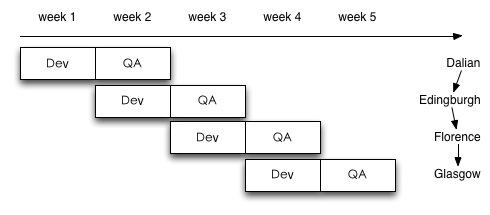
以图中week 3第一天为例:Dalian已经部署到线上,Edingburgh交付测试,而Florence正在开发中。此刻Dalian随时会爆出优先级很高的customer issue;Edingburgh可能会有大量的QA issue等待修复;而Florence上的任务还如火如荼。
这意味着每周要生成至少一个公共VM,对应当前版本的代码和样本数据。如有需要(比如Dalian同时爆出几个bug,需要多人同时跟进调试),相关的工程师每人还需要一个自己的私有VM。
对于devops,这是管理的梦魇。
还好,docker出现了。我们看看docker有什么本领:
- 使用Linux container,使得"VM"的创建和销毁在秒级就能完成。由于只是做了网络和进程的隔离,"VM"的运行几乎没有overhead。
- 使用AUFS,可以以递进的方式创建"VM" —— 一个"VM"叠在另一个"VM"上,就像使用git增量开发一样。
- 软件的运行环境(image)和软件本身(container)分离,和数据也分离。
头两点让docker在系统中的footprint很小,使用或者不使用docker对应用程序来说几乎没有差别。最后一点是最关键的,它让你能灵活地基于某个现存的image,和最新的软件版本,最新的线上样本数据一起,构建一个container。vagrant无法做到这一点。一旦你创建了一个VM,你的环境,应用程序和数据都被绑定到一起了,同一个环境,不同的应用程序版本(或数据),需要创建不同的VM。
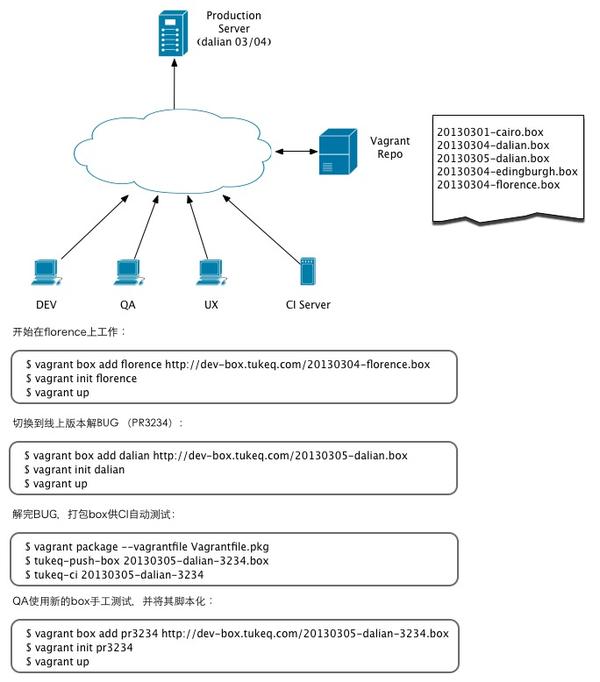
这是我之前构想的用vagrant构建的开发环境的一个例子:
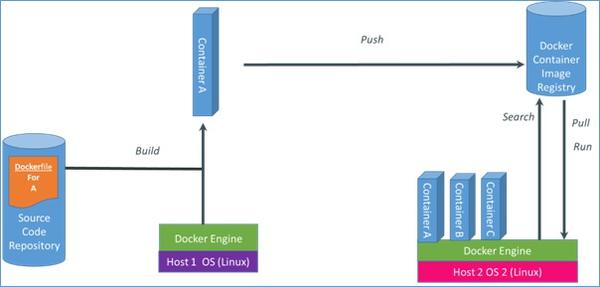
如果使用docker,则简单很多。多数时候我们可以使用相同的image,配以不同的运行时软件和数据,如下图所示:
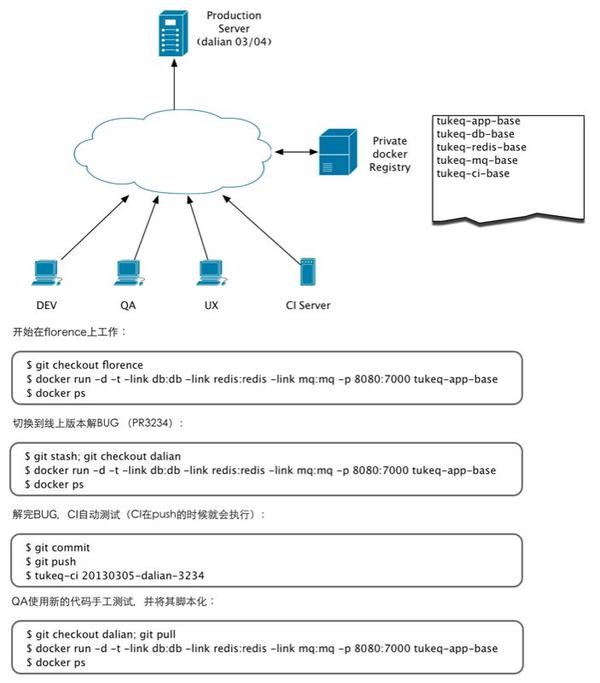
对应上面vagrant的开发环境,docker的开发环境可以是这样子的:
Docker 基础技术:Linux Namespace
简介
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。不知道你是否还记得很早以前的Unix有一个叫chroot的系统调用(通过修改根目录把用户jail到一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。
举个例子,我们都知道,Linux下的超级父亲进程的PID是1,所以,同chroot一样,如果我们可以把用户的进程空间jail到某个进程分支下,并像chroot那样让其下面的进程 看到的那个超级父进程的PID为1,于是就可以达到资源隔离的效果了(不同的PID namespace中的进程无法看到彼此)
šLinux Namespace 有如下种类,官方文档在这里《Namespace in Operation》
主要是š三个系统调用
- šclone() - 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。
- šunshare() - 使某进程脱离某个namespace
- šsetns() - 把某进程加入到某个namespace
unshare() 和 setns() 都比较简单,大家可以自己man,我这里不说了。
下面还是让我们来看一些示例(以下的测试程序最好在Linux 内核为3.8以上的版本中运行,我用的是ubuntu 14.04)。
clone()系统调用
首先,我们来看一下一个最简单的clone()系统调用的示例,(后面,我们的程序都会基于这个程序做修改):
#define _GNU_SOURCE#include <sys/types.h>#include <sys/wait.h>#include <stdio.h>#include <sched.h>#include <signal.h>#include <unistd.h>/* 定义一个给 clone 用的栈,栈大小1M */#define STACK_SIZE (1024 * 1024)staticchar container_stack[STACK_SIZE];char*const container_args[] = { "/bin/bash", NULL};intcontainer_main(void* arg){ printf("Container - inside the container!\n"); /* 直接执行一个shell,以便我们观察这个进程空间里的资源是否被隔离了 */ execv(container_args[0], container_args); printf("Something's wrong!\n"); return1;}intmain(){ printf("Parent - start a container!\n"); /* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */ intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, SIGCHLD, NULL); /* 等待子进程结束 */ waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}从上面的程序,我们可以看到,这和pthread基本上是一样的玩法。但是,对于上面的程序,父子进程的进程空间是没有什么差别的,父进程能访问到的子进程也能。
下面, 让我们来看几个例子看看,Linux的Namespace是什么样的。
UTS Namespace
下面的代码,我略去了上面那些头文件和数据结构的定义,只有最重要的部分。
intcontainer_main(void* arg){ printf("Container - inside the container!\n"); sethostname("container",10);/* 设置hostname */ execv(container_args[0], container_args); printf("Something's wrong!\n"); return1;}intmain(){ printf("Parent - start a container!\n"); intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL);/*启用CLONE_NEWUTS Namespace隔离 */ waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}运行上面的程序你会发现(需要root权限),子进程的hostname变成了 container。
hchen@ubuntu:~$sudo ./utsParent - start a container!Container - inside the container!root@container:~# hostnamecontainerroot@container:~# uname -ncontainerIPC Namespace
IPC全称 Inter-Process Communication,是Unix/Linux下进程间通信的一种方式,IPC有共享内存、信号量、消息队列等方法。所以,为了隔离,我们也需要把IPC给隔离开来,这样,只有在同一个Namespace下的进程才能相互通信。如果你熟悉IPC的原理的话,你会知道,IPC需要有一个全局的ID,即然是全局的,那么就意味着我们的Namespace需要对这个ID隔离,不能让别的Namespace的进程看到。
要启动IPC隔离,我们只需要在调用clone时加上CLONE_NEWIPC参数就可以了。
intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWIPC | SIGCHLD, NULL);首先,我们先创建一个IPC的Queue(如下所示,全局的Queue ID是0)
hchen@ubuntu:~$ ipcmk -QMessage queueid: 0hchen@ubuntu:~$ ipcs -q------ Message Queues --------key msqid owner perms used-bytes messages 0xd0d56eb2 0 hchen 644 0 0如果我们运行没有CLONE_NEWIPC的程序,我们会看到,在子进程中还是能看到这个全启的IPC Queue。
hchen@ubuntu:~$sudo ./utsParent - start a container!Container - inside the container!root@container:~# ipcs -q------ Message Queues --------key msqid owner perms used-bytes messages 0xd0d56eb2 0 hchen 644 0 0但是,如果我们运行加上了CLONE_NEWIPC的程序,我们就会下面的结果:
root@ubuntu:~$ sudo./ipcParent - start a container!Container - inside the container!root@container:~/linux_namespace# ipcs -q------ Message Queues --------key msqid owner perms used-bytes messages我们可以看到IPC已经被隔离了。
PID Namespace
我们继续修改上面的程序:
intcontainer_main(void* arg){ /* 查看子进程的PID,我们可以看到其输出子进程的 pid 为 1 */ printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container",10); execv(container_args[0], container_args); printf("Something's wrong!\n"); return1;}intmain(){ printf("Parent [%5d] - start a container!\n", getpid()); /*启用PID namespace - CLONE_NEWPID*/ intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | SIGCHLD, NULL); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}运行结果如下(我们可以看到,子进程的pid是1了):
hchen@ubuntu:~$sudo ./pidParent [ 3474] - start a container!Container [ 1] - inside the container!root@container:~# echo $$1你可能会问,PID为1有个毛用啊?我们知道,在传统的UNIX系统中,PID为1的进程是init,地位非常特殊。他作为所有进程的父进程,有很多特权(比如:屏蔽信号等),另外,其还会为检查所有进程的状态,我们知道,如果某个子进程脱离了父进程(父进程没有wait它),那么init就会负责回收资源并结束这个子进程。所以,要做到进程空间的隔离,首先要创建出PID为1的进程,最好就像chroot那样,把子进程的PID在容器内变成1。
但是,我们会发现,在子进程的shell里输入ps,top等命令,我们还是可以看得到所有进程。说明并没有完全隔离。这是因为,像ps, top这些命令会去读/proc文件系统,所以,因为/proc文件系统在父进程和子进程都是一样的,所以这些命令显示的东西都是一样的。
所以,我们还需要对文件系统进行隔离。
Mount Namespace
下面的例程中,我们在启用了mount namespace并在子进程中重新mount了/proc文件系统。
intcontainer_main(void* arg){ printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container",10); /* 重新mount proc文件系统到 /proc下 */ system("mount -t proc proc /proc"); execv(container_args[0], container_args); printf("Something's wrong!\n"); return1;}intmain(){ printf("Parent [%5d] - start a container!\n", getpid()); /* 启用Mount Namespace - 增加CLONE_NEWNS参数 */ intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}运行结果如下:
hchen@ubuntu:~$sudo ./pid.mntParent [ 3502] - start a container!Container [ 1] - inside the container!root@container:~# ps -elfF S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD4 S root 1 0 0 80 0 - 6917 wait 19:55 pts/2 00:00:00 /bin/bash0 R root 14 1 0 80 0 - 5671 - 19:56 pts/2 00:00:00 ps-elf上面,我们可以看到只有两个进程 ,而且pid=1的进程是我们的/bin/bash。我们还可以看到/proc目录下也干净了很多:
root@container:~# ls /proc1 dma key-users net sysvipc16 driver kmsg pagetypeinfo timer_listacpi execdomains kpagecount partitions timer_statsasound fb kpageflags sched_debug ttybuddyinfo filesystems loadavg schedstat uptimebus fs locks scsi versioncgroups interrupts mdstat self version_signaturecmdline iomem meminfo slabinfo vmallocinfoconsoles ioports misc softirqs vmstatcpuinfo irq modules stat zoneinfocrypto kallsyms mounts swapsdevices kcore mpt sysdiskstats keys mtrr sysrq-trigger下图,我们也可以看到在子进程中的top命令只看得到两个进程了。
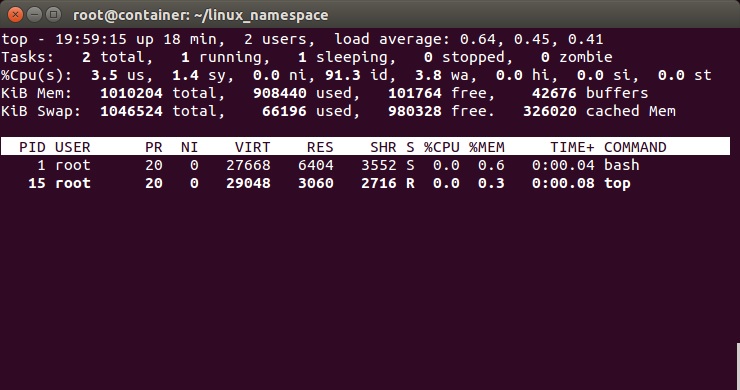
这里,多说一下。在通过CLONE_NEWNS创建mount namespace后,父进程会把自己的文件结构复制给子进程中。而子进程中新的namespace中的所有mount操作都只影响自身的文件系统,而不对外界产生任何影响。这样可以做到比较严格地隔离。
你可能会问,我们是不是还有别的一些文件系统也需要这样mount? 是的。
Docker的 Mount Namespace
下面我将向演示一个“山寨镜像”,其模仿了Docker的Mount Namespace。
首先,我们需要一个rootfs,也就是我们需要把我们要做的镜像中的那些命令什么的copy到一个rootfs的目录下,我们模仿Linux构建如下的目录:
hchen@ubuntu:~/rootfs$lsbin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var然后,我们把一些我们需要的命令copy到 rootfs/bin目录中(sh命令必需要copy进去,不然我们无法 chroot )
hchen@ubuntu:~/rootfs$ls ./bin ./usr/bin ./bin:bash chown gzip less mount netstat rm tabs tee top ttycat cp hostname ln mountpoint ping sed tac test touch umountchgrp echo ip ls mv ps sh tail timeout tr unamechmod grep kill more nc pwd sleep tar toe truncate which./usr/bin:awk env groups head id mesg sort strace tail top uniq vi wc xargs注:你可以使用ldd命令把这些命令相关的那些so文件copy到对应的目录:
hchen@ubuntu:~/rootfs/bin$ lddbash linux-vdso.so.1 => (0x00007fffd33fc000) libtinfo.so.5 =>/lib/x86_64-linux-gnu/libtinfo.so.5 (0x00007f4bd42c2000) libdl.so.2 =>/lib/x86_64-linux-gnu/libdl.so.2 (0x00007f4bd40be000) libc.so.6 =>/lib/x86_64-linux-gnu/libc.so.6 (0x00007f4bd3cf8000) /lib64/ld-linux-x86-64.so.2 (0x00007f4bd4504000)下面是我的rootfs中的一些so文件:
hchen@ubuntu:~/rootfs$ls ./lib64 ./lib/x86_64-linux-gnu/./lib64:ld-linux-x86-64.so.2./lib/x86_64-linux-gnu/:libacl.so.1 libmemusage.so libnss_files-2.19.so libpython3.4m.so.1libacl.so.1.1.0 libmount.so.1 libnss_files.so.2 libpython3.4m.so.1.0libattr.so.1 libmount.so.1.1.0 libnss_hesiod-2.19.so libresolv-2.19.solibblkid.so.1 libm.so.6 libnss_hesiod.so.2 libresolv.so.2libc-2.19.so libncurses.so.5 libnss_nis-2.19.so libselinux.so.1libcap.a libncurses.so.5.9 libnss_nisplus-2.19.so libtinfo.so.5libcap.so libncursesw.so.5 libnss_nisplus.so.2 libtinfo.so.5.9libcap.so.2 libncursesw.so.5.9 libnss_nis.so.2 libutil-2.19.solibcap.so.2.24 libnsl-2.19.so libpcre.so.3 libutil.so.1libc.so.6 libnsl.so.1 libprocps.so.3 libuuid.so.1libdl-2.19.so libnss_compat-2.19.so libpthread-2.19.so libz.so.1libdl.so.2 libnss_compat.so.2 libpthread.so.0libgpm.so.2 libnss_dns-2.19.so libpython2.7.so.1libm-2.19.so libnss_dns.so.2 libpython2.7.so.1.0包括这些命令依赖的一些配置文件:
hchen@ubuntu:~/rootfs$ls ./etcbash.bashrc group hostname hosts ld.so.cache nsswitch.conf passwd profile resolv.conf shadow你现在会说,我靠,有些配置我希望是在容器起动时给他设置的,而不是hard code在镜像中的。比如:/etc/hosts,/etc/hostname,还有DNS的/etc/resolv.conf文件。好的。那我们在rootfs外面,我们再创建一个conf目录,把这些文件放到这个目录中。
hchen@ubuntu:~$ls ./confhostname hosts resolv.conf这样,我们的父进程就可以动态地设置容器需要的这些文件的配置, 然后再把他们mount进容器,这样,容器的镜像中的配置就比较灵活了。
好了,终于到了我们的程序。
#define _GNU_SOURCE#include <sys/types.h>#include <sys/wait.h>#include <sys/mount.h>#include <stdio.h>#include <sched.h>#include <signal.h>#include <unistd.h>#define STACK_SIZE (1024 * 1024)staticchar container_stack[STACK_SIZE];char*const container_args[] = { "/bin/bash", "-l", NULL};intcontainer_main(void* arg){ printf("Container [%5d] - inside the container!\n", getpid()); //set hostname sethostname("container",10); //remount "/proc" to make sure the "top" and "ps" show container's information if(mount("proc","rootfs/proc","proc", 0, NULL) !=0 ) { perror("proc"); } if(mount("sysfs","rootfs/sys","sysfs", 0, NULL)!=0) { perror("sys"); } if(mount("none","rootfs/tmp","tmpfs", 0, NULL)!=0) { perror("tmp"); } if(mount("udev","rootfs/dev","devtmpfs", 0, NULL)!=0) { perror("dev"); } if(mount("devpts","rootfs/dev/pts","devpts", 0, NULL)!=0) { perror("dev/pts"); } if(mount("shm","rootfs/dev/shm","tmpfs", 0, NULL)!=0) { perror("dev/shm"); } if(mount("tmpfs","rootfs/run","tmpfs", 0, NULL)!=0) { perror("run"); } /* * 模仿Docker的从外向容器里mount相关的配置文件 * 你可以查看:/var/lib/docker/containers/<container_id>/目录, * 你会看到docker的这些文件的。 */ if(mount("conf/hosts","rootfs/etc/hosts","none", MS_BIND, NULL)!=0 || mount("conf/hostname","rootfs/etc/hostname","none", MS_BIND, NULL)!=0 || mount("conf/resolv.conf","rootfs/etc/resolv.conf","none", MS_BIND, NULL)!=0 ) { perror("conf"); } /* 模仿docker run命令中的 -v, --volume=[] 参数干的事 */ if(mount("/tmp/t1","rootfs/mnt","none", MS_BIND, NULL)!=0) { perror("mnt"); } /* chroot 隔离目录 */ if( chdir("./rootfs") != 0 || chroot("./") != 0 ){ perror("chdir/chroot"); } execv(container_args[0], container_args); perror("exec"); printf("Something's wrong!\n"); return1;}intmain(){ printf("Parent [%5d] - start a container!\n", getpid()); intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}sudo运行上面的程序,你会看到下面的挂载信息以及一个所谓的“镜像”:
hchen@ubuntu:~$sudo ./mountParent [ 4517] - start a container!Container [ 1] - inside the container!root@container:/# mountproc on/proc type proc (rw,relatime)sysfs on/sys type sysfs (rw,relatime)none on/tmp type tmpfs (rw,relatime)udev on/dev type devtmpfs (rw,relatime,size=493976k,nr_inodes=123494,mode=755)devpts on/dev/pts type devpts (rw,relatime,mode=600,ptmxmode=000)tmpfs on/run type tmpfs (rw,relatime)/dev/disk/by-uuid/18086e3b-d805-4515-9e91-7efb2fe5c0e2on /etc/hoststype ext4 (rw,relatime,errors=remount-ro,data=ordered)/dev/disk/by-uuid/18086e3b-d805-4515-9e91-7efb2fe5c0e2on /etc/hostnametype ext4 (rw,relatime,errors=remount-ro,data=ordered)/dev/disk/by-uuid/18086e3b-d805-4515-9e91-7efb2fe5c0e2on /etc/resolv.conftype ext4 (rw,relatime,errors=remount-ro,data=ordered)root@container:/# ls /bin /usr/bin/bin:bash chmod echo hostname less more mv ping rm sleep tail test top truncate unamecat chown grep ip ln mount nc ps sed tabs tar timeout touch tty whichchgrp cp gzip kill ls mountpoint netstat pwd sh tac tee toe tr umount/usr/bin:awk env groups head id mesg sort strace tail top uniq vi wc xargsUser Namespace
User Namespace主要是用了CLONE_NEWUSER的参数。使用了这个参数后,内部看到的UID和GID已经与外部不同了,默认显示为65534。那是因为容器找不到其真正的UID所以,设置上了最大的UID(其设置定义在/proc/sys/kernel/overflowuid)。
要把容器中的uid和真实系统的uid给映射在一起,需要修改 /proc/<pid>/uid_map 和/proc/<pid>/gid_map 这两个文件。这两个文件的格式为:
ID-inside-ns ID-outside-ns length
其中:
- 第一个字段ID-inside-ns表示在容器显示的UID或GID,
- 第二个字段ID-outside-ns表示容器外映射的真实的UID或GID。
- 第三个字段表示映射的范围,一般填1,表示一一对应。
比如,把真实的uid=1000映射成容器内的uid=0
$cat /proc/2465/uid_map 0 1000 1再比如下面的示例:表示把namespace内部从0开始的uid映射到外部从0开始的uid,其最大范围是无符号32位整形
$cat /proc/$$/uid_map 0 0 4294967295另外,需要注意的是:
- 写这两个文件的进程需要这个namespace中的CAP_SETUID (CAP_SETGID)权限(可参看Capabilities)
- 写入的进程必须是此user namespace的父或子的user namespace进程。
- 另外需要满如下条件之一:1)父进程将effective uid/gid映射到子进程的user namespace中,2)父进程如果有CAP_SETUID/CAP_SETGID权限,那么它将可以映射到父进程中的任一uid/gid。
这些规则看着都烦,我们来看程序吧(下面的程序有点长,但是非常简单,如果你读过《Unix网络编程》上卷,你应该可以看懂):
#define _GNU_SOURCE#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <sys/wait.h>#include <sys/mount.h>#include <sys/capability.h>#include <stdio.h>#include <sched.h>#include <signal.h>#include <unistd.h>#define STACK_SIZE (1024 * 1024)staticchar container_stack[STACK_SIZE];char*const container_args[] = { "/bin/bash", NULL};intpipefd[2];voidset_map(char* file,int inside_id, int outside_id, int len) { FILE* mapfd =fopen(file,"w"); if(NULL == mapfd) { perror("open file error"); return; } fprintf(mapfd,"%d %d %d", inside_id, outside_id, len); fclose(mapfd);}voidset_uid_map(pid_t pid, intinside_id, intoutside_id, intlen) { charfile[256]; sprintf(file,"/proc/%d/uid_map", pid); set_map(file, inside_id, outside_id, len);}voidset_gid_map(pid_t pid, intinside_id, intoutside_id, intlen) { charfile[256]; sprintf(file,"/proc/%d/gid_map", pid); set_map(file, inside_id, outside_id, len);}intcontainer_main(void* arg){ printf("Container [%5d] - inside the container!\n", getpid()); printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); /* 等待父进程通知后再往下执行(进程间的同步) */ charch; close(pipefd[1]); read(pipefd[0], &ch, 1); printf("Container [%5d] - setup hostname!\n", getpid()); //set hostname sethostname("container",10); //remount "/proc" to make sure the "top" and "ps" show container's information mount("proc","/proc","proc", 0, NULL); execv(container_args[0], container_args); printf("Something's wrong!\n"); return1;}intmain(){ constint gid=getgid(), uid=getuid(); printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); pipe(pipefd); printf("Parent [%5d] - start a container!\n", getpid()); intcontainer_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL); printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid); //To map the uid/gid, // we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent //The file format is // ID-inside-ns ID-outside-ns length //if no mapping, // the uid will be taken from /proc/sys/kernel/overflowuid // the gid will be taken from /proc/sys/kernel/overflowgid set_uid_map(container_pid, 0, uid, 1); set_gid_map(container_pid, 0, gid, 1); printf("Parent [%5d] - user/group mapping done!\n", getpid()); /* 通知子进程 */ close(pipefd[1]); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return0;}上面的程序,我们用了一个pipe来对父子进程进行同步,为什么要这样做?因为子进程中有一个execv的系统调用,这个系统调用会把当前子进程的进程空间给全部覆盖掉,我们希望在execv之前就做好user namespace的uid/gid的映射,这样,execv运行的/bin/bash就会因为我们设置了uid为0的inside-uid而变成#号的提示符。
整个程序的运行效果如下:
hchen@ubuntu:~$iduid=1000(hchen) gid=1000(hchen)groups=1000(hchen)hchen@ubuntu:~$ ./user#<--以hchen用户运行Parent: eUID = 1000; eGID = 1000, UID=1000, GID=1000Parent [ 3262] - start a container!Parent [ 3262] - Container [ 3263]!Parent [ 3262] - user/groupmapping done!Container [ 1] - inside the container!Container: eUID = 0; eGID = 0, UID=0, GID=0#<---Container里的UID/GID都为0了Container [ 1] - setuphostname!root@container:~# id #<----我们可以看到容器里的用户和命令行提示符是root用户了uid=0(root) gid=0(root)groups=0(root),65534(nogroup)虽然容器里是root,但其实这个容器的/bin/bash进程是以一个普通用户hchen来运行的。这样一来,我们容器的安全性会得到提高。
我们注意到,User Namespace是以普通用户运行,但是别的Namespace需要root权限,那么,如果我要同时使用多个Namespace,该怎么办呢?一般来说,我们先用一般用户创建User Namespace,然后把这个一般用户映射成root,在容器内用root来创建其它的Namesapce。
Network Namespace
Network的Namespace比较啰嗦。在Linux下,我们一般用ip命令创建Network Namespace(Docker的源码中,它没有用ip命令,而是自己实现了ip命令内的一些功能——是用了Raw Socket发些“奇怪”的数据,呵呵)。这里,我还是用ip命令讲解一下。
首先,我们先看个图,下面这个图基本上就是Docker在宿主机上的网络示意图(其中的物理网卡并不准确,因为docker可能会运行在一个VM中,所以,这里所谓的“物理网卡”其实也就是一个有可以路由的IP的网卡)
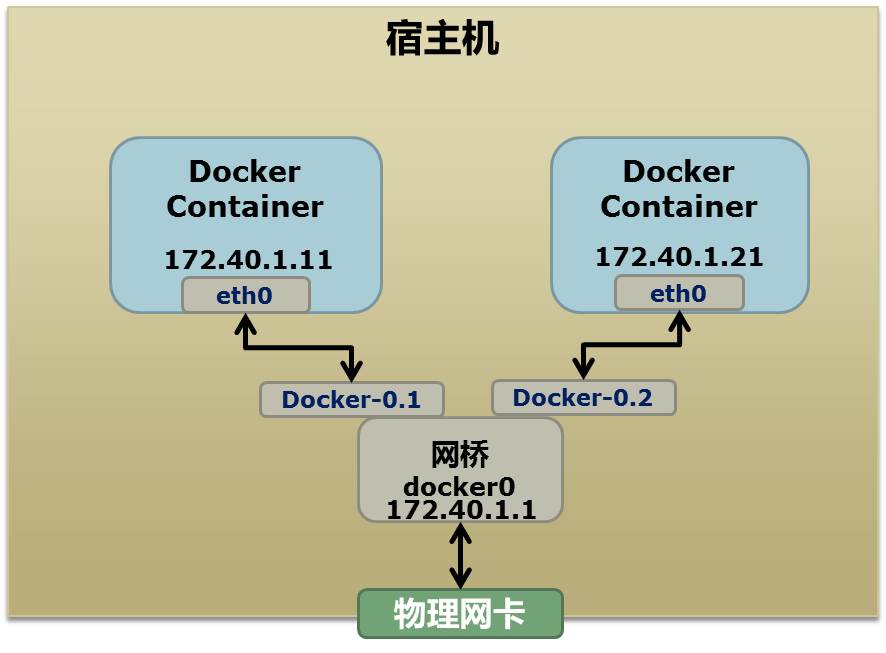
上图中,Docker使用了一个私有网段,172.40.1.0,docker还可能会使用10.0.0.0和192.168.0.0这两个私有网段,关键看你的路由表中是否配置了,如果没有配置,就会使用,如果你的路由表配置了所有私有网段,那么docker启动时就会出错了。
当你启动一个Docker容器后,你可以使用ip link show或ip addr show来查看当前宿主机的网络情况(我们可以看到有一个docker0,还有一个veth22a38e6的虚拟网卡——给容器用的):
hchen@ubuntu:~$ ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state ... link/loopback00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc ... link/ether00:0c:29:b7:67:7d brd ff:ff:ff:ff:ff:ff3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ... link/ether56:84:7a:fe:97:99 brd ff:ff:ff:ff:ff:ff5: veth22a38e6: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc ... link/ether8e:30:2a:ac:8c:d1 brd ff:ff:ff:ff:ff:ff那么,要做成这个样子应该怎么办呢?我们来看一组命令:
## 首先,我们先增加一个网桥lxcbr0,模仿docker0brctl addbr lxcbr0brctl stp lxcbr0 offifconfiglxcbr0 192.168.10.1/24up #为网桥设置IP地址## 接下来,我们要创建一个network namespace - ns1# 增加一个namesapce 命令为 ns1 (使用ip netns add命令)ip netns add ns1# 激活namespace中的loopback,即127.0.0.1(使用ip netns exec ns1来操作ns1中的命令)ip netnsexec ns1 ip link set dev lo up ## 然后,我们需要增加一对虚拟网卡# 增加一个pair虚拟网卡,注意其中的veth类型,其中一个网卡要按进容器中ip link add veth-ns1type veth peer name lxcbr0.1# 把 veth-ns1 按到namespace ns1中,这样容器中就会有一个新的网卡了ip linkset veth-ns1 netns ns1# 把容器里的 veth-ns1改名为 eth0 (容器外会冲突,容器内就不会了)ip netnsexec ns1 ip link set dev veth-ns1 name eth0 # 为容器中的网卡分配一个IP地址,并激活它ip netnsexec ns1 ifconfig eth0 192.168.10.11/24 up# 上面我们把veth-ns1这个网卡按到了容器中,然后我们要把lxcbr0.1添加上网桥上brctl addif lxcbr0 lxcbr0.1# 为容器增加一个路由规则,让容器可以访问外面的网络ip netnsexec ns1 ip route add default via 192.168.10.1# 在/etc/netns下创建network namespce名称为ns1的目录,# 然后为这个namespace设置resolv.conf,这样,容器内就可以访问域名了mkdir-p /etc/netns/ns1echo"nameserver 8.8.8.8" > /etc/netns/ns1/resolv.conf上面基本上就是docker网络的原理了,只不过,
- Docker的resolv.conf没有用这样的方式,而是用了上篇中的Mount Namesapce的那种方式
- 另外,docker是用进程的PID来做Network Namespace的名称的。
了解了这些后,你甚至可以为正在运行的docker容器增加一个新的网卡:
ip link add peerAtype veth peer name peerB brctl addif docker0 peerAip linkset peerA up ip linkset peerB netns ${container-pid} ip netnsexec ${container-pid} ip link set dev peerB name eth1 ip netnsexec ${container-pid} ip link set eth1 up ; ip netnsexec ${container-pid} ip addr add ${ROUTEABLE_IP} dev eth1 ;上面的示例是我们为正在运行的docker容器,增加一个eth1的网卡,并给了一个静态的可被外部访问到的IP地址。
这个需要把外部的“物理网卡”配置成混杂模式,这样这个eth1网卡就会向外通过ARP协议发送自己的Mac地址,然后外部的交换机就会把到这个IP地址的包转到“物理网卡”上,因为是混杂模式,所以eth1就能收到相关的数据,一看,是自己的,那么就收到。这样,Docker容器的网络就和外部通了。
当然,无论是Docker的NAT方式,还是混杂模式都会有性能上的问题,NAT不用说了,存在一个转发的开销,混杂模式呢,网卡上收到的负载都会完全交给所有的虚拟网卡上,于是就算一个网卡上没有数据,但也会被其它网卡上的数据所影响。
这两种方式都不够完美,我们知道,真正解决这种网络问题需要使用VLAN技术,于是Google的同学们为Linux内核实现了一个IPVLAN的驱动,这基本上就是为Docker量身定制的。
Namespace文件
上面就是目前Linux Namespace的玩法。 现在,我来看一下其它的相关东西。
让我们运行一下上篇中的那个pid.mnt的程序(也就是PID Namespace中那个mount proc的程序),然后不要退出。
$ sudo ./pid.mnt[sudo] passwordfor hchen: Parent [ 4599] - start a container!Container [ 1] - inside the container!我们到另一个shell中查看一下父子进程的PID:
hchen@ubuntu:~$ pstree -p 4599pid.mnt(4599)───bash(4600)我们可以到proc下(/proc//ns)查看进程的各个namespace的id(内核版本需要3.8以上)。
下面是父进程的:
hchen@ubuntu:~$sudo ls -l /proc/4599/nstotal 0lrwxrwxrwx 1 root root 0 4月 7 22:01 ipc -> ipc:[4026531839]lrwxrwxrwx 1 root root 0 4月 7 22:01 mnt -> mnt:[4026531840]lrwxrwxrwx 1 root root 0 4月 7 22:01 net -> net:[4026531956]lrwxrwxrwx 1 root root 0 4月 7 22:01 pid -> pid:[4026531836]lrwxrwxrwx 1 root root 0 4月 7 22:01 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 4月 7 22:01 uts -> uts:[4026531838]下面是子进程的:
hchen@ubuntu:~$sudo ls -l /proc/4600/nstotal 0lrwxrwxrwx 1 root root 0 4月 7 22:01 ipc -> ipc:[4026531839]lrwxrwxrwx 1 root root 0 4月 7 22:01 mnt -> mnt:[4026532520]lrwxrwxrwx 1 root root 0 4月 7 22:01 net -> net:[4026531956]lrwxrwxrwx 1 root root 0 4月 7 22:01 pid -> pid:[4026532522]lrwxrwxrwx 1 root root 0 4月 7 22:01 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 4月 7 22:01 uts -> uts:[4026532521]我们可以看到,其中的ipc,net,user是同一个ID,而mnt,pid,uts都是不一样的。如果两个进程指向的namespace编号相同,就说明他们在同一个namespace下,否则则在不同namespace里面。
这些文件还有另一个作用,那就是,一旦这些文件被打开,只要其fd被占用着,那么就算PID所属的所有进程都已经结束,创建的namespace也会一直存在。比如:我们可以通过:mount –bind /proc/4600/ns/uts ~/uts 来hold这个namespace。
另外,我们在上篇中讲过一个setns的系统调用,其函数声明如下:
intsetns(intfd, intnstype);其中第一个参数就是一个fd,也就是一个open()系统调用打开了上述文件后返回的fd,比如:
fd = open("/proc/4600/ns/nts", O_RDONLY); // 获取namespace文件描述符setns(fd, 0);// 加入新的namespacehttp://segmentfault.com/a/1190000002734062
http://zhuanlan.zhihu.com/prattle/19693311
http://coolshell.cn/articles/17010.html
http://coolshell.cn/articles/17029.html
http://dockone.io/article/368
- docker
- docker
- docker
- docker
- Docker
- Docker
- docker
- Docker
- Docker
- Docker
- Docker
- docker
- Docker
- Docker
- docker
- Docker
- Docker
- Docker
- Linux下的虚拟Bridge实现
- IDF-CTF-牛刀小试-聪明的小羊
- 字符串的相等比较
- 再次出发
- 第十二周项目四 点圆的关系
- Docker
- Swift-字符串
- Linux学习-高级shell脚本编程(二)初识sed和gawk
- Qt绘制贝塞尔曲线例程
- openwrt Makefile理解
- (半翻译)篡改mac应用后,如何resign签名,重新获得mac系统的信任?
- 可用MinGW编译的win32绘图框架
- 集合框架
- openwrt Makefile 理解


