hadoop2.5.2HA高可靠性集群搭建(zookeeper3.4.6+hbase0.98.11)
来源:互联网 发布:淘宝网管理团队 编辑:程序博客网 时间:2024/06/01 21:27
hadoop2.5.2HA高可靠性集群搭建(zookeeper3.4.6+hbase0.98.11)
寻找 会’偷懒’的开发者线下公开课,报名即享受免费体验云主机
在hadoop2中新的NameNode不再是只有一个,可以有多个(目前只支持2个)。每一个都有相同的职能。
一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了。这就是高可靠。
在这里,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,JournalNode集群或者NFS进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享。
这就需要使用ZooKeeper集群进行选择了。HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
一、配置前准备
1、SSH免登陆(略)
2、文件/etc/profile
export PATH=.:$PATHexport CLASSPATH=.:$CLASSPATH #java export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/libexport PATH=$PATH:$JAVA_HOME/bin #zookeeper export ZOOKEEPER_HOME=/home/mars/zookeeperexport CLASSPATH=$CLASSPATH:$ZOOKEEPER_HOME/libexport PATH=$PATH:$ZOOKEEPER_HOME/bin #hadoop export HADOOP_HOME=/home/mars/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/export CLASSPATH=$CLASSPATH:$HADOOP_HOME/libexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #hbase export HBASE_HOME=/home/mars/hbaseexport CLASSPATH=$CLASSPATH:$HBASE_HOME/libexport PATH=$PATH:$HADOOP_HOME/bin配置后需要执行
source /etc/profile才会生效
3、文件/etc/host
127.0.0.1 localhost192.168.16.217 os1192.168.16.218 os2192.168.16.212 os3192.168.16.213 os4192.168.16.214 os5配置后需要执行
source /etc/hosts才会生效
二、配置详细
1、各机器职责
机器有限,我这里选用5台机器配置,各自职责如下
配置文件一共包括6个,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves。
2、文件hadoop-env.sh
修改一行配置
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd643、文件core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://whcx</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/mars/hadoop/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>os1:2181,os2:2181,os3:2181</value> </property></configuration>4、文件hdfs-site.xml
<configuration> <property> <name>dfs.name.dir</name> <value>/home/mars/hadoop/tmp/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/mars/hadoop/tmp/data,/sas/hadoop/data</value> <!-- /sas/hadoop/data 这台电脑挂载了另一个盘 --> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.nameservices</name> <value>whcx</value> </property> <property> <name>dfs.ha.namenodes.whcx</name> <value>os1,os2</value> </property> <property> <name>dfs.namenode.rpc-address.whcx.os1</name> <value>os1:9000</value> </property> <property> <name>dfs.namenode.http-address.whcx.os1</name> <value>os1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.whcx.os2</name> <value>os2:9000</value> </property> <property> <name>dfs.namenode.http-address.whcx.os2</name> <value>os2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://os1:8485;os2:8485;os3:8485/whcx</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.whcx</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.whcx</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/mars/hadoop/tmp/journal</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/mars/.ssh/id_rsa</value> </property></configuration>5、mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>6、yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>os1</value> <!-- resourcemanager在os1上 --> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property></configuration>7、slaves
os1 os2 os3 os4 os58、zookeeper配置
zookeeper中/conf/zoo.cnf
tickTime=2000initLimit=10syncLimit=5dataDir=/home/mars/zookeeper/dataclientPort=2181server.1=os1:2888:3888server.2=os2:2888:3888server.3=os3:2888:3888zookeeper中新建data目录,在data目录下新建文件myid
和zoo.cnf中的配置保持一致,os1中的myid编辑为1,os2中的myid编辑为2,os3中的myid编辑为3
9、hbase配置
文件hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://whcx/hbase</value><!--这里必须跟core-site.xml中的配置一样--> </property> <!-- 开启分布式模式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 这里是对的,只配置端口,为了配置多个HMaster --> <property> <name>hbase.master</name> <value>os2:60000</value> </property> <property> <name>hbase.tmp.dir</name> <value>/home/mars/hbase/tmp</value> </property> <!-- Hbase的外置zk集群时,使用下面的zk端口 --> <property> <name>hbase.zookeeper.quorum</name> <value>os1:2181,os2:2181,os3:2181</value> </property></configuration>三、启动过程
1、启动Zookeeper集群
分别在os1、os2、os3上执行
zkServer.sh start然后执行
zkServer.sh status查看是否启动,确保启动后执行后面的步骤
三个节点都启动后,执行
zkCli.sh然后执行
ls /查看Zookeeper集群中是否有HA节点
2、格式化Zookeeper集群,目的是在Zookeeper集群上建立HA的相应节点
在os1上执行
hdfs zkfc –formatZK(注意,这条命令最好手动输入,直接copy执行有可能会有问题)
格式化后验证,执行
zkCli.sh在执行
ls /会出现下图中红色部分

则表示格式化成功
ls /hadoop-ha会出现我们配置的HA集群名称

3、启动Journal集群
分别在os1、os2、os3上执行
hadoop-daemon.sh start journalnode4、格式化集群上的一个NameNode
从os1和os2上任选一个即可,这里我是在os1
hdfs namenode -format -clusterId ss5、启动集群中步骤4中的NameNode
启动os1上的NameNode
hadoop-daemon.sh start namenode6、把NameNode的数据同步到另一个NameNode上
把NameNode的数据同步到os2上
hdfs namenode –bootstrapStandby这条命令依旧需要手动敲
同步数据还有另一种方法
直接copy数据到os2上
scp -r /home/mars/hadoop/tmp mars@os2:/home/mars/hadoop/tmp如果第一种方法同步失败可以采用第二种同步方法
7、启动另个一NameNode
在os2上执行
hadoop-daemon.sh start namenode8、启动所有的DataNode
hadoop-daemons.sh start datanode9、启动Yarn
start-yarn.sh10、启动Hbase
start-hbase.sh11、启动ZKFC
分别在os1、os2上执行
hadoop-daemon.sh start zkfc
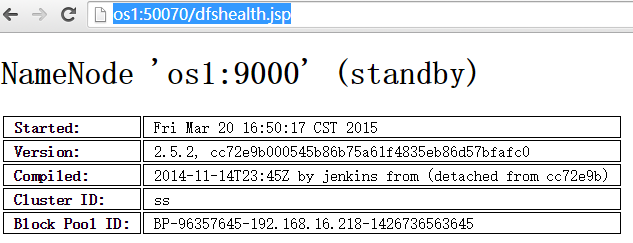
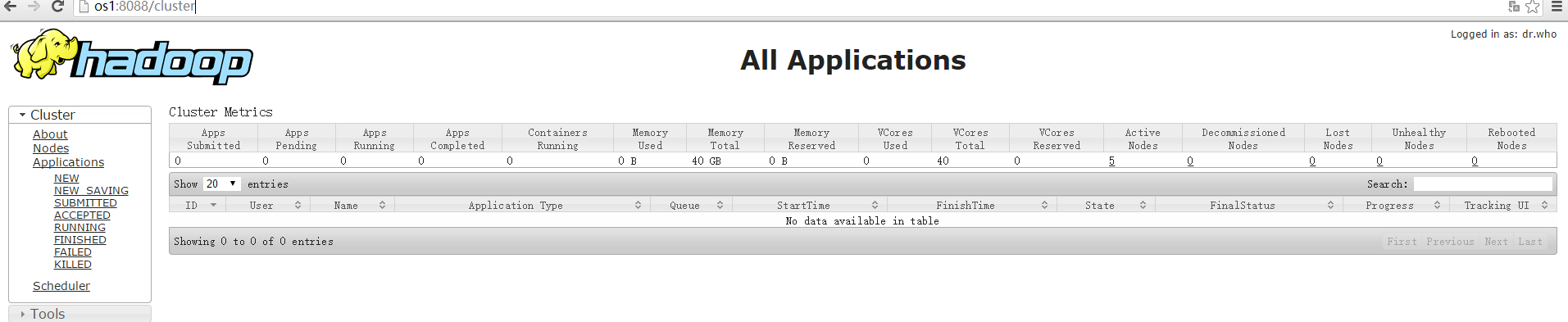
至此配置成功
结束语
由于是测试环境,且机器有限,每个机器上职责重,如果是在实际生产中,个人认为,作为任务的分发分配,应该给ResourceManager分配一台机器,这台机器只仅仅只运行ResourceManager,journal集群也该分配三台机器来共享元数据。我这里的主节点同时也是从节点,实际生产中不会这么做。
- hadoop2.5.2HA高可靠性集群搭建(zookeeper3.4.6+hbase0.98.11)
- hadoop--hadoop2.5.2HA高可靠性集群搭建(zookeeper3.4.6+hbase0.98.11)
- Hadoop2.7.0 HA高可靠性集群搭建
- Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop2.2.0 HA + Jdk1.8.0 + Zookeeper3.4.5 + Hbase0.98 集群搭建详细过程(服务器集群)
- Hadoop2.2.0 HA + Jdk1.8.0 + Zookeeper3.4.5 + Hbase0.98 集群搭建详细过程(服务器集群)
- Hadoop2.5.2+Zookeeper3.4.6 + HBase0.98.8-hadoop2环境搭建
- Hadoop2.6..0 HA高可靠性集群搭建(Hadoop+Zookeeper)
- Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备
- Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
- hadoop2.5.2+zookeeper3.4.6+hbase0.99.2
- hadoop2.5.2+zookeeper3.4.6+hbase0.99.2
- Hadoop2.6.0 + Zookeeper3.4.6 + HBase0.98.9hadoop2环境搭建示例
- hadoop1.2.1+zookeeper3.4.6+hbase0.94集群环境搭建
- TaskTriggerType 根据事件类型来确定节点
- spring 的 AOP详解
- 生成表记录的SQL语句
- 测试博文测试博文测试博文
- 2015腾讯微博登陆解密基于httpclient抓包模拟登陆
- hadoop2.5.2HA高可靠性集群搭建(zookeeper3.4.6+hbase0.98.11)
- 测试博文测试博文测试博文
- 用户体验可以从那些方面去着手
- w3school 对 base 标签的解释
- Mac上使用远程桌面软件连接Windows或Linux
- 关于ajax跨域问题josnp的解决方案
- ffmpeg compile summary
- android 之EditText输入检测
- 测试博文测试博文测试博文


