线性判别分析Linear Discriminant Analysis学习心得
来源:互联网 发布:c#的json怎么用 编辑:程序博客网 时间:2024/05/21 10:23
判别分析(Discriminant Analysis)根据研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
根据判别标准不同可以分为距离判别、Fisher判别、Bayes判别法
LDA和PCA区别:
PCA(Principal Component Analysis)是无监督的方式,它没有分类标签,降维之后需要采用K-Means或自组织映射网络等无监督的算法进行分类。而LDA是有监督的方式,它先对训练数据进行降维,然后找出一个线性判别函数。
两类线性判别分析:
给定N个特征为d维的样例
,其中有N1个样例属于类别w1,另外N2个样例属于类别w2。首先将原始数据降低到只有一维,降维函数(又叫投影函数):
,依靠每个样例对应的y值来判别它属于哪一类。将这个最佳的向量称为w(d维),那么样例x(d维)到w上的投影可以用上式计算。
上图可以很好滴将不同类别的样本点分离,接下来我们从定量的角度来找到这个最佳的w.
定义均值点:
由于x到w投影后的样本点均值为:
由此可知,投影后的均值也就是样本中心点的投影。
最佳的直线(w),能够使投影后的两类样本中线尽量分离的直线才是比较好的直线,定量表示就是:
只考虑J(w是不行的
样本点均值分布在椭圆里,投影到横轴X1上时能够获得更大的中心店间距J(w),但是由于有重叠,X1不能分离样本点,X1不能分离样本点。投影到纵轴X2上,虽然J(w)较小,但是能够分离样本点。因此还是需要考虑样本点之间的方差,方差越大,样本点越难分离。
使用另一个度量值,乘坐散列值(scatter),对投影后的类求散列值:
公式表示,知识少除以样本数量的方差值,散列值得几何意义是样本点的密集程度,值越大,越分散,反之,越集中。
我们需要的投影效果是:不同类别的样本点越分开越好,同类的越聚集越好,也就是均值差越大越好。散列值越小越好
可以使用J(w)和S来度量,最终的度量公式是:
接下来只需要寻找使J(w)最大的w即可
先把散列值公式展开
定义上式中中间那部分
那么久变成了散列矩阵(scatter matrices)
Sw=S1+S2
Sw称为Within-class scatter matrix
展开分子
那么J(w)最终可以表示为
在我们求导之前,需要对分母进行归一化,因为不做归一的话,w扩大任何倍数,都是成立的,因此我们令:
加入拉格朗日乘子后,求导
这个公式称为Fisher linear discrimination
那么
代入最后的特征值公式得
由于对w扩大缩小任何倍都不影响结果,已承诺可以约去两边的未知常数![]() 和
和![]() w,得到
w,得到
至此,我们只需要求出原始样本的均值和方差就可以就出最佳的方向w,
上面二维样本的投影结果:
多类线性判别分析
假设有C个类别,降以一维已经不能满足分类要求了,我们需要k个基向量来做投影,W=[w1|w2|...|wk] 。样本点在这k维投影后的结果为[y1,y2,...,yk],且有当样本是二维时,我们从几何意义上考虑:
其中![]() 和
和![]() 与上节的意义一样,
与上节的意义一样,![]() 是类别1里的样本点相对于该类中心点
是类别1里的样本点相对于该类中心点![]() 的散列程度。
的散列程度。![]() 变成类别1中心点相对于样本中心点
变成类别1中心点相对于样本中心点![]() 的协方差矩阵,即类1相对于
的协方差矩阵,即类1相对于![]() 的散列程度。
的散列程度。
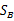 需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对与样本中心的散列情况。类似于将
需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对与样本中心的散列情况。类似于将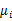 看作是样本点,
看作是样本点,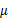 是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但是由于J(w)对倍数不敏感,因此使用Ni
是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但是由于J(w)对倍数不敏感,因此使用Ni
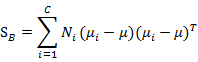
其中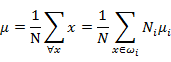
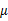 是所有样本的均值。
是所有样本的均值。
真正的J(w)的分子分母都是在投影后计算的。下面我们看样本点投影后的公式改变:
这两个是第i类样本点在某基向量上投影后的均值计算公式。
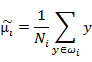
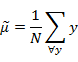
下面两个是在某基向量上投影后的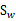 和
和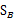
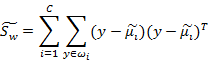
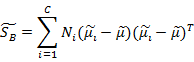
其实就是将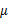 换成了
换成了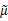
综合各个投影向量(W)上的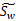 和
和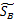 ,更新这两个参数,得到
,更新这两个参数,得到
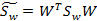
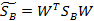
W是基向量矩阵,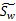 是投影后的各个类内部的散列矩阵之和。
是投影后的各个类内部的散列矩阵之和。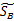 是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
回想我们上节的公式J(w),分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。
然而,最后的J(w)的形式是
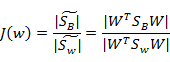
由于我们得到的分子分母都是散列矩阵,要将矩阵变成实数,需要取行列式。
又因为行列式的值实际上是矩阵特征值的积,一个特征值可以表示在该特征向量上的发散程度。
然后求J(w)的最大值了,固定分母为1,然后求导,得出最后结果。
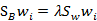
推出
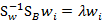
最后求矩阵的特征值,首先求出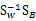 的特征值,然后取前K个特征向量组成W矩阵即可。
的特征值,然后取前K个特征向量组成W矩阵即可。
由于不一定是对称矩阵,因此k个特征向量不一定正交,这也是与PCA不同的地方。求
的特征向量不能采用奇异值分解的方式,而因该采用更通用的求一般方阵特征向量的方式。特征值的求法有很多,求一个D * D的矩阵的时间复杂度是O(D^3), 也有一些求Top k的方法,比如说幂法,它的时间复杂度是O(D^2 * k)。
那降维之后又如何根据y值来判别分类呢?取[y1,y2,...,yk]中最大的那个就是所属的分类。
使用LDA的限制1.LDA至多可生成C-1为子空间
2.LDA不适合对非高斯分布的样本进行降维
3.LDA在样本分类信息依赖方差而不是均值时,效果不好
4.LDA可能过度拟合数据
- 线性判别分析Linear Discriminant Analysis学习心得
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear discriminant analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- fisher linear discriminant analysis(fisher线性判别分析)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析 (Linear Discriminant Analysis) (一)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis)
- 线性判别分析(Linear Discriminant Analysis,LDA)
- 机器学习: Linear Discriminant Analysis 线性判别分析
- 线性判别分析(Linear Discriminant Analysis)
- protel设计需注意事项
- 操作系统概念学习笔记 15 内存管理(一)
- POJ 2533 Longest Ordered Subsequence(LIS)
- 修复iOS7下leftBarButtonItem位置相比之前版本靠右的问题
- 中国饭局规矩和意识
- 线性判别分析Linear Discriminant Analysis学习心得
- 【leetcode】No. 235 LCABST
- Jquery 对新插入的节点 绑定Click事件失效
- 哈佛为什么群星闪耀?
- CodeForces 7A
- javascript高级程序设计笔记--js操作符
- 黑马程序员-IOS学习笔记 用位远算来判断一个数是奇数还是偶数
- EditText文本框的焦点事件
- PCB设计的一些原则及Protel DXP的一些操作总结


