ElasticSearch处理更新冲突
来源:互联网 发布:淘宝金冠女装店铺大全 编辑:程序博客网 时间:2024/05/29 09:17
当使用index API更新文档的时候,我们读取原始文档,做修改,然后将整个文档(whole document)一次性重新索引。最近的索引请求会生效——Elasticsearch中只存储最后被索引的任何文档。如果其他人同时也修改了这个文档,他们的修改将会丢失。
很多时候,这并不是一个问题。或许我们主要的数据存储在关系型数据库中,然后拷贝数据到Elasticsearch中只是为了可以用于搜索。或许两个人同时修改文档的机会很少。亦或者偶尔的修改丢失对于我们的工作来说并无大碍。
但有时丢失修改是一个很严重的问题。想象一下我们使用Elasticsearch存储大量在线商店的库存信息。每当销售一个商品,Elasticsearch中的库存就要减一。
一天,老板决定做一个促销。瞬间,我们每秒就销售了几个商品。想象两个同时运行的web进程,两者同时处理一件商品的订单:
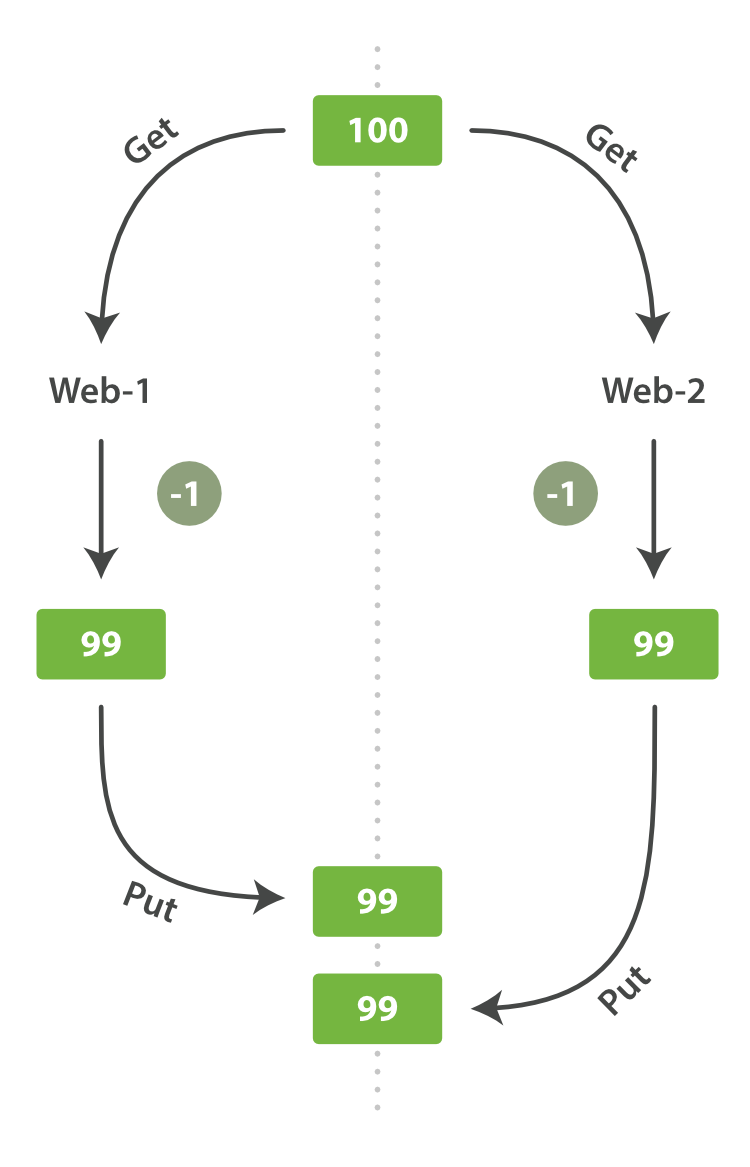
web_1让stock_count失效是因为web_2没有察觉到stock_count的拷贝已经过期(译者注:web_1取数据,减一后更新了stock_count。可惜在web_1更新stock_count前它就拿到了数据,这个数据已经是过期的了,当web_2再回来更新stock_count时这个数字就是错的。这样就会造成看似卖了一件东西,其实是卖了两件,这个应该属于幻读。)。结果是我们认为自己确实还有更多的商品,最终顾客会因为销售给他们没有的东西而失望。
变化越是频繁,或读取和更新间的时间越长,越容易丢失我们的更改。
在数据库中,有两种通用的方法确保在并发更新时修改不丢失:
悲观并发控制(Pessimistic concurrency control)
这在关系型数据库中被广泛的使用,假设冲突的更改经常发生,为了解决冲突我们把访问区块化。典型的例子是在读一行数据前锁定这行,然后确保只有加锁的那个线程可以修改这行数据。
乐观并发控制(Optimistic concurrency control):
被Elasticsearch使用,假设冲突不经常发生,也不区块化访问,然而,如果在读写过程中数据发生了变化,更新操作将失败。这时候由程序决定在失败后如何解决冲突。实际情况中,可以重新尝试更新,刷新数据(重新读取)或者直接反馈给用户。
乐观并发控制
Elasticsearch是分布式的。当文档被创建、更新或删除,文档的新版本会被复制到集群的其它节点。Elasticsearch即是同步的又是异步的,意思是这些复制请求都是平行发送的,并无序(out of sequence)的到达目的地。这就需要一种方法确保老版本的文档永远不会覆盖新的版本。
上文我们提到index、get、delete请求时,我们指出每个文档都有一个_version号码,这个号码在文档被改变时加一。Elasticsearch使用这个_version保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
我们利用_version的这一优点确保数据不会因为修改冲突而丢失。我们可以指定文档的version来做想要的更改。如果那个版本号不是现在的,我们的请求就失败了。
Let's create a new blog post: 让我们创建一个新的博文:
PUT /website/blog/1/_create{ "title": "My first blog entry", "text": "Just trying this out..."}响应体告诉我们这是一个新建的文档,它的_version是1。现在假设我们要编辑这个文档:把数据加载到web表单中,修改,然后保存成新版本。
首先我们检索文档:
GET /website/blog/1响应体包含相同的_version是1
{ "_index" : "website", "_type" : "blog", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "title": "My first blog entry", "text": "Just trying this out..." }}现在,当我们通过重新索引文档保存修改时,我们这样指定了version参数:
PUT /website/blog/1?version=1 <1>{ "title": "My first blog entry", "text": "Starting to get the hang of this..."}- <1> 我们只希望文档的
_version是1时更新才生效。
This request succeeds, and the response body tells us that the _version has been incremented to 2:
请求成功,响应体告诉我们_version已经增加到2:
{ "_index": "website", "_type": "blog", "_id": "1", "_version": 2 "created": false}然而,如果我们重新运行相同的索引请求,依旧指定version=1,Elasticsearch将返回409 Conflict状态的HTTP响应。响应体类似这样:
{ "error" : "VersionConflictEngineException[[website][2] [blog][1]: version conflict, current [2], provided [1]]", "status" : 409}这告诉我们当前_version是2,但是我们指定想要更新的版本是1。
我们需要做什么取决于程序的需求。我们可以告知用户其他人修改了文档,你应该在保存前再看一下。而对于上文提到的商品stock_count,我们需要重新检索最新文档然后申请新的更改操作。
所有更新和删除文档的请求都接受version参数,它可以允许在你的代码中增加乐观锁控制。
使用外部版本控制系统
一种常见的结构是使用一些其他的数据库做为主数据库,然后使用Elasticsearch搜索数据,这意味着所有主数据库发生变化,就要将其拷贝到Elasticsearch中。如果有多个进程负责这些数据的同步,就会遇到上面提到的并发问题。
如果主数据库有版本字段——或一些类似于timestamp等可以用于版本控制的字段——是你就可以在Elasticsearch的查询字符串后面添加version_type=external来使用这些版本号。版本号必须是整数,大于零小于9.2e+18——Java中的正的long。
外部版本号与之前说的内部版本号在处理的时候有些不同。它不再检查_version是否与请求中指定的一致,而是检查是否小于指定的版本。如果请求成功,外部版本号就会被存储到_version中。
外部版本号不仅在索引和删除请求中指定,也可以在创建(create)新文档中指定。
例如,创建一个包含外部版本号5的新博客,我们可以这样做:
PUT /website/blog/2?version=5&version_type=external{ "title": "My first external blog entry", "text": "Starting to get the hang of this..."}在响应中,我们能看到当前的_version号码是5:
{ "_index": "website", "_type": "blog", "_id": "2", "_version": 5, "created": true}现在我们更新这个文档,指定一个新version号码为10:
PUT /website/blog/2?version=10&version_type=external{ "title": "My first external blog entry", "text": "This is a piece of cake..."}请求成功的设置了当前_version为10:
{ "_index": "website", "_type": "blog", "_id": "2", "_version": 10, "created": false}如果你重新运行这个请求,就会返回一个像之前一样的冲突错误,因为指定的外部版本号不大于当前在Elasticsearch中的版本。
文档局部更新
在上面我们说了一种通过检索,修改,然后重建整文档的索引方法来更新文档。这是对的。然而,使用update API,我们可以使用一个请求来实现局部更新,例如增加数量的操作。
我们也说过文档是不可变的——它们不能被更改,只能被替换。update API必须遵循相同的规则。表面看来,我们似乎是局部更新了文档的位置,内部却是像我们之前说的一样简单的使用update API处理相同的检索-修改-重建索引流程,我们也减少了其他进程可能导致冲突的修改。
最简单的update请求表单接受一个局部文档参数doc,它会合并到现有文档中——对象合并在一起,存在的标量字段被覆盖,新字段被添加。举个例子,我们可以使用以下请求为博客添加一个tags字段和一个views字段:
POST /website/blog/1/_update{ "doc" : { "tags" : [ "testing" ], "views": 0 }}如果请求成功,我们将看到类似index请求的响应结果:
{ "_index" : "website", "_id" : "1", "_type" : "blog", "_version" : 3}检索文档文档显示被更新的_source字段:
{ "_index": "website", "_type": "blog", "_id": "1", "_version": 3, "found": true, "_source": { "title": "My first blog entry", "text": "Starting to get the hang of this...", "tags": [ "testing" ], <1> "views": 0 <1> }}- <1> 我们新添加的字段已经被添加到
_source字段中。
使用脚本局部更新
使用Groovy脚本
这时候当API不能满足要求时,Elasticsearch允许你使用脚本实现自己的逻辑。脚本支持非常多的API,例如搜索、排序、聚合和文档更新。脚本可以通过请求的一部分、检索特殊的
.scripts索引或者从磁盘加载方式执行。默认的脚本语言是Groovy,一个快速且功能丰富的脚本语言,语法类似于Javascript。它在一个沙盒(sandbox)中运行,以防止恶意用户毁坏Elasticsearch或攻击服务器。
你可以在《脚本参考文档》中获得更多信息。
脚本能够使用update API改变_source字段的内容,它在脚本内部以ctx._source表示。例如,我们可以使用脚本增加博客的views数量:
POST /website/blog/1/_update{ "script" : "ctx._source.views+=1"}我们还可以使用脚本增加一个新标签到tags数组中。在这个例子中,我们定义了一个新标签做为参数而不是硬编码在脚本里。这允许Elasticsearch未来可以重复利用脚本,而不是在想要增加新标签时必须每次编译新脚本:
POST /website/blog/1/_update{ "script" : "ctx._source.tags+=new_tag", "params" : { "new_tag" : "search" }}获取最后两个有效请求的文档:
{ "_index": "website", "_type": "blog", "_id": "1", "_version": 5, "found": true, "_source": { "title": "My first blog entry", "text": "Starting to get the hang of this...", "tags": ["testing", "search"], <1> "views": 1 <2> }}- <1>
search标签已经被添加到tags数组。 - <2>
views字段已经被增加。
通过设置ctx.op为delete我们可以根据内容删除文档:
POST /website/blog/1/_update{ "script" : "ctx.op = ctx._source.views == count ? 'delete' : 'none'", "params" : { "count": 1 }}更新可能不存在的文档
想象我们要在Elasticsearch中存储浏览量计数器。每当有用户访问页面,我们增加这个页面的浏览量。但如果这是个新页面,我们并不确定这个计数器存在与否。当我们试图更新一个不存在的文档,更新将失败。
在这种情况下,我们可以使用upsert参数定义文档来使其不存在时被创建。
POST /website/pageviews/1/_update{ "script" : "ctx._source.views+=1", "upsert": { "views": 1 }}第一次执行这个请求,upsert值被索引为一个新文档,初始化views字段为1.接下来文档已经存在,所以script被更新代替,增加views数量。
更新和冲突
这这一节的介绍中,我们介绍了如何在检索(retrieve)和重建索引(reindex)中保持更小的窗口,如何减少冲突性变更发生的概率,不过这些无法被完全避免,像一个其他进程在update进行重建索引时修改了文档这种情况依旧可能发生。
为了避免丢失数据,update API在检索(retrieve)阶段检索文档的当前_version,然后在重建索引(reindex)阶段通过index请求提交。如果其他进程在检索(retrieve)和重加索引(reindex)阶段修改了文档,_version将不能被匹配,然后更新失败。
对于多用户的局部更新,文档被修改了并不要紧。例如,两个进程都要增加页面浏览量,增加的顺序我们并不关心——如果冲突发生,我们唯一要做的仅仅是重新尝试更新既可。
这些可以通过retry_on_conflict参数设置重试次数来自动完成,这样update操作将会在发生错误前重试——这个值默认为0。
POST /website/pageviews/1/_update?retry_on_conflict=5 <1>{ "script" : "ctx._source.views+=1", "upsert": { "views": 0 }}- <1> 在错误发生前重试更新5次
这适用于像增加计数这种顺序无关的操作,但是还有一种顺序非常重要的情况。例如index API,使用“保留最后更新(last-write-wins)”的update API,但它依旧接受一个version参数以允许你使用乐观并发控制(optimistic concurrency control)来指定你要更细文档的版本。
- ElasticSearch处理更新冲突
- ElasticSearch-更新与更新冲突
- Elasticsearch - 处理冲突
- Elasticsearch - 处理冲突
- elasticsearch-并发冲突处理
- Elasticsearch 冲突处理
- Elasticsearch之处理冲突。
- ElasticSearch-冲突处理
- Elasticsearch(处理冲突)
- elasticSearch之版本冲突处理
- ElasticSearch:版本冲突处理(事务控制)
- ElasticSearch:版本冲突处理(事务控制)
- 多数据更新冲突处理机制
- ElasticSearch JavaAPI jar包冲突
- elasticsearch更新文档数据
- elasticsearch更新数据
- Elasticsearch 文档更新操作
- Elasticsearch更新操作
- 黑马程序员——递归
- GCC、Cygwin、MinGW、TDM-GCC
- UTF-8,GBK,Big5,ASCII
- iOS——Xcode 6.1 企业版app发布(In-House模式)详细步骤
- android 强制关闭后台程序方法
- ElasticSearch处理更新冲突
- ashx文件的使用小结
- ROS进阶学习手记 3 -- RViz工具的学习2,Markers: Sending Basic Shapes
- 8大你不得不知的Android调试工具
- The Child and Toy
- 如何手动删除不需要的windows服务
- ANDROID L——Material Design综合应用(Demo) .
- Reverse Linked List II
- 为什么我一直不懈的养着这个博客但是还审核


