第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(2)
来源:互联网 发布:单片机接反会 编辑:程序博客网 时间:2024/06/05 19:16
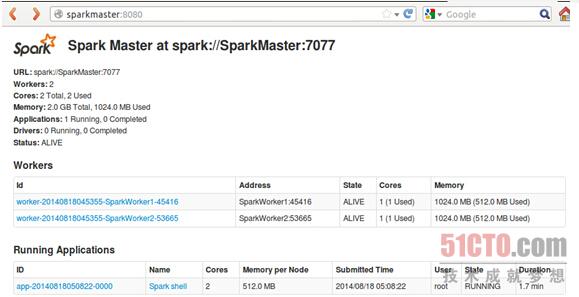
Spark-shell启动后我们可以在控制台看到起运行信息:
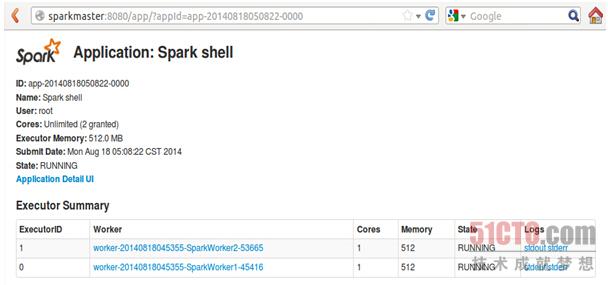
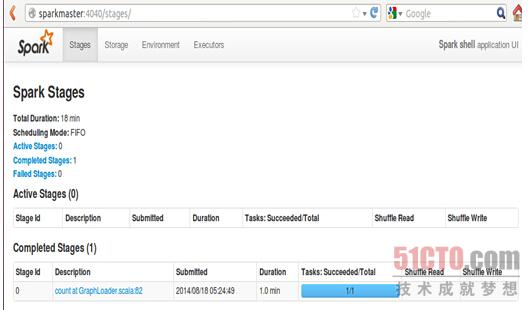
点击作业ID即可查看Spark shell运行信息:
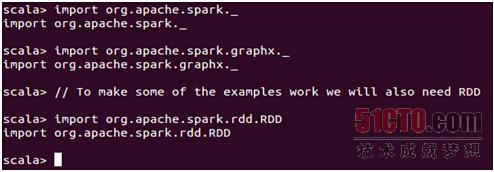
下面我们就开始在集群上通过读取hdfs文件的方式来构建graph对象,首先要做的就是引入相关的包,如下所示:
然后通过加载hdfs中的web-Google.txt来构建graph,如下所示:
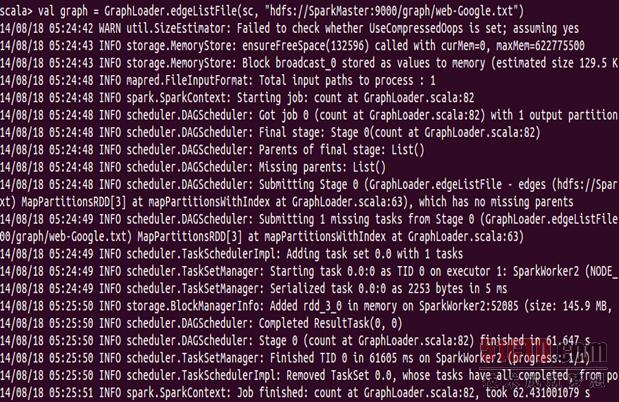
在load的过程中,我们可以看一下Spark shell的web控制台:
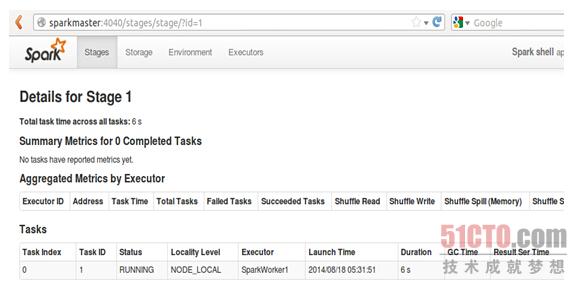
此时我们发现只有一个partition在运行:
本文转自http://book.51cto.com/art/201409/451608.htm,所有权力归原作者所有。
0 0
- 第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(2)
- 第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(3)
- 使用spark读取es中的数据并进行数据清洗,使用fp-growth算法进行加工
- 第八章:在Spark集群上掌握比较重要的图操作之Property Operators(2)
- 使用Python+jieba和java+庖丁分词在Spark集群上进行中文分词统计
- 使用Python+jieba和java+庖丁分词在Spark集群上进行中文分词统计
- 如何在Ubuntu上搭建Spark独立集群管理器(Spark快速大数据分析)
- Spark-在工作集上进行集群计算
- Spark应用程序创建并在集群上运行
- 第八章:在Spark集群上掌握比较重要的图操作之Property Operators(1)
- Spark学习之在集群上运行Spark(6)
- 在Kaggle手写数字数据集上使用Spark MLlib的RandomForest进行手写数字识别
- 第九章:在Spark集群上掌握比较重要的图操作之Structural Operators
- 第十章:在Spark集群上掌握比较重要的图操作之Computing Degree
- 在集群上安装spark
- spark在集群上运行
- 在集群上运行Spark
- Spark入门--基于Intellij IDEA开发Spark应用并在集群上运行
- AIX系统中使用bsdlog函数输出内核信息
- 2012年5月SAT香港真题解析
- moc简介
- Android NDK HelloWorld
- javascript高级程序设计---事件类eventUntil
- 第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(2)
- 序列化那点事
- sql全文索引
- 【leetcode】Construct Binary Tree from Preorder and Inorder Traversal
- 仿照余额宝余额动态变动
- MFC学习之路02 获取当前路径,显示屏大小,弹出路径选择框
- PHP调用WebService接口
- 正则经验
- 第七章:在Spark集群上使用文件中的数据加载成为graph并进行操作(3)


