MapReduce之计数器及实例
来源:互联网 发布:软件腰带剑多少钱 编辑:程序博客网 时间:2024/05/22 05:32
MapReduce之计数器及实例
http://www.aboutyun.com/thread-13745-1-1.html
计数器使用:
http://www.aboutyun.com/thread-13745-1-1.html
感兴趣的直接点上面链接,会有更详细的解析
问题导读
1.hadoop有哪些内置计数器?
2.job.getCounters()可以得到什么?
3.MapReduce是否允许用户自定义计数器?
简述:
Hadoop计数器:可以让开发人员以全局的视角来审查相关作业的运行情况以及各项指标,及时做出错误诊断并进行相应处理。
相比而言,计数器方式比日志更易于分析。
内置计数器:相比而言,计数器方式比日志更易于分析。
(1)Hadoop内置的计数器,主要用来记录作业的执行情况
(2)内置计数器包括如下:
—MapReduce框架计数器(Map-Reduce Framework)
—文件系统计数器(File System Counters)
—作业计数器(Job Counters)
—文件输入格式计数器(File Output Format Counters)
—文件输出格式计数器(File Input Format Counters)
—Shuffle 错误计数器(Shuffle Errors)
(3)计数器由相关的task进行维护,定期传递给tasktracker,再由tasktracker传给jobtracker;
(4)最终的作业计数器实际上是由jobtracker维护,所以计数器可以被全局汇总,同时也不必在整个网络中传递。
(5)只有当一个作业执行成功后,最终的计数器的值才是完整可靠的;
(2)内置计数器包括如下:
—MapReduce框架计数器(Map-Reduce Framework)
—文件系统计数器(File System Counters)
—作业计数器(Job Counters)
—文件输入格式计数器(File Output Format Counters)
—文件输出格式计数器(File Input Format Counters)
—Shuffle 错误计数器(Shuffle Errors)
(3)计数器由相关的task进行维护,定期传递给tasktracker,再由tasktracker传给jobtracker;
(4)最终的作业计数器实际上是由jobtracker维护,所以计数器可以被全局汇总,同时也不必在整个网络中传递。
(5)只有当一个作业执行成功后,最终的计数器的值才是完整可靠的;
[Bash shell] 纯文本查看 复制代码
01内置计数器:0215/06/15 08:46:47 INFO mapreduce.Job: Job job_1434248323399_0004 completed successfully0315/06/15 08:46:47 INFO mapreduce.Job: Counters: 4904 File System Counters05 FILE: Number of bytes read=10306 FILE: Number of bytes written=31587307 FILE: Number of read operations=008 FILE: Number of large read operations=009 FILE: Number of write operations=010 HDFS: Number of bytes read=11611 HDFS: Number of bytes written=4012 HDFS: Number of read operations=913 HDFS: Number of large read operations=014 HDFS: Number of write operations=415 Job Counters16 Launched map tasks=117 Launched reduce tasks=218 Data-local map tasks=119 Total time spent by all maps in occupied slots (ms)=289320 Total time spent by all reduces in occupied slots (ms)=645321 Total time spent by all map tasks (ms)=289322 Total time spent by all reduce tasks (ms)=645323 Total vcore-seconds taken by all map tasks=289324 Total vcore-seconds taken by all reduce tasks=645325 Total megabyte-seconds taken by all map tasks=296243226 Total megabyte-seconds taken by all reduce tasks=660787227 Map-Reduce Framework28 Map input records=729 Map output records=730 Map output bytes=7731 Map output materialized bytes=10332 Input split bytes=9533 Combine input records=034 Combine output records=035 Reduce input groups=236 Reduce shuffle bytes=10337 Reduce input records=738 Reduce output records=239 Spilled Records=1440 Shuffled Maps =241 Failed Shuffles=042 Merged Map outputs=243 GC time elapsed (ms)=5944 CPU time spent (ms)=360045 Physical memory (bytes) snapshot=60601548846 Virtual memory (bytes) snapshot=267286528047 Total committed heap usage (bytes)=60299673648 Shuffle Errors49 BAD_ID=050 CONNECTION=051 IO_ERROR=052 WRONG_LENGTH=053 WRONG_MAP=054 WRONG_REDUCE=055 56 BAD_ID=057 CONNECTION=058 IO_ERROR=059 WRONG_LENGTH=060 WRONG_MAP=061 WRONG_REDUCE=062 File Input Format Counters63 Bytes Read=2164 File Output Format Counters65 Bytes Written=40计数器使用:
1、Web UI进行查看
(注:要启动历史服务器)
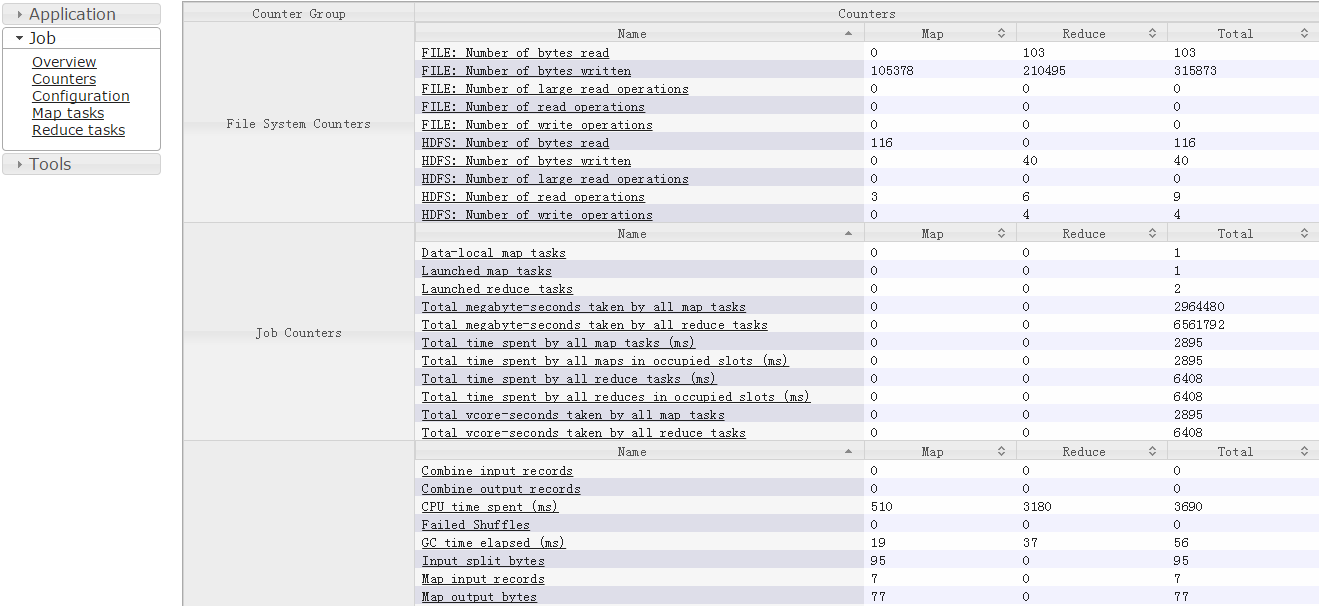
(注:要启动历史服务器)
2、命令行方式:
hadoop job -counter(Hadoop2.x无效)
hadoop job -counter(Hadoop2.x无效)
3、使用Hadoop API
通过job.getCounters()得到Counters,而后调用counters.findCounter()方法去得到计数器对象;查看最终的计数器的值需要等作业完成之后。
自定义计数器及实例:通过job.getCounters()得到Counters,而后调用counters.findCounter()方法去得到计数器对象;查看最终的计数器的值需要等作业完成之后。
MapReduce允许用户自定义计数器,计数器是一个全局变量,计数器有组的概念,可以用Java的枚举类型或者用字符串来定义方法;
[Java] 纯文本查看 复制代码
01package org.apache.hadoop.mapreduce;02public interface TaskAttemptContext extends JobContext, Progressable {03 //Get the {@link Counter} for the given04 //<code>counterName</code>.05 public Counter getCounter(Enum<?> counterName);06 07 //Get the {@link Counter} for the given08 //<code>groupName</code> and <code>counterName</code>.09 public Counter getCounter(String groupName, String counterName);10}字符串方式(动态计数器)比枚举类型要更加灵活,可以动态在一个组下面添加多个计数器;在旧API中使用Reporter,而新API用context.getCounter(groupName,counterName)来获取计数器配置并设置;然后让计数器递增。
[Java] 纯文本查看 复制代码
01package org.apache.hadoop.mapreduce;02/**03 * A named counter that tracks the progress of a map/reduce job.04 * <p><code>Counters</code> represent global counters, defined either by the05 * Map-Reduce framework or applications. Each <code>Counter</code> is named by06 * an {@link Enum} and has a long for the value.</p>07 * <p><code>Counters</code> are bunched into Groups, each comprising of08 * counters from a particular <code>Enum</code> class.09 */10public interface Counter extends Writable {11 /**12 * Increment this counter by the given value13 * @param incr the value to increase this counter by14 */15 void increment(long incr);16}自定义计数器实例
统计词汇行中词汇数超过2个或少于2个的行数:
输入数据文件counter
统计词汇行中词汇数超过2个或少于2个的行数:
输入数据文件counter
[Bash shell] 纯文本查看 复制代码
01[root@liguodong file]# vi counter02[root@liguodong file]# hdfs dfs -put counter /counter03[root@liguodong file]# hdfs dfs -cat /counter04hello world05hello hadoop06hi baby07hello 4325 778599308java hadoop09come[Java] 纯文本查看 复制代码
01package MyCounter;02 03import java.io.IOException;04import java.net.URI;05import java.net.URISyntaxException;06 07import org.apache.hadoop.conf.Configuration;08import org.apache.hadoop.fs.FileSystem;09import org.apache.hadoop.fs.Path;10import org.apache.hadoop.io.IntWritable;11import org.apache.hadoop.io.LongWritable;12import org.apache.hadoop.io.Text;13import org.apache.hadoop.mapreduce.Job;14import org.apache.hadoop.mapreduce.Mapper;15import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;16import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;17 18import MyPartitioner.MyPartitioner;19import MyPartitioner.MyPartitioner.DefPartitioner;20import MyPartitioner.MyPartitioner.MyMapper;21import MyPartitioner.MyPartitioner.MyReducer;22 23public class MyCounter {24 private final static String INPUT_PATH = "hdfs://liguodong:8020/counter";25 private final static String OUTPUT_PATH = "hdfs://liguodong:8020/outputcounter";26 public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text>27 {28 @Override29 protected void map(LongWritable key, Text value, Context context)30 throws IOException, InterruptedException31 { 32 String[] val = value.toString().split("\\s+");33 if(val.length<2){34 context.getCounter("ErrorCounter","below_2").increment(1);35 }else if(val.length>2){36 context.getCounter("ErrorCounter", "above_2").increment(1);37 }38 context.write(key, value);39 }40 }41 42 public static void main(String[] args) throws IllegalArgumentException, IOException,43 URISyntaxException, ClassNotFoundException, InterruptedException {44 Configuration conf = new Configuration();45 final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH),conf);46 if(fileSystem.exists(new Path(OUTPUT_PATH)))47 {48 fileSystem.delete(new Path(OUTPUT_PATH),true);49 }50 Job job = Job.getInstance(conf, "define counter");51 52 job.setJarByClass(MyPartitioner.class);53 54 FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); 55 job.setMapperClass(MyMapper.class);56 57 job.setNumReduceTasks(0);58 59 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); 60 //提交作业61 System.exit(job.waitForCompletion(true) ? 0 : 1); 62 }63}[Bash shell] 纯文本查看 复制代码
01运行结果:02[main] INFO org.apache.hadoop.mapreduce.Job - Counters: 2503 File System Counters04 FILE: Number of bytes read=14805 FILE: Number of bytes written=18783406 FILE: Number of read operations=007 FILE: Number of large read operations=008 FILE: Number of write operations=009 HDFS: Number of bytes read=6910 HDFS: Number of bytes written=8611 HDFS: Number of read operations=812 HDFS: Number of large read operations=013 HDFS: Number of write operations=314 Map-Reduce Framework15 Map input records=616 Map output records=617 Input split bytes=9418 Spilled Records=019 Failed Shuffles=020 Merged Map outputs=021 GC time elapsed (ms)=1222 CPU time spent (ms)=023 Physical memory (bytes) snapshot=024 Virtual memory (bytes) snapshot=025 Total committed heap usage (bytes)=1625292826 ErrorCounter27 above_2=128 below_2=129 File Input Format Counters30 Bytes Read=6931 File Output Format Counters32 Bytes Written=86 0 0
- MapReduce之计数器及实例
- MapReduce之计数器及实例
- MapReduce之计数器
- MapReduce计数器
- MapReduce计数器
- MapReduce计数器
- MapReduce计数器
- MapReduce 计数器
- MapReduce计数器
- MapReduce计数器
- MapReduce排序及实例
- MapReduce 简介及实例
- MapReduce之Partitioner组件源码解析及实例
- MapReduce之RecordReader组件源码解析及实例
- hadoop之mapreduce实例
- MapReduce实例之PageRank
- Hadoop MapReduce原理及实例
- Hadoop MapReduce原理及实例
- Mac OS Create case-sensitive build environment
- 如何在C++中调用C程序?
- Unity与web交互
- iOS中手写UITableViewCell的实现与逻辑(cell固定高度展现)
- ArcGIS教程:Iso 聚类非监督分类
- MapReduce之计数器及实例
- Hive-hive.groupby.skewindata配置相关问题调研
- 回溯算法的一些案例分析(c代码实现)
- C#设计模式学习笔记-单例模式
- 初学者很实用:DAO,Service,Action 三者的含义
- TCP协议中的三次握手和四次挥手(图解)
- poj 2553 The Bottom of a Graph 【有向图tarjan 求SCC 处理出度为0的SCC】
- #ifndef#define#endif的用法
- GCD 延时执行


