使用HBase EndPoint(coprocessor)进行计算
来源:互联网 发布:淘宝正品代购 编辑:程序博客网 时间:2024/06/07 17:18
1、统计总行数,理想的方式应该是怎样?
2、什么是Endpoint,怎样去实现它 ?
3、有哪几种方式去部署 ?
http://www.aboutyun.com/thread-7839-1-2.html
前言:
如果要统对hbase中的数据,进行某种统计,比如统计某个字段最大值,统计满足某种条件的记录数,统计各种记录特点,并按照记录特点分类(类似于sql的group by)~
常规的做法就是把hbase中整个表的数据scan出来,或者稍微环保一点,加一个filter,进行一些初步的过滤(对于rowcounter来说,就加了FirstKeyOnlyFilter),但是这么做来说还是会有很大的副作用,比如占用大量的网络带宽(当标级别到达千万级别,亿级别之后)尤为明显,RPC的量也是不容小觑的。
理想的方式应该是怎样?
拿row counter这个简单例子来说,我要统计总行数,如果每个region 告诉我他又多少行,然后把结果告诉我,我再将他们的结果汇总一下,不就行了么?
现在的问题是hbase没有提供这种接口,来统计每个region的行数,那是否我们可以自己来实现一个呢?
没错,正如本文标题所说,我们可以自己来实现一个Endpoint,然后让hbase加载起来,然后我们远程调用即可。
什么是Endpoint?
先弄清楚什么是hbase coprocessor
hbase有两种coprocessor,一种是Observer(观察者),类似于关系数据库的trigger(触发器),另外一种就是EndPoint,类似于关系数据库的存储过程。
观察者这里就多做介绍了,这里介绍Endpoint。
EndPoint是动态RPC插件的接口,它的实现代码被部署在服务器端(regionServer),从而能够通过HBase RPC调用。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个EndPoint,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。
怎么实现一个EndPoint
1. 定义一个新的protocol接口,必须继承CoprocessorProtocol.
2. 实现终端接口,继承抽象类BaseEndpointCoprocessor,改实现代码需要部署到
3. 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class<T> protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T,R> callable),这里的region是通过一个row来标示的,就是说,改row落到那个region,RPC就发给哪个region,对于start-end的,[start,end)范围内的region都会受到RPC调用。
如下图所示: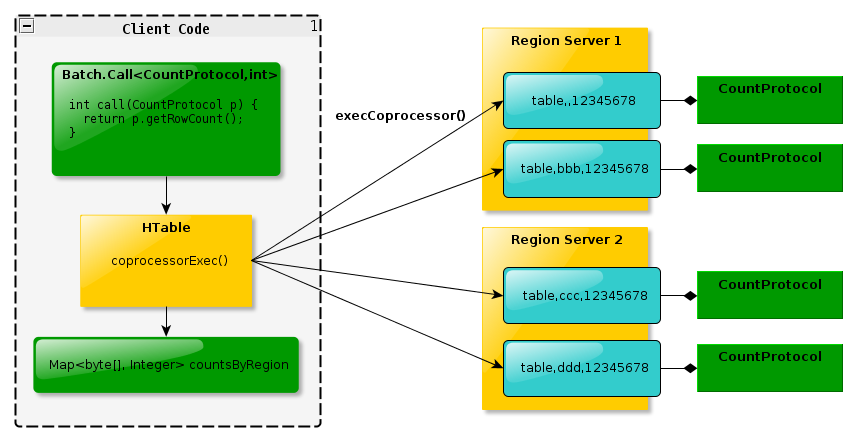
另外需要提醒的是:
protocol的返回类型,可以是基本类型。
如果是一个自定义的类型需要实现org.apache.hadoop.io.Writable接口。
关于详细的支持类型,请参考代码hbase源码:org.apache.hadoop.hbase.io.HbaseObjectWritable
怎么部署?
1. 通过hbase-site.xml增加
1、如果要配置多个,就用逗号(,)分割。
2、包含此类的jar必须位于hbase的classpath
3、这种coprocessor是作用于所有的表,如果你只想作用于部分表,请使用下面一种方式。
2、 通过shell方式
增加:
coprocessor格式为:
[FilePath]|ClassName|Priority|arguments
arguments: k=v[,k=v]+
其中FilePath是hdfs路径,例如/tmp/zhenhe/cp/zhenhe-1.0.jar
ClassNameEndPoint实现类的全名
Priority为,整数,框架会根据这个数据决定多个cp的执行顺序
Arguments,传给cp的参数
如果hbase的classpath包含改类,FilePath可以留空
卸载:
先describe “tableName‘,查看你要卸载的cp的编号
然后alter 't1', METHOD => 'table_att_unset', NAME=> 'coprocessor$3',coprocessor$3可变。
应用场景
这是一个最简单的例子,另外还有很多统计场景,可以用在这种方式实现,有如下好处:
节省网络带宽
减少RPC调用(scan的调用随着CacheSzie的变小而线性增加),减轻hbase压力
可以提高统计效率,那我之前写过的一个groupby类型的例子来说,大约可以提高50%以上的统计速度。
其他应用场景?
一个保存着用户信息的表,可以统计每个用户信息(counter job)
统计最大值,最小值,平均值,参考:官网
批量删除记录,批量删除某个时间戳的记录
- 使用HBase EndPoint(coprocessor)进行计算
- 使用HBase EndPoint(coprocessor)进行计算
- 使用HBase EndPoint(coprocessor)进行计算
- 使用HBase EndPoint(coprocessor)进行计算
- hbase 自定义 endpoint coprocessor
- HBase Coprocessor 之endpoint
- hbase 自定义 endpoint coprocessor
- Hbase Endpoint Coprocessor
- 在Hbase Endpoint Coprocessor中使用coprocessorProxy操作例子与问题解析
- hbase的coprocessor使用
- hbase的coprocessor使用
- hbase的coprocessor使用
- HBase: Coprocessor Endpoint :startkey和endkey的真正作用
- 使用HBase Coprocessor协处理器
- HBase CoProcessor介绍以及使用
- Hbase协处理器(Coprocessor)
- Hbase总结(八)Hbase中的Coprocessor
- Hbase总结(八)Hbase中的Coprocessor
- Dinic白书版本
- 帝国建站系统中的模板导入和导出的问题
- ios应用间通信和分享数据的机制
- 苹果开发 笔记(58)AFNetworking 类图
- POJ 2406 Power Strings kmp求循环结
- 使用HBase EndPoint(coprocessor)进行计算
- 自定义各种裁剪框、扫描框
- Android:Eclipse 安装Genymotion插件的时候出现 There are no categorized items
- jQuery基础学习一 简介、选择器、事件
- kafka集群编程指南
- osg 反走样学习
- 用Hadoop流实现mapreduce版推荐系统基于物品的协同过滤算法
- 利用mysql的binlog恢复数据
- 释义


