Amazon Dynamo架构分析(一)
来源:互联网 发布:美工刀片材料 编辑:程序博客网 时间:2024/04/29 06:30
Amazon Dynamo 是一个经典的分布式Key-Value 存储系统,具备去中心化,高可用性,高扩展性的特点,但是为了达到这个目标在很多场景中牺牲了一致性。Dynamo在Amazon中得到了成功的应用,能够跨数据中心部署于上万个结点上提供服务,它的设计思想也被后续的许多分布式系统借鉴。如近来火热的Cassandra,实际上就是基本照搬了Dynamo的P2P架构,同时融合了BigTable的数据模型及存储算法。
Dynamo组合使用了多种P2P技术,下面就从最基本的DHT(Distributed Hash Table)说起。
DHT,一致性哈希
Dynamo的存储模型就是一个简单的Key-Value映射表,如何把这个表分散到大量结点上呢,简单的做法可以是hash(key)%node_number,但是这样结点数目变动的时候就需要改变所有结点上的数据分布,这对上百万个结点,可能需要频繁添加删除结点,经常出现结点失效的系统来说,是无法承受的。因此,需要一种算法,使得在系统中结点变化只是,尽量减少数据迁移的开销,Dynamo采用的就是著名的一致性哈希算法,如图
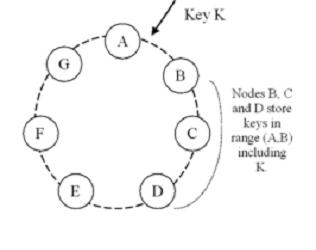
给定一个hash值空间,[0~2^32),假设分布在一个圆环上,对每个结点算出一个固定hash值,将结点置于环上,将Key K算出hash值,假设落在(A,B]之间,那么数据项<K,Value>就存在B开始的结点上。假定副本数为3,那么就存在B,C,D上。
假设结点X添加到图中A和B之间,那么根据三个副本存储方式,X将负责(F,G], (G,A], (A,X]范围的数据,在X加入前,B负责(F,G], (G,A], (A,B]; C负责(G,A], (A,B], (B,C]; D负责(A,B], (B,C], (C,D]。而在X加入后,B负责(G,A], (A,X], (X,B]; C负责(A,X], (X,B], (B,C]; D负责(X,B], (B,C], (C,D]),实际上等于B,C,D上的一部分数据转移到了X上,而删除结点,按相反的做法进行。
上述一致性哈希算法使得结点的变动只会影响邻近结点的数据分布,但是存在如下问题
1.无法适应结点的异质性,即不能根据结点能力调整负载
2.结点较少时易导致数据分配不均
因此,Dynamo引入了虚拟结点,每个物理结点分配到哈希环上多个位置(Token),这样即可根据机器性能给它分配较多或较少的Token,同时结点失效时,它的负载可以由多个物理结点共同分担,因为它在环上有多个位置。
引入虚拟结点后,多个副本存储时就要跳过指向同一物理结点的虚拟结点,所以Dynamo对每个虚拟结点可以获得一个Preference list,这个list包括健康的结点并且跳过重复的虚拟结点,同时考虑到结点的失效,list中结点个数大于副本数,这个问题后边再详细讨论。
现在的问题是如何实现路由到查询Key所在的结点,四大P2P路由协议,Chord,Tapestry,CAN,Pastry中,Chord协议就是一致性hash的实现。每个结点维护O(logN)大小的路由表,在O(logN)跳之内可以跳转到需要访问的结点。但是,Dynamo论文中提到,
Dynamo是为延时敏感应用程序设计的,需要至少99.9%的读取和写入操作必须在几百毫秒内完成,因此Dynamo设计为零跳(zero-hop)的DHT,每个节点维护足够的路由信息从而直接从本地将请求路由到相应的节点。那实际上,每台机就要维护系统中所有结点路由表项,当结点变动之时,路由表的变化将通过Gossip协议扩散。而对于广域网之上的P2P存储系统,有百万个结点以上的情况,每个结点存储全局路由表造成的网络开销过大,才不得不采用多跳DHT的设计,如OceanStore就采用了Tapestry协议。Dynamo的应用场景是部署于企业数据中心上,虽然可以跨数据中心,但也没有那么多的结点而且数据中心内有较高带宽。网络上不少文章都误认为Dynamo采用了Chord协议,以讹传讹,特此说明。
最终一致性模型
和Google BigTable的强一致性保证不同,Dynamo多个副本间不提供强一致性保证。假设副本数为N,Dynamo允许配置读写副本数R/W调整性能。每次同时向所有副本发起读/写请求,直到R个读/W个写成功,就向客户端返回数据。有一个流传很广的误区,R+W>N就可以保证强一致性,这是严重错误的。结点的失效可以轻易的破坏掉一致性,这个问题在文章 Dynamo:a flawed architecture 中讨论到,关于这一点举个例子:
N=3,R=W=2,
假设某数据三个副本分别存在node1,node2,node3中
第一次更新:node1失效,成功更新node2,node3,返回
第二次更新:node3失效,成功更新node1,node2,返回
这时候node2才是正确数据,node1和node3都只是部分更新
此时node2失效,发生读请求,读到node1和node3数据,返回
这时候读到的两个版本都只是部分更新,而且还有版本冲突的情况,只能依赖下述的用户自定义reconciliation解决。
关键在于Dynamo中,结点失效离开quorum组,随后又加入时,数据同步必须在后台异步进行(使用Merkle Tree,后边详述),数据未同步完时仍然当做正常结点提供服务。
最终一致性只是保证在没有更新操作的情况下所有副本在有限时间内可以同步到最新版本。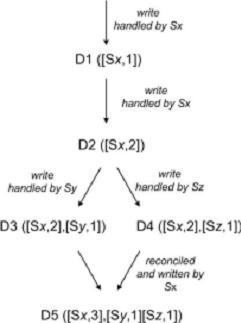
Dynamo使用了vector clock算法来进行数据版本控制。如上图所示,数据D1存储于Sx结点,Sx修改D1得到D2[Sx,2],然后D2复制到Sy和Sz结点,Sy和Sz分别修改为D3和D4,同时记录下修改历史(即一个vector clock列表,表项为<结点,版本号>),D3为([Sx,2],[Sy,1]) D4为([Sx,2],[Sz,1]),最后需要同步D3和D4时,发现修改历史有冲突,那么只能交由用户自定义合并方式,这就是”Semantic Reconcile“,若修改历史一个能包含另一个,如D3修改历史包含D2,同步D3和D2时将D2更新为D3就可以了,这就是”Syntax Reconcile”。这就是vector clock算法,通过vector clock列表判断版本的因果关系,若不存在因果关系,如D3和D4,就需要用户自定义合并方式。
既然有版本冲突的问题,冲突版本的合并就只能交给上层应用来做,每次读操作Dynamo将返回读到的所有版本,若上层应用无法解决合并,那就只能选择一个最新版本,从而丢失一部分数据,Dynamo论文只举了购物车的例子,每个值为一个购物车物品集合,每次更新可以往购物车添加,删除物品,冲突时合并购物车取并集。这样添加到购物车的操作不会出问题,但是可能会导致删除的物品重新出现。
既然有了版本冲突问题,这个存储系统适用的应用场景似乎大大减少了,Amazon CTO Werner Vogels在Twitter上说, its only use is storing hundreds of millions of shopping carts ,也不知是真是假。
-----------------------
PS:
关于版本控制的问题,另一个类似的存储系统Cassandra处理方式是:
由客户端生成value的timestamp(cassandra中引入了Column,timestamp实际上以row中的column为粒度),这样就需要客户端的时钟同步。而且Cassandra也没有Dynamo这种合并冲突Value的机制,那么就是timestamp最新的覆盖掉旧的,因此Cassandra连上述购物车数据更新丢失的问题都无法解决。
PS2:
如果分布式存储中副本只有一份,就没有一致性的问题,上述更新丢失问题即可通过乐观锁的方式来实现。如memcached中的Check and Set协议,亦即“乐观锁”,每次更新某个数据同时要附带一个cas值(之前读回来的),memcached比对这个cas值与当前存储数据的cas值是否相等,如果相等就让新的数据覆盖老的数据,然后cas值加1,如果不相等就认为更新失败。
PS3:
题外话,Memcached用的是客户端hash取模来分布数据,最简单的一种方式,是不是很挫啊,不过对于缓存也够用了 。
。
-----------------------
先写到这里,要实现Dynamo还需要解决大量的问题,如结点失效的处理,故障检测与传播,跨数据中心带来的问题,这些都留到下一篇文章讨论。总体感觉,Dynamo是一个工程实践的产物,远不及OceanStore这种学术产品的严谨设计,对于许多问题的解决也是采取鸵鸟政策,因此,后续的讨论将引出越来越多的问题,Dynamo:a flawed architecture 中尖锐的指出了Dynamo的不少缺陷,大家可以研究一下。
- Amazon Dynamo架构分析(一)
- Amazon Dynamo架构分析(一)
- Amazon Dynamo架构分析(一)
- Amazon 的 Dynamo 架构
- Amazon 的 Dynamo 架构
- Amazon 的 Dynamo 架构
- Amazon Dynamo系统架构
- Amazon 的 Dynamo 架构
- Amazon Dynamo系统架构
- Amazon Dynamo系统架构
- Amazon Dynamo
- Amazon Dynamo
- Amazon的Dynamo研究
- Amazon Dynamo论文学习
- Amazon Dynamo论文中文版
- Amazon Dynamo的相关材料
- Amazon Dynamo论文解读 — Dynamo数据划分算法
- Amazon Dynamo论文解读 — Dynamo数据划分算法
- CRLF Injection漏洞的利用与实例分析
- Deep Learning 优化方法总结
- C++基类与派生类的转换
- Android 中的SparseArray
- 千万并发的秘密-内核是问题的根本
- Amazon Dynamo架构分析(一)
- android 令人烦心的魅族Smart Bar
- Linux信号通讯编程
- android增量升级
- Java中==和equals的区别
- 从一道笔试题谈算法优化
- POJ 1659.Frogs' Neighborhood(Havel-Hakimi算法应用)
- Android开发环境搭建
- popen()


