大数据平台任务调度与监控系统
来源:互联网 发布:加入淘宝教育 编辑:程序博客网 时间:2024/05/16 14:44
背景
大数据平台技术框架支持的开发语言多种多样,开发人员的背景差异也很大,这就产生出很多不同类型的程序(任务)运行在大数据平台之上,如:MapReduce、Hive、Pig、Spark、Java、Shell、Python等。
这些任务需要不同的运行环境,并且除了定时运行,各种类型之间的任务存在依赖关系,一张简单的任务依赖图如下:
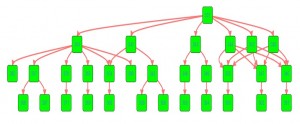
任务调度依赖图
目前各业务的数据任务基本都是靠Crontab定时调度,各个任务之间的依赖仅靠简单的串行来实现。
这样做的问题:
- 很容易造成前面的任务未结束或者失败,后面的任务也运行起来,最终跑出错误的分析结果;
- 任务不能并发执行,增加任务执行的整体时间窗口;
- 任务管理和维护很不方便,不好统计任务的执行时间及运行日志;
- 缺乏及时有效的告警;
SkyNet调度监控系统,正是为了解决以上问题。
系统架构
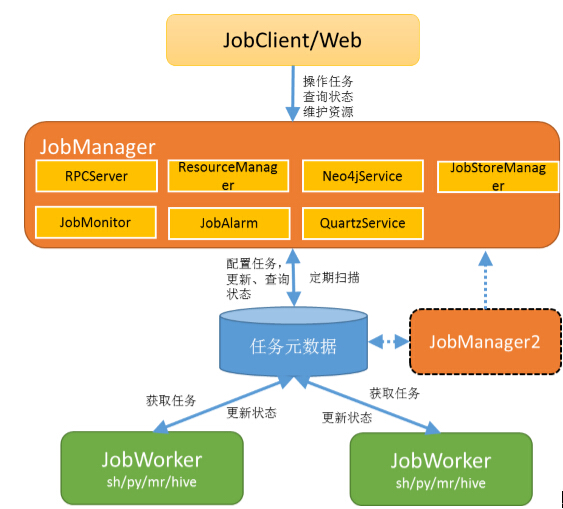
大数据任务调度
名词解释
SkyNet任务调度监控系统的名称。Job/任务一个程序运行单元,比如,一个MapReduce程序、一个Shell脚本等。业务日期每个程序运行所处理的数据日期。JobInstance/任务实例一次任务运行实例,因为一个任务在同一业务日期可能会运行多次。资源任务运行的节点(主机)DataHub数据交换机,用于异构数据源时间的数据交换。系统模块
- JobManager:SkyNet的Master,提供RPC服务,接收并处理JobClient/Web提交的所有操作;与元数据通讯,维护Job元数据;负责任务的统一配置维护、触发、调度、监控
- JobMonitor: 监控正在运行的Job状态、监控任务池、监控等待运行的Job;
- JobWorker:SkyNet的Slave,从任务池中获取Job、负责启动并收集Job的执行状态,维护至元数据库;
- JobClient/Web:SkyNet客户端类,前端界面提供给用户,用作任务的配置、管理、监控等;
- 任务元数据:目前使用Mysql,保存Job的配置、依赖关系、运行历史、资源配置、告警配置等;
系统特性
- 分布式架构:容量和负载能力(JobWorker)可线性扩充,并可以跨外网部署(只需能访问元数据库即可);
- 高可用性:拥有主备Master,一旦主Master异常,备Master会接替主Master提供服务(后期实现);
- 高容错性:Master重新启动后,会将之前未完成的任务重新调度运行;
- 完善易用的Web用户界面:用于用户配置、提交、查询、监控任务及任务的依赖关系;
- 支持任意类型的任务:除了Hadoop生态圈的MapReduce、Hive、Pig等,还支持其他任何语言开发的任务,如Java、Shell、Python、Perl、Spark等;
- 完整的日志记录:收集并记录任务运行过程中产生的标准输出和标准错误,提供Http访问,用户可通过访问任务对应的日志Url来方便的访问任务运行日志;
- 任务之间的灵活依赖:可将任意一个任务作为自己的父任务进行依赖触发;
- 灵活多样的告警规则:除了失败告警,也支持任务超时未完成、任务超时未开始等告警规则;
页面展示
DashBoard:显示平台任务总体概况,资源总体概况
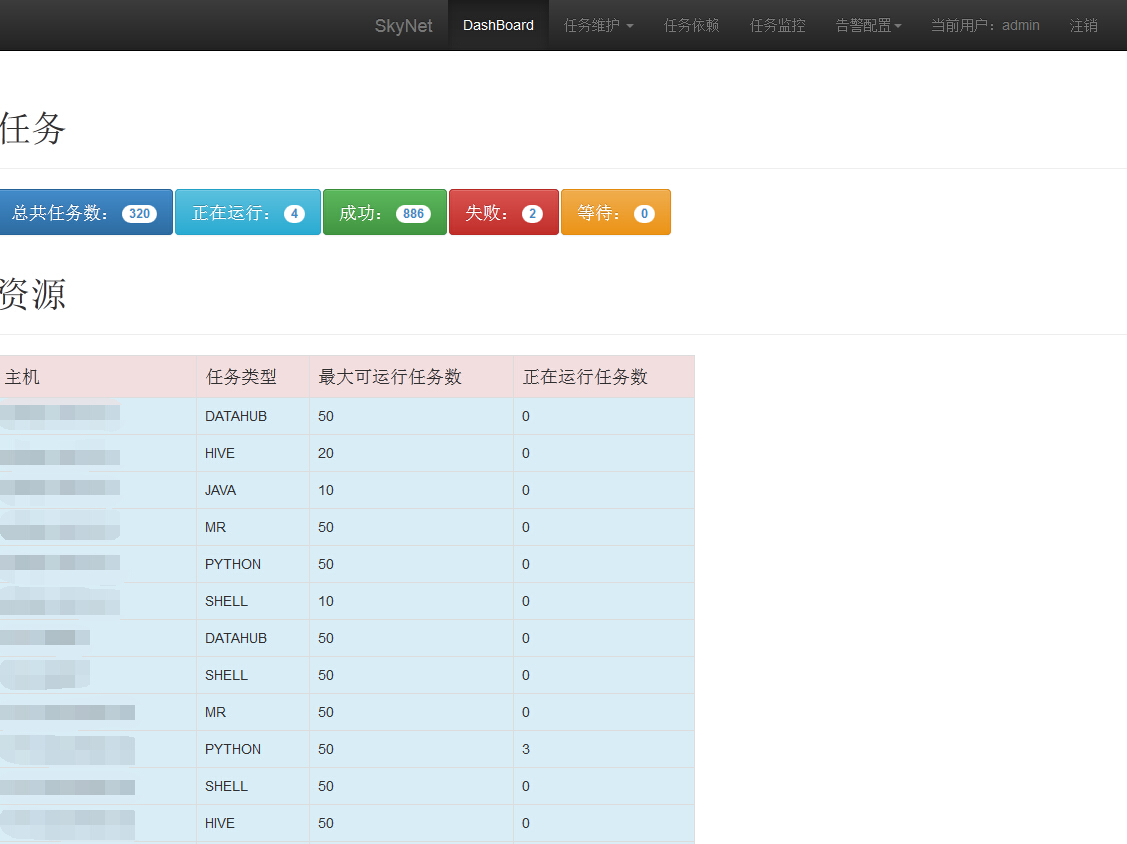
大数据任务调度
任务查询和维护:
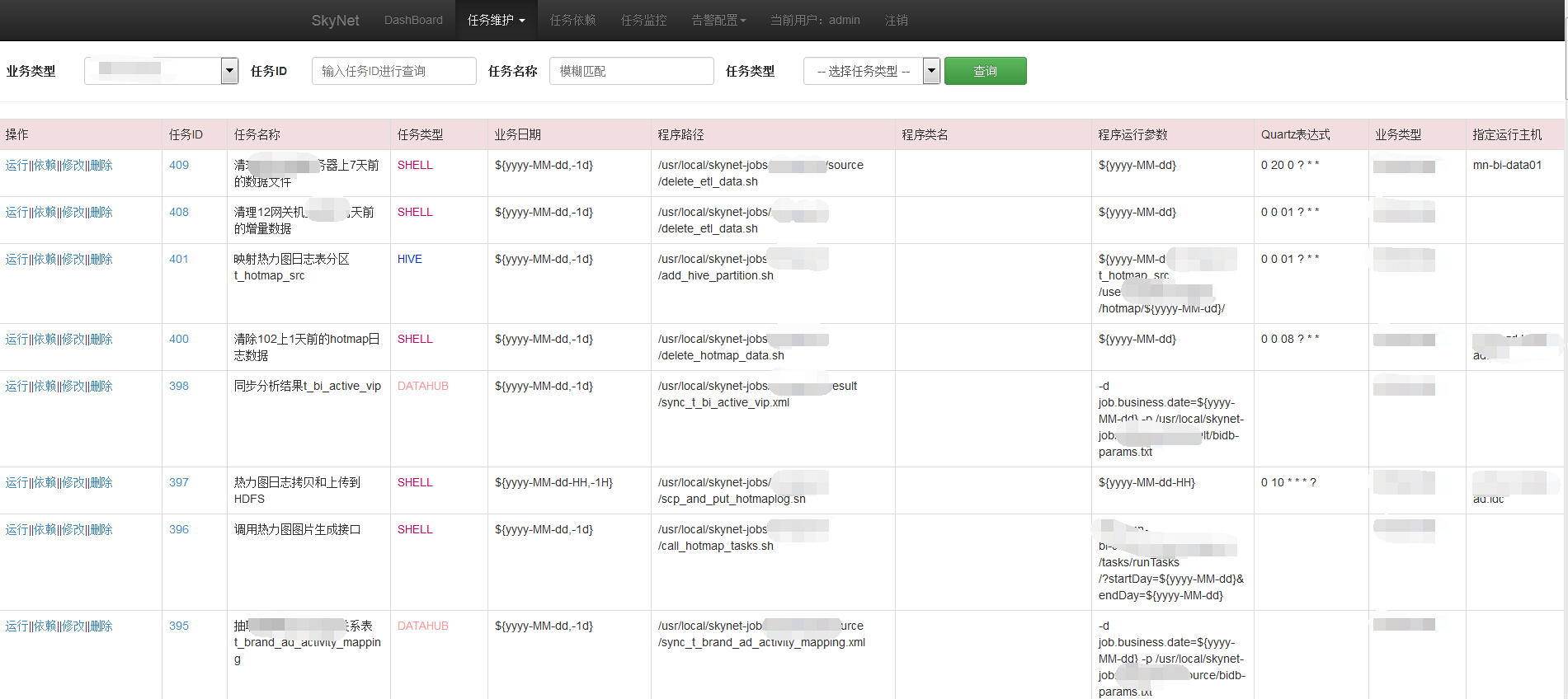
大数据任务调度
添加任务:
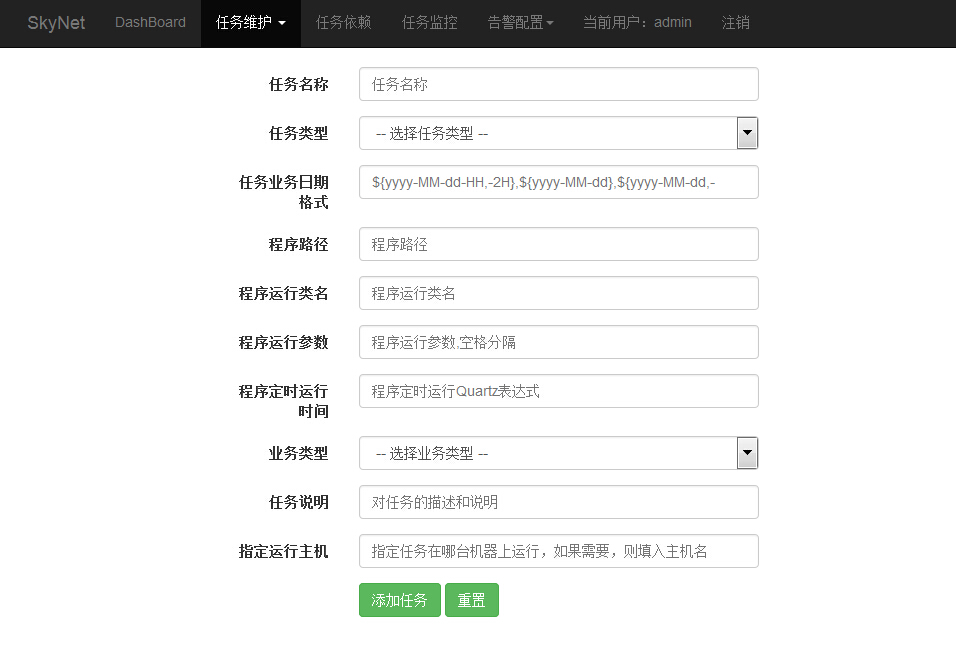
大数据任务调度
查看任务依赖关系及运行状态:
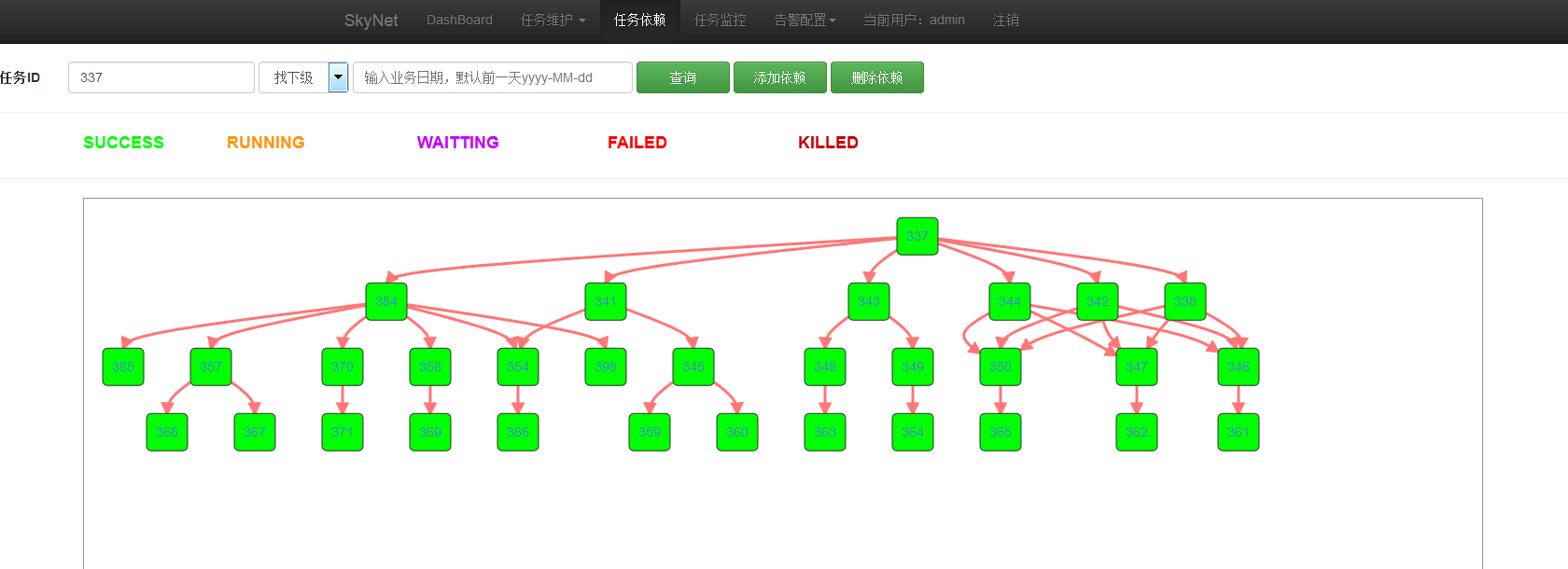
大数据任务调度
查看任务运行状态及运行日志:
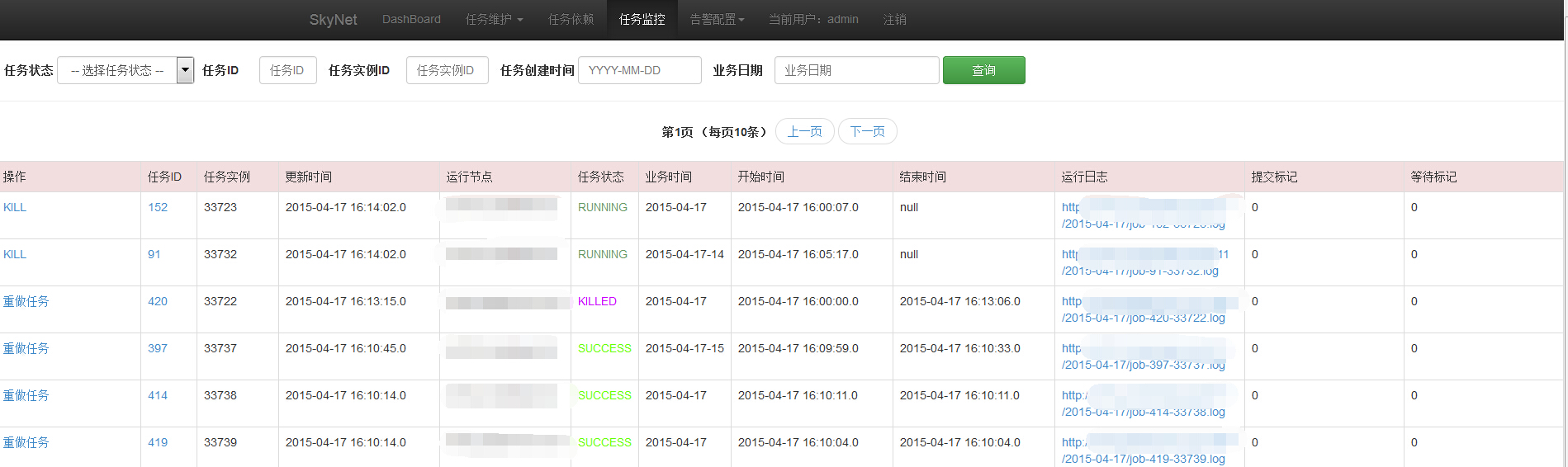
大数据任务调度
转载请注明:lxw的大数据田地 » 大数据平台任务调度与监控系统
0 0
- 大数据平台任务调度与监控系统
- 数据平台任务与调度设计
- 腾讯大数据之新一代资源管理与调度平台
- 大数据平台监控指标整理
- 04-天亮大数据系列教程之分布式资源管理与任务调度框架Yarn
- 数据平台调度系统的设计
- 大数据平台系统概览
- 大数据平台监控(二):Ganglia与Nagios的整合
- 大数据平台监控(二):Ganglia与Nagios的整合
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
- 分布式任务队列与任务调度系统Celery入门
- 分布式系统大数据量计算抢占式任务调度
- 大数据监控系统相关设计开发
- SOC系统任务调度
- zigbee 任务调度系统
- 分布式任务调度平台Antares
- 数据平台作业调度系统详解-理论篇
- 数据平台作业调度系统详解-实践篇
- POJ 1384 && HDU 1114 Piggy-Bank(完全背包问题)
- 16 3Sum Closest
- AJAX POST&跨域 解决方案 - CORS
- 浅谈算法和数据结构: 十一 哈希表 http://blog.jobbole.com/79261/
- Android XML属性介绍
- 大数据平台任务调度与监控系统
- LeetCode之Summary Ranges
- POJ1511 Invitation Cards(SPFA+逆图)
- C++中指针和引用的区别
- VS2010 C++ 学习笔记(六) this指针 const 指针 引用
- 如何使用JVisualVM进行性能分析
- JAVA的面向对象编程--------课堂笔记
- 玩玩负载均衡---在window与linux下配置nginx
- C++中的函数指针和函数对象总结


