【scikit-learn】scikit-learn的线性回归模型
来源:互联网 发布:到期收益率 知乎 编辑:程序博客网 时间:2024/05/22 13:29
【scikit-learn】scikit-learn的线性回归模型

来自 http://blog.csdn.net/jasonding1354/article/details/46340729
内容概要
- 如何使用pandas读入数据
- 如何使用seaborn进行数据的可视化
- scikit-learn的线性回归模型和使用方法
- 线性回归模型的评估测度
- 特征选择的方法
作为有监督学习,分类问题是预测类别结果,而回归问题是预测一个连续的结果。
1. 使用pandas来读取数据
Pandas是一个用于数据探索、数据处理、数据分析的Python库
import pandas as pd# read csv file directly from a URL and save the resultsdata = pd.read_csv('http://www-bcf.usc.edu/~gareth/ISL/Advertising.csv', index_col=0)# display the first 5 rowsdata.head()上面显示的结果类似一个电子表格,这个结构称为Pandas的数据帧(data frame)。
pandas的两个主要数据结构:Series和DataFrame:
- Series类似于一维数组,它有一组数据以及一组与之相关的数据标签(即索引)组成。
- DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典。
# display the last 5 rowsdata.tail()# check the shape of the DataFrame(rows, colums)data.shape特征:
- TV:对于一个给定市场中单一产品,用于电视上的广告费用(以千为单位)
- Radio:在广播媒体上投资的广告费用
- Newspaper:用于报纸媒体的广告费用
响应:
- Sales:对应产品的销量
在这个案例中,我们通过不同的广告投入,预测产品销量。因为响应变量是一个连续的值,所以这个问题是一个回归问题。数据集一共有200个观测值,每一组观测对应一个市场的情况。
import seaborn as sns%matplotlib inline# visualize the relationship between the features and the response using scatterplotssns.pairplot(data, x_vars=['TV','Radio','Newspaper'], y_vars='Sales', size=7, aspect=0.8)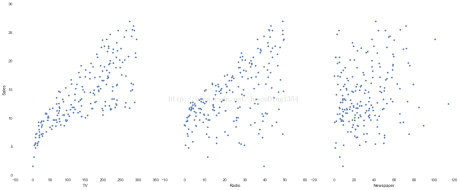
seaborn的pairplot函数绘制X的每一维度和对应Y的散点图。通过设置size和aspect参数来调节显示的大小和比例。可以从图中看出,TV特征和销量是有比较强的线性关系的,而Radio和Sales线性关系弱一些,Newspaper和Sales线性关系更弱。通过加入一个参数kind=’reg’,seaborn可以添加一条最佳拟合直线和95%的置信带。
sns.pairplot(data, x_vars=['TV','Radio','Newspaper'], y_vars='Sales', size=7, aspect=0.8, kind='reg')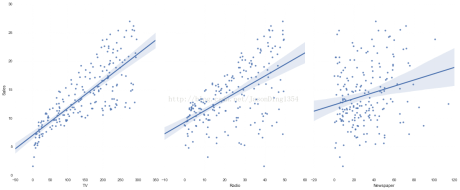
2. 线性回归模型
优点:快速;没有调节参数;可轻易解释;可理解
缺点:相比其他复杂一些的模型,其预测准确率不是太高,因为它假设特征和响应之间存在确定的线性关系,这种假设对于非线性的关系,线性回归模型显然不能很好的对这种数据建模。
线性模型表达式: y=β0+β1x1+β2x2+...+βnxn 其中
- y是响应
- β0是截距
- β1是x1的系数,以此类推
在这个案例中: y=β0+β1∗TV+β2∗Radio+...+βn∗Newspaper
(1)使用pandas来构建X和y
- scikit-learn要求X是一个特征矩阵,y是一个NumPy向量
- pandas构建在NumPy之上
- 因此,X可以是pandas的DataFrame,y可以是pandas的Series,scikit-learn可以理解这种结构
# create a python list of feature namesfeature_cols = ['TV', 'Radio', 'Newspaper']# use the list to select a subset of the original DataFrameX = data[feature_cols]# equivalent command to do this in one lineX = data[['TV', 'Radio', 'Newspaper']]# print the first 5 rowsX.head()# check the type and shape of Xprint type(X)print X.shape# select a Series from the DataFramey = data['Sales']# equivalent command that works if there are no spaces in the column namey = data.Sales# print the first 5 valuesy.head()print type(y)print y.shape(2)构造训练集和测试集
from sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)# default split is 75% for training and 25% for testingprint X_train.shapeprint y_train.shapeprint X_test.shapeprint y_test.shape(3)Scikit-learn的线性回归
from sklearn.linear_model import LinearRegressionlinreg = LinearRegression()linreg.fit(X_train, y_train)print linreg.intercept_print linreg.coef_# pair the feature names with the coefficientszip(feature_cols, linreg.coef_)y=2.88+0.0466∗TV+0.179∗Radio+0.00345∗Newspaper
如何解释各个特征对应的系数的意义?
- 对于给定了Radio和Newspaper的广告投入,如果在TV广告上每多投入1个单位,对应销量将增加0.0466个单位
- 更明确一点,加入其它两个媒体投入固定,在TV广告上没增加1000美元(因为单位是1000美元),销量将增加46.6(因为单位是1000)
(4)预测
y_pred = linreg.predict(X_test)3. 回归问题的评价测度
对于分类问题,评价测度是准确率,但这种方法不适用于回归问题。我们使用针对连续数值的评价测度(evaluation metrics)。
下面介绍三种常用的针对回归问题的评价测度
# define true and predicted response valuestrue = [100, 50, 30, 20]pred = [90, 50, 50, 30](1)平均绝对误差(Mean Absolute Error, MAE)
1n∑ni=1|yi−yi^|
(2)均方误差(Mean Squared Error, MSE)
1n∑ni=1(yi−yi^)2
(3)均方根误差(Root Mean Squared Error, RMSE)
1n∑ni=1(yi−yi^)2−−−−−−−−−−−−−√
from sklearn import metricsimport numpy as np# calculate MAE by handprint "MAE by hand:",(10 + 0 + 20 + 10)/4.# calculate MAE using scikit-learnprint "MAE:",metrics.mean_absolute_error(true, pred)# calculate MSE by handprint "MSE by hand:",(10**2 + 0**2 + 20**2 + 10**2)/4.# calculate MSE using scikit-learnprint "MSE:",metrics.mean_squared_error(true, pred)# calculate RMSE by handprint "RMSE by hand:",np.sqrt((10**2 + 0**2 + 20**2 + 10**2)/4.)# calculate RMSE using scikit-learnprint "RMSE:",np.sqrt(metrics.mean_squared_error(true, pred))计算Sales预测的RMSE
print np.sqrt(metrics.mean_squared_error(y_test, y_pred))4. 特征选择
在之前展示的数据中,我们看到Newspaper和销量之间的线性关系比较弱,现在我们移除这个特征,看看线性回归预测的结果的RMSE如何?
feature_cols = ['TV', 'Radio']X = data[feature_cols]y = data.SalesX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)linreg.fit(X_train, y_train)y_pred = linreg.predict(X_test)print np.sqrt(metrics.mean_squared_error(y_test, y_pred))我们将Newspaper这个特征移除之后,得到RMSE变小了,说明Newspaper特征不适合作为预测销量的特征,于是,我们得到了新的模型。我们还可以通过不同的特征组合得到新的模型,看看最终的误差是如何的。
Related Posts
 scikit-learn的主要模块和基本使用
scikit-learn的主要模块和基本使用 数据挖掘系列(9)——BP神经网络算法与实践
数据挖掘系列(9)——BP神经网络算法与实践 K-means算法及文本聚类实践
K-means算法及文本聚类实践 数据挖掘系列(2)–关联规则FpGrowth算法
数据挖掘系列(2)–关联规则FpGrowth算法 如何创建用户画像
如何创建用户画像 如何进行网络数据挖掘
如何进行网络数据挖掘
 结构方程简介数据分析 数据分析 数据挖掘 朴素贝叶斯 机器学习 熵 用户画像 神经网络 线性回归 联合分析 聚类分析 自动保存 购物篮分析 资本运作 逻辑回归
结构方程简介数据分析 数据分析 数据挖掘 朴素贝叶斯 机器学习 熵 用户画像 神经网络 线性回归 联合分析 聚类分析 自动保存 购物篮分析 资本运作 逻辑回归
- 【scikit-learn】scikit-learn的线性回归模型
- 【scikit-learn】scikit-learn的线性回归模型
- 【scikit-learn】scikit-learn的线性回归模型
- scikit-learn : 线性回归
- scikit-learn : 线性回归模型性能评估
- scikit-learn的线性回归模型 利用pandas处理数据
- 线性回归-scikit-learn
- 线性回归之scikit-learn
- scikit-learn线性回归源码
- scikit-learn实现线性回归之LinearRegression模型
- scikit-learn实现线性回归之Lassolars模型
- scikit-learn广义线性模型之岭回归
- 使用scikit-learn做线性回归
- scikit-learn 线性回归算法库小结
- scikit-learn 线性回归算法库小结
- scikit-learn 线性回归算法库小结
- scikit-learn 实现简单的二维线性回归
- (转)(三)机器学习笔记之Scikit Learn的线性回归模型初探
- 如何遍历QML Item下的所有的children并显示它们的属性
- 第6章 中断与中断处理
- Merge k Sorted Lists
- Linux下暴力破解工具Hydra详解
- springSecurity源码分析——DelegatingFilterProxy类的作用
- 【scikit-learn】scikit-learn的线性回归模型
- SOAPUI系列08- SOAPUI 属性设置
- linux下定时任务(crontab)
- Android入门第一篇(介绍Android的基本内容)
- JSP或HTML的命名规范
- go-tour-zh离线安装
- javaSctrip4
- android 程序安装以后不要显示图标
- iOS 属性中strong,weak,assign,retain,copy等特性


