zookeeper+hadoop+hbase 之 hadoop
来源:互联网 发布:linux 禁止访问外网 编辑:程序博客网 时间:2024/05/22 05:23
1、hadoop集群部署介绍
1.1 环境说明
集群中包括3个节点:1个Master,2个Salve,节点之间局域网连接,可以相互ping通
Master.Hadoop
192.168.154.79
Salve1.Hadoop
192.168.153.64
Salve2.Hadoop
192.168.154.85
三个节点有一个相同的用户hadoop。1.2 网络配置
1)查看当前机器名称
用下面命令进行显示机器名称,如果跟规划的不一致,要按照下面进行修改。
hostname
上图中,用"hostname"查"Master"机器的名字为"Master.Hadoop",与我们预先规划的一致。
2)修改当前机器名称
假定我们发现我们的机器的主机名不是我们想要的,通过对"/etc/sysconfig/network"文件修改其中"HOSTNAME"后面的值,改成我们规划的名称。
这个"/etc/sysconfig/network"文件是定义hostname和是否利用网络的不接触网络设备的对系统全体定义的文件。
设定形式:设定值=值
"/etc/sysconfig/network"的设定项目如下:
NETWORKING 是否利用网络
GATEWAY 默认网关
IPGATEWAYDEV 默认网关的接口名
HOSTNAME 主机名
DOMAIN 域名
用下面命令进行修改当前机器的主机名(备注:修改系统文件一般用root用户)
vim /etc/sysconfig/network
1.3 配置host
vim /etc/hosts
192.168.154.79 Master.Hadoop mem1 master.hadoop
192.168.153.64 Slave1.Hadoop mem2 slave1.hadoop
192.168.154.85 Slave2.Hadoop mem3 slave2.hadoop
那么现在剩下的事儿就是在其余的Slave机器上进行相同的配置。然后进行测试。(备注:当设置SSH无密码验证后,可以"scp"进行复制,然后把原来的"hosts"文件执行覆盖即可。)
1.4 所需软件
下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/
Hadoop版本:hadoop-2.6.0.tar.gz
1.5 SSH无密码验证配置
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
1.5.1 安装和启动SSH协议
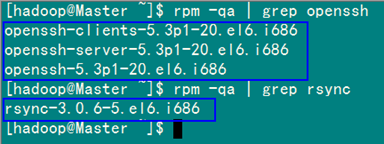
在"Hadoop集群(第1期)"安装CentOS6.0时,我们选择了一些基本安装包,所以我们需要两个服务:ssh和rsync已经安装了。可以通过下面命令查看结果显示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假设没有安装ssh和rsync,可以通过下面命令进行安装。
yum install ssh 安装SSH协议
yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
service sshd restart 启动服务
确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登。
1.5.2 配置Master 无密码登录所有Slave
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对
在Master节点上执行以下命令:
ssh-keygen –t rsa –P ''
这条命是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。
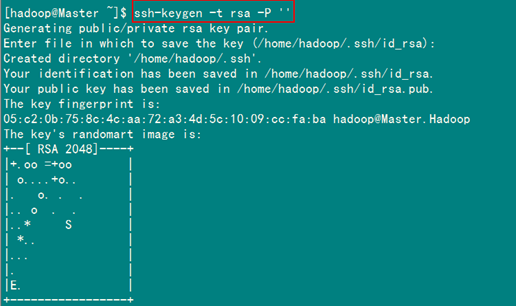
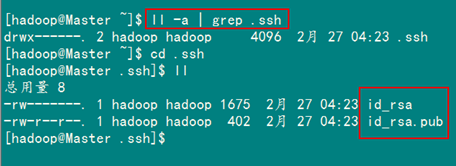
查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

在验证前,需要做两件事儿。第一件事儿是修改文件"authorized_keys"权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。
1)修改文件"authorized_keys"
chmod 600 ~/.ssh/authorized_keys
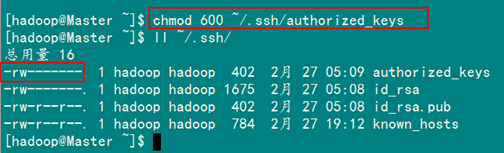
备注:如果不进行设置,在验证时,扔提示你输入密码,在这里花费了将近半天时间来查找原因。在网上查到了几篇不错的文章,把作为"Hadoop集群_第5期副刊_JDK和SSH无密码配置"来帮助额外学习之用。
2)设置SSH配置
用root用户登录服务器修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
设置完之后记得重启SSH服务,才能使刚才设置有效。
service sshd restart
退出root登录,使用hadoop普通用户验证是否成功。
ssh localhost
从上图中得知无密码登录本级已经设置完毕,接下来的事儿是把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:
scp ~/.ssh/id_rsa.pub hadoop@192.168.153.64:~/
上面的命令是复制文件"id_rsa.pub"到服务器IP为"192.168.153.64"的用户为"hadoop"的"/home/hadoop/"下面。
下面就针对IP为"192.168.153.64"的Slave1.Hadoop的节点进行配置。
1)把Master.Hadoop上的公钥复制到Slave1.Hadoop上
scp ~/.ssh/id_rsa.pub hadoop@193.168.153.64:~/
因为并没有建立起无密码连接,所以在连接时,仍然要提示输入输入Slave1.Hadoop服务器用户hadoop的密码。为了确保确实已经把文件传过去了,用SecureCRT登录Slave1.Hadoop:192.168.153.64服务器,查看"/home/hadoop/"下是否存在这个文件。

从上面得知我们已经成功把公钥复制过去了。
2)在"/home/hadoop/"下创建".ssh"文件夹
这一步并不是必须的,如果在Slave1.Hadoop的"/home/hadoop"已经存在就不需要创建了,因为我们之前并没有对Slave机器做过无密码登录配置,所以该文件是不存在的。用下面命令进行创建。(备注:用hadoop登录系统,如果不涉及系统文件修改,一般情况下都是用我们之前建立的普通用户hadoop进行执行命令。)
mkdir ~/.ssh
然后是修改文件夹".ssh"的用户权限,把他的权限修改为"700",用下面命令执行:
chmod 700 ~/.ssh
备注:如果不进行,即使你按照前面的操作设置了"authorized_keys"权限,并配置了"/etc/ssh/sshd_config",还重启了sshd服务,在Master能用"ssh localhost"进行无密码登录,但是对Slave1.Hadoop进行登录仍然需要输入密码,就是因为".ssh"文件夹的权限设置不对。这个文件夹".ssh"在配置SSH无密码登录时系统自动生成时,权限自动为"700",如果是自己手动创建,它的组权限和其他权限都有,这样就会导致RSA无密码远程登录失败。
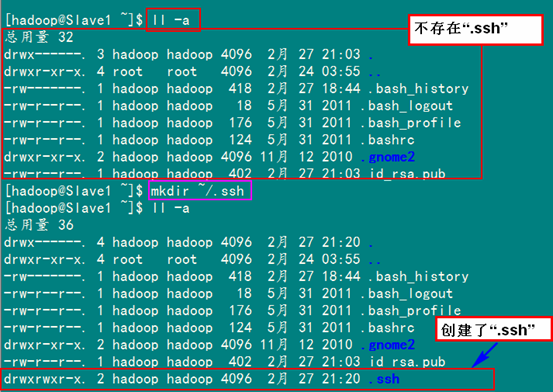

对比上面两张图,发现文件夹".ssh"权限已经变了。
3)追加到授权文件"authorized_keys"
到目前为止Master.Hadoop的公钥也有了,文件夹".ssh"也有了,且权限也修改了。这一步就是把Master.Hadoop的公钥追加到Slave1.Hadoop的授权文件"authorized_keys"中去。使用下面命令进行追加并修改"authorized_keys"文件权限:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys

4)用root用户修改"/etc/ssh/sshd_config"
具体步骤参考前面Master.Hadoop的"设置SSH配置",具体分为两步:第1是修改配置文件;第2是重启SSH服务。
5)用Master.Hadoop使用SSH无密码登录Slave1.Hadoop
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。
ssh 远程服务器IP
从上图我们主要3个地方,第1个就是SSH无密码登录命令,第2、3个就是登录前后"@"后面的机器名变了,由"Master"变为了"Slave1",这就说明我们已经成功实现了SSH无密码登录了。
最后记得把"/home/hadoop/"目录下的"id_rsa.pub"文件删除掉。
rm –r ~/id_rsa.pub
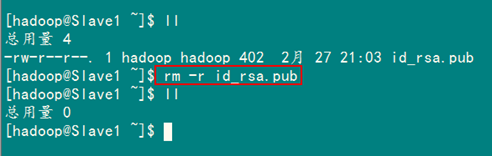
到此为止,我们经过前5步已经实现了从"Master.Hadoop"到"Slave1.Hadoop"SSH无密码登录,下面就是重复上面的步骤把剩余的两台(Slave2.Hadoop)Slave服务器进行配置。这样,我们就完成了"配置Master无密码登录所有的Slave服务器"。
1.6 配置所有Slave 无密码登录Master
和Master无密码登录所有Slave原理一样,就是把Slave的公钥追加到Master的".ssh"文件夹下的"authorized_keys"中,记得是追加(>>)。
为了说明情况,我们现在就以"Slave1.Hadoop"无密码登录"Master.Hadoop"为例,进行一遍操作,也算是巩固一下前面所学知识,剩余的"Slave2.Hadoop"和"Slave3.Hadoop"就按照这个示例进行就可以了。
首先创建"Slave1.Hadoop"自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中。用到的命令如下:
ssh-keygen –t rsa –P ''
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
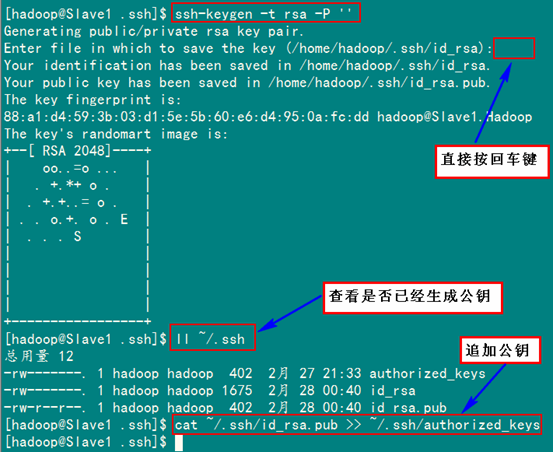
接着是用命令"scp"复制"Slave1.Hadoop"的公钥"id_rsa.pub"到"Master.Hadoop"的"/home/hadoop/"目录下,并追加到"Master.Hadoop"的"authorized_keys"中。
1)在"Slave1.Hadoop"服务器的操作
用到的命令如下:
scp ~/.ssh/id_rsa.pub hadoop@192.168.153.64:~/
2)在"Master.Hadoop"服务器的操作
用到的命令如下:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
然后删除掉刚才复制过来的"id_rsa.pub"文件。
最后是测试从"Slave1.Hadoop"到"Master.Hadoop"无密码登录。
scp ~/.ssh/id_rsa.pub hadoop@192.168.153.64:~/
从上面结果中可以看到已经成功实现了,再试下从"Master.Hadoop"到"Slave1.Hadoop"无密码登录。
至此"Master.Hadoop"与"Slave1.Hadoop"之间可以互相无密码登录了,剩下的就是按照上面的步骤把剩余的"Slave2.Hadoop与"Master.Hadoop"之间建立起无密码登录。这样,Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
1.7 java 环境安装
所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以"root"的身份进行。
编辑"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"内容。
1)编辑"/etc/profile"文件
vim /etc/profile

2)添加Java环境变量
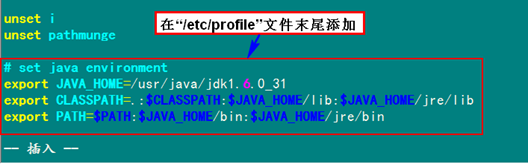
在"/etc/profile"文件的尾部添加以下内容:
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31/
export JRE_HOME=/usr/java/jdk1.6.0_31/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
或者
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
以上两种意思一样,那么我们就选择第2种来进行设置。
3)使配置生效
保存并退出,执行下面命令使其配置立即生效。
source /etc/profile

1.8 hadoop 集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以"root"的身份进行。
1.8.1 安装hadoop
首先用root 用户登录Master.Hadoop 机器,接着把hadoop-2.6.0.tar.gz 复制到 /usr 目录下面
cp /home/hadoop/hadoop-2.6.0.tar.gz /usr
cd /usr #进入"/usr"目录
tar –zxvf hadoop-2.6.0.tar.gz #解压"hadoop-2.6.0.tar.gz"安装包
mv hadoop-2.6.0 hadoop #将"hadoop-2.6.0"文件夹重命名"hadoop"
chown –R hadoop:hadoop hadoop #将文件夹"hadoop"读权限分配给hadoop用户
rm –rf hadoop-2.6.0.tar.gz #删除"hadoop-2.6.0.tar.gz"安装包
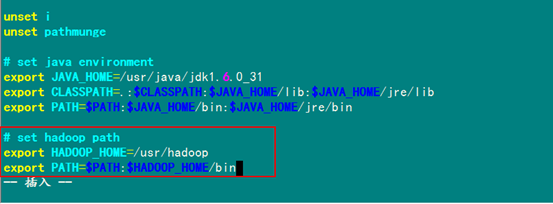
最后在"/usr/hadoop"下面创建tmp文件夹,把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效:
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
1)在"/usr/hadoop"创建"tmp"文件夹
mkdir /usr/hadoop/tmp

2)配置"/etc/profile"
vim /etc/profile

配置后的文件如下:
3)重启"/etc/profile"
source /etc/profile

1.8.2 配置hadoop
1)配置hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.6.0_25
2) 配置core-site.xml 文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.154.79:9000</value>
</property>
</configuration>
3) 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.154.79:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4) 配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>192.168.154.79:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.154.79:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.154.79:19888</value>
</property>
</configuration>
5) 配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.154.79</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.154.79:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.154.79:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.154.79:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.154.79:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.154.79:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
6) 配置slaves
192.168.153.64
192.168.154.85
7)scp ~/hadoop-2.6.0.tar.gz hadoop@服务器IP:~/
1.9 启动和验证
1.9.1 格式化Hdfs文件
bin/hadoop namenode -format
1.9.2 使用以下命令启动
./start-all.sh &
1.9.3 验证 jps命令
进入主节点jps 命令后的内容如下--红色部分
3717 NameNode
17267 Jps
31820 HMaster
4467 QuorumPeerMain
4060 ResourceManager
3908 SecondaryNameNode
进入数据节点jps命令后的内容如下--红色部分:
1550 Jps
32637 NodeManager
1326 HRegionServer
18056 QuorumPeerMain
32566 DataNode
- zookeeper+hadoop+hbase 之 hadoop
- zookeeper+hadoop+hbase 之 zookeeper
- zookeeper+hadoop+hbase 之 hbase
- Hadoop+Hbase+Zookeeper安装
- hadoop,zookeeper.hbase安装
- hadoop+zookeeper+hbase+hive
- Hadoop- Zookeeper-Hbase搭建
- hadoop+zookeeper+hbase安装
- Hadoop Core、HBase 、ZooKeeper
- zookeeper与hadoop、hbase
- hadoop+HBase+Zookeeper 安装
- hadoop Zookeeper hbase
- HADOOP+ZOOKEEPER+HBASE+HIVE
- Hadoop+hbase+zookeeper整合
- HADOOP+ZOOKEEPER+HBASE+HIVE
- Hadoop集群搭建之四 CentOS7+JDK+Hadoop+zookeeper+HBase
- hbase、zookeeper及hadoop部署
- Hadoop-HBase-Zookeeper安装记录
- Java问答:终极父类(上)
- makefile 中ALL 和 .PHONY的作用
- iOS开发 - iOS开发中证书失效的一些问题
- iOS的KVC编程示例
- hdu 2009 求数列的和
- zookeeper+hadoop+hbase 之 hadoop
- 离线保存数据
- 信号量0的解释
- Mac OS X 下安装 Ant
- android图片处理
- 关于MyBatis的缓存机制
- rsync同步常用命令
- 分享插件
- Auto Layout 使用心得(五)—— 根据文字、图片自动计算 UITableViewCell 高度


