分冶法之归并排序
来源:互联网 发布:汽车配件管理销售软件 编辑:程序博客网 时间:2024/06/07 04:03
1.分冶策越中的两种典型的划分案例
(1).黑盒划分策越:合并排序 逆序对问题
根据问题的规模对原问题进行划分,而不考虑划分对象的属性值,所以形象的称之为黑盒策越(就是说我们归并排序的时候,划分为,两个小模块的时候,并没有按照其值的属性进行划分,而只是简单的对于我们的数组内的大小进行区分)
(2)白盒策越:快速排序,最接近点对
根据划分对象的特定的属性值,把对象划分为若干个子集(白盒问题划分时,有的问题不可能出现解或者这些子问题可以忽视而无需求解,这类问题称为减冶策越,如二分,指数运算)
2.何为分冶思想?
就是将一个大规模的问题划分为子问题,然后分别求这些子问题的结果,得到子问题的结果,我们就可以得到原问题的结果,分冶并不是一种算法,而已求解问题的一种思路和策越,与分冶不可分割的就是递归,没有递归分冶也无法落地!
递归:
(1: 递归的边界 ,递归的关系式,递归的边界处理部分,递归的调用部分
如:n!
inf facorical(int n)
{
if(n==0)//边界
return 1;//边界的处理
return n*(n-1);//递归的调用部分
}
3.分冶的一般的执行过程
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
- //将有序数组a[]和b[]合并到c[]中
- void MemeryArray(int a[], int n, int b[], int m, int c[])
- {
- int i, j, k;
- i = j = k = 0;
- while (i < n && j < m)
- {
- if (a[i] < b[j])
- c[k++] = a[i++];
- else
- c[k++] = b[j++];
- }
- while (i < n)
- c[k++] = a[i++];
- while (j < m)
- c[k++] = b[j++];
- }
可以看出合并有序数列的效率是比较高的,可以达到O(n)。
解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
5.看哈我们的实际的处理过程

解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
- //将有二个有序数列a[first...mid]和a[mid...last]合并。
- void mergearray(int a[], int first, int mid, int last, int temp[])
- {
- int i = first, j = mid + 1;
- int m = mid, n = last;
- int k = 0;
- while (i <= m && j <= n)
- {
- if (a[i] <= a[j])
- temp[k++] = a[i++];
- else
- temp[k++] = a[j++];
- }
- while (i <= m)
- temp[k++] = a[i++];
- while (j <= n)
- temp[k++] = a[j++];
- for (i = 0; i < k; i++)
- a[first + i] = temp[i];
- }
- void mergesort(int a[], int first, int last, int temp[])
- {
- if (first < last) //划分为只有一个元素,最后在合并!其实非常简单的思路!
- {
- int mid = (first + last) / 2;
- mergesort(a, first, mid, temp); //左边有序
- mergesort(a, mid + 1, last, temp); //右边有序
- mergearray(a, first, mid, last, temp); //再将二个有序数列合并
- }
- }
归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的。
对20000个随机数据进行测试:
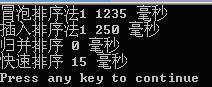
对50000个随机数据进行测试:
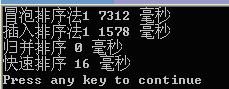
再对200000个随机数据进行测试:
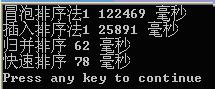
6.非递归的归并思路
归并排序的非递归实现如下,思想和递归正好相反,原来的递归过程是将待排序集合一分为二,直至排序集合就剩下一个元素位置,然后不断的合并两个排好序的数组。所以非递归思想为,将数组中的相邻元素两两配对。用merge函数将他们排序,构成n/2组长度为2的排序好的子数组段,然后再将他们排序成长度为4的子数组段,如此继续下去,直至整个数组排好序。
非递归(迭代,循环展开)--自底向上
- 分冶法之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序 之 归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- 排序之归并排序
- leetcode 202 Happy Number(难易度:Easy)
- 大四上week2-4(抽象类,接口,Object类,扑克牌案例 )
- IMX6Solo启动流程-Linux 内核启动 一
- DataGridView和ListView比较
- Eclipse中Tomcat插件的使用说明
- 分冶法之归并排序
- Asynchttpclient的使用及请求与响应封装
- hdu1505city game dp
- 凌凯短信Webservice接口报错解决办法
- system() 函数执行遇到 Cannot allocate memory
- 用cxf编写基于spring的webservice之上篇
- C++学习之如何理解*&,即指针的引用
- UE设置
- Android onMeasure()


