网络与并发
来源:互联网 发布:陕西广电网络吧 编辑:程序博客网 时间:2024/05/22 21:22
一、TCP和UDP程序的基本框架


主要API简介:
创建套接字SOCKET socket(int af, int type, int protocol);af:Adress Family,AF_INET表示ipv4网络协议type:SOCK_STREAM表示TCP,SOCK_DGRAM表示UDPprotocol:用来指定socket 所使用的传输协议编号,通常此参数不用管它,设为0即可返回值:SOCKET是一个整型,成功则返回表示此socket的文件描述符, 失败返回-1建立地址和套接字的联系int bind(SOCKET s, const struct sockaddr *name, int namelen);服务器端侦听客户端的请求int listen(SOCKET s, int backlog);backlog指定同时能处理的最大连接要求, 如果连接数目达此上限则client端将收到ECONNREFUSED的错误listen()并未开始接收连线, 只是设置socket 为listen 模式, 真正接收client 端连线的是accept()返回值:成功则返回0, 失败返回-1, 错误原因存于errno建立服务器/客户端的连接 (面向连接TCP) 客户端请求连接 int connect(SOCKET s, const struct sockaddr *name, int namelen);服务器端等待从编号为s的socket上接收客户连接请求 SOCKET accept(SOCKET s, struct sockaddr *addr, int *addrlen);返回一新TCP连接的文件描述符发送/接收数据 面向连接:send(sockid, buff, bufflen) recv() 面向无连接:sendto(sockid,buff,…,addrlen) recvfrom()释放套接字 close(sockid)accept是阻塞的。
recv和recvfrom,都有两种模式,阻塞和非阻塞,可以通过ioctl函数来设置。阻塞模式是一直等待直到有数据到达,非阻塞模式是立即返回,需要通过消息,异步事件等来查询完成状态。
参考
基于Socket的UDP和TCP编程介绍
socket API
二、对TCP连接并发的理解
socket描述符
Linux下执行 ulimit -n 输出 1024,说明对于一个进程而言最多只能打开1024个文件(所以select就做了1024的限制)。
在Linux下,socket描述符其实就是文件描述符,每一个tcp连接都要占一个文件描述符,它和硬盘文件及其它IO设备共享取值空间,因为0,1,2分别预留给了标准输入,标准输出和标准错误,因此socket描述符最小从3开始,若程序在访问socket的同时还会访问磁盘文件或其它IO设备,将会用掉一部分文件描述符,导致socket描述符不再连续,但所有打开的IO设备描述符加在一起,则严格表现为连续递增(这就是为什么select可以用连续的1024个比特来标识监控的连接)。
并发数量
系统用一个四元组来唯一标识一个TCP连接:{local ip, local port,remote ip,remote port}。
服务端监听某个端口,accept返回的新的TCP连接,这个新的tcp连接使用的仍然是监听的那个端口。再来一个新的客户端,服务器上根本不需要再开一个端口,就用原来的端口就行了。一个端口上可以维持几乎无数多个tcp连接,只要硬件资源足够。
那如何处理多个客户端的tcp请求呢,一个方法是来一个新的客户端就开一个进程/线程,另一个方法是使用I/O多路复用,这个后面再说。(并不知道怎么用多进程处理并发)
OS记好哪个端口的数据提交到哪个应用,并记录每个进程所使用的文件描述符和tcp连接的对应关系。
说到底,端口号不过是为了方便os将数据交给应用而使用的区分方式。socket描述字则是区分tcp/udp连接的方式。
参考
网络编程释疑之:单台服务器上的并发TCP连接数可以有多少
Linux和Windows下Socket句柄(描述符)的分配策略
三、同步、异步、阻塞、非阻塞
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
blocking I/O
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: 
non-blocking I/O
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子: 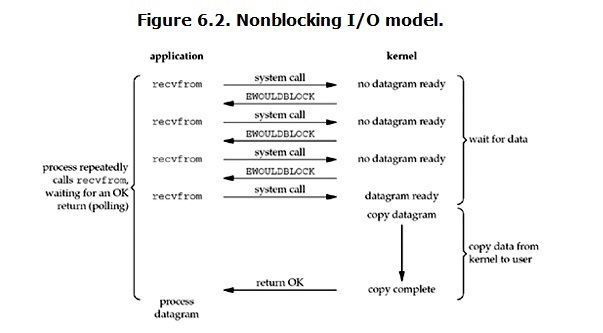
I/O multiplexing
select/epoll的好处就在于单个process就可以同时处理多个网络连接的I/O。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图: 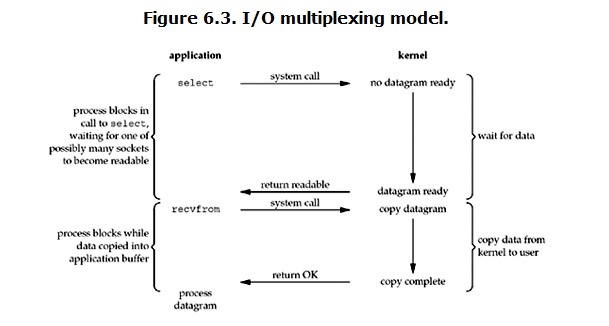
执行select后,process被select阻塞的。
Asynchronous I/O
linux下的asynchronous I/O其实用得很少。先看一下它的流程: 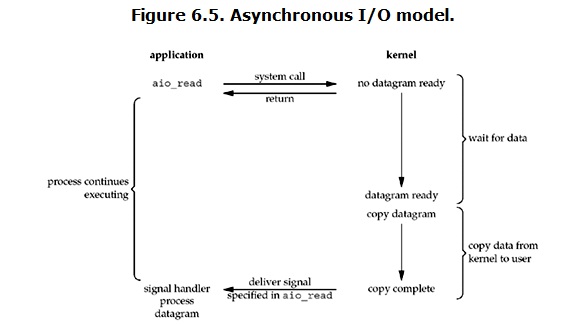
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
参考
IO - 同步,异步,阻塞,非阻塞
- 网络与并发
- 网络编程与并发-线程、进程、协程
- 网络编程与并发-IO模型
- 网络编程与并发-FTP开发
- POSA2 第一章 并发网络对象(概述与1.1动机)
- 网络编程与并发-批量主机管理工具开发
- 【并发与负载】千万级规模高性能、高并发的网络架构经验分享
- 网络并发服务器模型
- 并发网络架构
- 网络并发服务器设计
- 网络编程与并发-TCP/UDP套接字、粘包问题、Socket编程、并发编程、FTP作业
- 网络编程与并发-TCP/UDP套接字、粘包问题、Socket编程、并发编程、FTP作业
- Python发送网络封包,自定义封包结构与内容并发出去
- 高性能网络编程5--IO复用与并发编程
- 高性能网络编程5--IO复用与并发编程
- 高性能网络编程五--IO复用与并发编程
- 高性能网络编程5--IO复用与并发编程
- 高性能网络服务器5--IO复用与并发模型
- Web前端性能优化之浏览器访问优化
- 黑盒测试
- Java内存分析 --- 虚拟机运行时数据区
- Android开发之基础新特性-------------Fragment&帧动画(一知识点)
- poj3299解题报告
- 网络与并发
- 3dmt项目开发总结
- 求1+2+3+...+n
- App自动化之使用Ant编译项目多渠道打包
- ubuntu的火狐浏览器习惯设置
- C#和JAVA GET,SET对比
- iOS和OSX的核心
- Java ArryList
- 美化 powerline


