BOM字符串匹配算法
来源:互联网 发布:淘宝和天猫客户端 编辑:程序博客网 时间:2024/05/29 16:03
Backward Oracle Matching algorithm
LINK :http://igm.univ-mlv.fr/~lecroq/string/bom.html
Only the external transitions of the oracle are stored in link lists (one per state). The labels of these transitions and all the other transitions are not stored but computed from the word x. The description of a linked list List can be found in the introduction section implementation.
#define FALSE 0#define TRUE 1int getTransition(char *x, int p, List L[], char c) { List cell; if (p > 0 && x[p - 1] == c) return(p - 1); else { cell = L[p]; while (cell != NULL) if (x[cell->element] == c) return(cell->element); else cell = cell->next; return(UNDEFINED); }}void setTransition(int p, int q, List L[]) { List cell; cell = (List)malloc(sizeof(struct _cell)); if (cell == NULL) error("BOM/setTransition"); cell->element = q; cell->next = L[p]; L[p] = cell;}void oracle(char *x, int m, char T[], List L[]) { int i, p, q; int S[XSIZE + 1]; char c; S[m] = m + 1; for (i = m; i > 0; --i) { c = x[i - 1]; p = S[i]; while (p <= m && (q = getTransition(x, p, L, c)) == UNDEFINED) { setTransition(p, i - 1, L); p = S[p]; } S[i - 1] = (p == m + 1 ? m : q); } p = 0; while (p <= m) { T[p] = TRUE; p = S[p]; }}void BOM(char *x, int m, char *y, int n) { char T[XSIZE + 1]; List L[XSIZE + 1]; int i, j, p, period, q, shift; /* Preprocessing */ memset(L, NULL, (m + 1)*sizeof(List)); memset(T, FALSE, (m + 1)*sizeof(char)); oracle(x, m, T, L); /* Searching */ j = 0; while (j <= n - m) { i = m - 1; p = m; shift = m; while (i + j >= 0 && (q = getTransition(x, p, L, y[i + j])) != UNDEFINED) { p = q; if (T[p] == TRUE) { period = shift; shift = i; } --i; } if (i < 0) { OUTPUT(j); shift = period; } j += shift; }}The test i + j >= 0 in the inner loop of the searching phase of the function BOM is only necessary during the first attempt if x occurs at position 0 on y. Thus to avoid testing at all the following attempts the first attempt could be distinguished from all the others.
Preprocessing phase
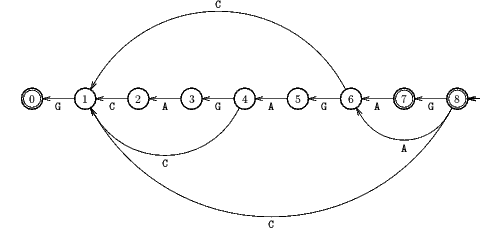
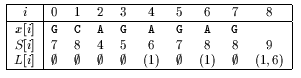
Oracle used by Backward Oracle Matching algorithm.
Shift by: 5 (8 - 3)
Shift by: 7 (8 - 1)
Shift by: 7 (8 - 1)
The Backward Oracle Matching algorithm algorithm performs 17 character comparisons on the example.
LINK :http://wenda.tianya.cn/question/32adf8000d0f5af7
字符串匹配算法之Backward Oracle Matching
上一篇介绍的BNDM,用了位运算,所以至多只能处理长度跟计算机字长一样的串,如果串很长,就要考虑别的算法了。可以在O(N)的时间里构造一个自动机,让它在线性时间里识别一个串是否为该串的子串。但是这在算法上会非常复杂。最终的速度也不会快。
这里要介绍的是一种能在线性时间里识别出一个字符串的子串,当然它同时也会识别出一些不是子串的串。这样在指导跳转的时候,它会导致更多的比较,但是这个算法本身常数比较小,所以最终速度还是比较快的。
为了方便理解,先讲从左到右匹配的情况吧。对于长度为M的串,建一个有M+1个节点的自动机,节点i跟i+1之间有一个跳转,跳转的字符为串的第i个字符。为类跳转质上是表示出了这个串。还有另一类节点,由节点指向1,2,……m+1,0到i+1跳转的字符为i到i+1跳转的字符。如果一个字符在一个串里多次出现,则只在0跟该字母第一次出现的地方有跳转。增加这类节点,是为了识别非前缀的子串。如果只有前面两种跳转的话,这个自动机只能识别出前缀和后缀。还要增加更多的跳转。如果串里有两个子串,Wx,Wy,当x匹配失败的时候,应该从Wx跳转到Wy,这要求W有一个跳转到y。W如果为一个任意长度的子串,只就是一个精确匹配子串的自动机了。在这里,为了简化问题,仅考虑W为单个字符的情况。对于i<j,如果i到i+1的跳转与j到j+1的跳转相同,则i+1增加一个跳转到j+2,跳转的字符为j+1到j+2的跳转符。对于一个j,如果有多个i满足这个条件,则只有最小的i进行这个操作。
现在来分析一下这个自动机的复杂度。自动机的顶点个数为M+1,是线性的。关键是跳转的数量。第一类跳转有M个,第二类跳转至多有M-1个(因为0-1的跳转属于第一类,所以第二类至少会少一个),第三类,至多也是M个,因为一个节点至多能作为第三类节点的入节点一次。
现在的证明一下这个自动机能够识别出串的所有子串。所设给定的串在源串的i位置出现,匹配到j个位置的时候,如果正好匹配到位置i+k,则后面可以顺着第一类跳转一路匹配下去,一定可以识别的。所以关键是要证明,匹配的位置在i+k后面。刚开始的时候,位于节点0,根据构造的方案,匹配的过程,不可能跳过i+k,直接进入到下一个。假设当前处于位置j<i+k,则识别下一个字符后,位置j的字符跟i+k的字符应该是相同的,这时候,如果顺着第一类节点走到j+1,则继续让j+1跟i+k+1比较,如果失败,j不会直接跳转到i+k+1后面,而是跳转到i+k+1,或它前面。
所以它一定可以识别出子串。从构造看到,它还会识别出非子串。但是我们真正的目的是要识别一个完整的串,对于完整的串它不会识别别。完整的串的长度必须为m,所以它只能顺着第一类节点从0走到m+1。识别出错识的子串,只会使得跳转变短,降低速度。
如果识别出完整的串,这时候找到解了。如果没有识别出完整的串,则主串的位置移动(串的长度-匹配到的最长串的长度)。这样会否漏掉解呢?可以用反证法证明,如果在一个更左的位置有解的话,匹配到的最长串的长度还应该更长些。
在应用中,因为是从右往左匹配,所以建自动机的时候,是要把模式串反转再去建自动机的。
跳转后能找到解的一个必要条件是,上一次找到的子串是模式串的前缀,也就是反转之后的后缀,那为什么不直接建识别后缀的自动机呢,这样会更快。那是因为那种自动机很难建。
- BOM字符串匹配算法
- 算法 字符串匹配算法
- 字符串匹配算法
- BM字符串匹配算法
- KMP 字符串匹配算法
- 字符串匹配算法
- 字符串匹配算法
- 字符串匹配算法(摘)
- 字符串匹配算法
- 字符串匹配算法
- 字符串匹配的算法
- kmp字符串匹配算法
- 字符串匹配算法
- 字符串匹配算法研究
- 字符串模式匹配算法
- kmp字符串匹配算法
- KMP字符串匹配算法
- 字符串模式匹配算法
- POJ-2407-Relatives-欧拉函数
- mysql select into table
- 更新cocoaPods
- Latent semantic analysis note(LSA)
- spring&dom4j
- BOM字符串匹配算法
- C语言简单函数应用:数学计算
- Java线程池 ExecutorService
- 自定义UITabBar 在 popToViewController 或popToRootViewController后UITabBarItem出现重叠
- STM32IAP升级-----编写IAP升级遇到的问题总结
- OC 常用类 --- NSDate
- Android程序猿挑战高薪必会的十大面试题
- mappingResources,annotatedClasses(映射)
- ios中AFNetworking的使用


