Spark集群基于Zookeeper的HA搭建部署
来源:互联网 发布:博时基金待遇 知乎 编辑:程序博客网 时间:2024/06/06 08:58
1.环境介绍
(1)操作系统RHEL6.2-64
(2)两个节点:spark1(192.168.232.147),spark2(192.168.232.152)
(3)两个节点上都装好了Hadoop 2.2集群
2.安装Zookeeper
(1)下载Zookeeper:http://apache.claz.org/zookeeper ... keeper-3.4.5.tar.gz
(2)解压到/root/install/目录下
(3)创建两个目录,一个是数据目录,一个日志目录

(4)配置:进到conf目录下,把zoo_sample.cfg修改成zoo.cfg(这一步是必须的,否则zookeeper不认识zoo_sample.cfg),并添加如下内容
(5)在/root/install/zookeeper-3.4.5/data目录下创建myid文件,并在里面写1
(6)把/root/install/zookeeper-3.4.5整个目录复制到其他节点
(7)登录到spark2节点,修改myid文件里的值,将其修改为2
(8)在spark1,spark2两个节点上分别启动zookeeper
(9)查看进程进否成在
3.配置Spark的HA
(1)进到spark的配置目录,在spark-env.sh修改如下
(2)把这个配置文件分发到各个节点上去
(3)启动spark集群
(4)进到spark2(192.168.232.152)节点,把start-master.sh 启动,当spark1(192.168.232.147)挂掉时,spark2顶替当master
(5)查看spark1和spark2上运行的哪些进程
4.测试HA是否生效
(1)先查看一下两个节点的运行情况,现在spark1运行了master,spark2是待命状态
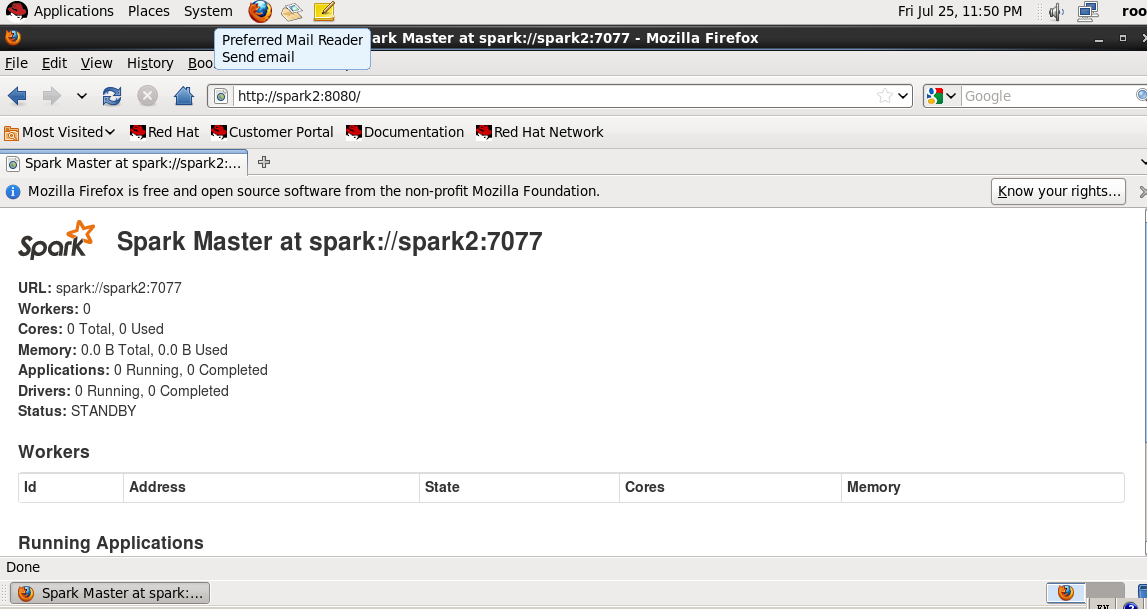
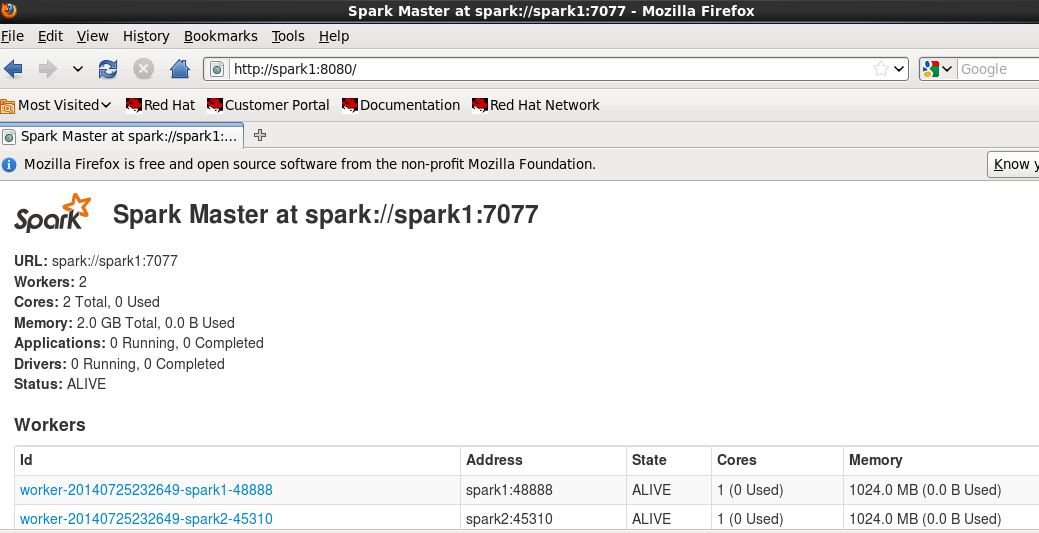
(2)在spark1上把master服务停掉
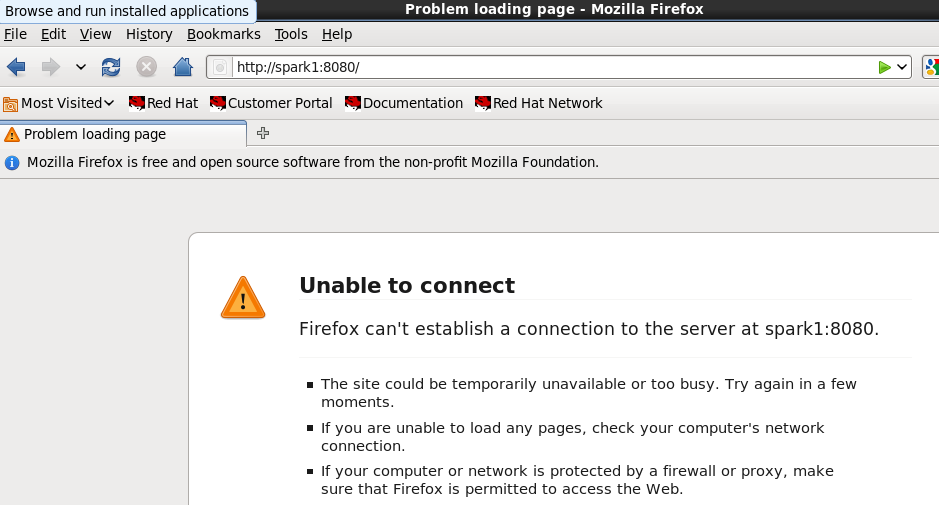
(3)用浏览器访问master的8080端口,看是否还活着。以下可以看出,master已经挂掉
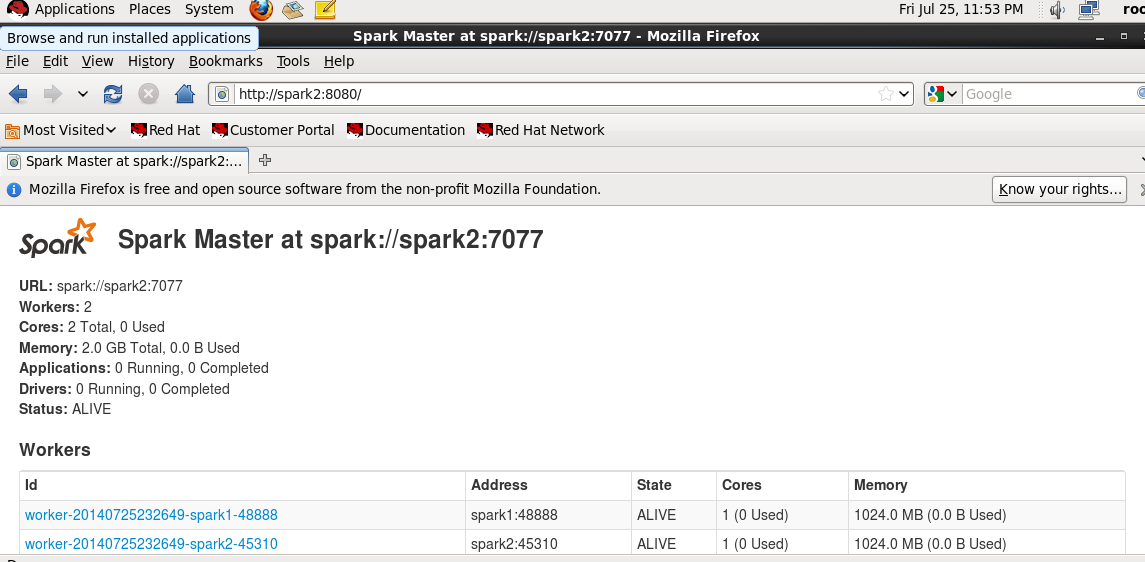
(4)再用浏览器访问查看spark2的状态,从下图看出,spark2已经被切换当master了
(1)操作系统RHEL6.2-64
(2)两个节点:spark1(192.168.232.147),spark2(192.168.232.152)
(3)两个节点上都装好了Hadoop 2.2集群
2.安装Zookeeper
(1)下载Zookeeper:http://apache.claz.org/zookeeper ... keeper-3.4.5.tar.gz
(2)解压到/root/install/目录下
(3)创建两个目录,一个是数据目录,一个日志目录
(4)配置:进到conf目录下,把zoo_sample.cfg修改成zoo.cfg(这一步是必须的,否则zookeeper不认识zoo_sample.cfg),并添加如下内容
(5)在/root/install/zookeeper-3.4.5/data目录下创建myid文件,并在里面写1
(6)把/root/install/zookeeper-3.4.5整个目录复制到其他节点
(7)登录到spark2节点,修改myid文件里的值,将其修改为2
(8)在spark1,spark2两个节点上分别启动zookeeper
(9)查看进程进否成在
3.配置Spark的HA
(1)进到spark的配置目录,在spark-env.sh修改如下
(2)把这个配置文件分发到各个节点上去
(3)启动spark集群
(4)进到spark2(192.168.232.152)节点,把start-master.sh 启动,当spark1(192.168.232.147)挂掉时,spark2顶替当master
(5)查看spark1和spark2上运行的哪些进程
4.测试HA是否生效
(1)先查看一下两个节点的运行情况,现在spark1运行了master,spark2是待命状态
(2)在spark1上把master服务停掉
(3)用浏览器访问master的8080端口,看是否还活着。以下可以看出,master已经挂掉
(4)再用浏览器访问查看spark2的状态,从下图看出,spark2已经被切换当master了
0 0
- Spark集群基于Zookeeper的HA搭建部署笔记
- Spark集群基于Zookeeper的HA搭建部署
- Spark集群基于Zookeeper的HA搭建部署
- Spark集群基于Zookeeper的HA搭建部署笔记
- Spark集群基于Zookeeper的HA搭建部署
- Spark集群搭建+基于zookeeper的高可用HA
- Spark基于zookeeper的HA
- Spark HA 集群搭建【1、基于文件系统的手动HA 2、基于zk的自动HA】
- 基于Zookeeper的Spark HA配置说明
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
- 生产环境基于HA的Spark搭建
- 基于docker的hadoop HA 集群搭建
- 基于HA机制的Hadoop集群搭建
- Spark集群搭建(HA)
- 基于zookeeper的高可用Hadoop HA集群安装
- spark standalone zookeeper HA部署方式
- Spark自带的集群模式(Standalone),Spark/Spark-ha集群搭建
- Spark学习笔记8-搭建spark的HA(用zookeeper实现spark的高可用)
- View.setClickable无效的问题
- 数组递归折半求和
- appledoc,方便的程序文档编写工具
- 关于相对布局的一些属性
- 代理和块的区别
- Spark集群基于Zookeeper的HA搭建部署
- 【Android】混淆,fastjson
- Tomcat中配置https访问
- Python 多进程日志记录
- WIN7下 svn迁移到github
- sicily 1009. Mersenne Composite N
- linux ntpdate同步错误,差一个小时的问题
- 使用TabActivity实现底部菜单栏
- MySQL学习笔记2-System administration(set password)


