[Python]Flask构建网站分析应用
来源:互联网 发布:淘宝端口 编辑:程序博客网 时间:2024/06/14 21:51
原文Saturday morning hacks: Building an Analytics App with Flask - 由orangleliu友情翻译 ,主要是通过埋点技术来实现web网页的统计分析需求
几年前我曾今写过一篇 使用Cassandra构建分析服务 当时只是为了好玩写的,实际上 Cassandra 根本不适合我真正的需求,所以我决定写些简单的东西。 我很高兴宣布新的统计应用在过去的5个月非常稳定的运行,并且只消耗了 20M 内存。这篇文章我会展示怎样使用 Flask 来构建一个轻量的统计分析服务。
分析请求/响应流程
我们将要构建的分析服务有点类似 Google Analytics (更像是个简化版)
工作流程:
- 每个要被跟踪的页面都会使用
<script>标签引入一个 JavaScript 文件,这个文件由我们的应用(例如,放在被分析网站的基础模板中) - 当有人访问你的网站的时候,他们的浏览器会执行这个 JavaScript 文件
- JavaScript 中的代码可以读取当前网页的标题,URL,还有其他感兴趣的元素。
- 最酷的地方是,这个脚本会动态的创建一个
<img>标签(一般来说是个1*1px的空白图片),这个标签的 src 属性的 URL 正式指向我们的分析应用 - 当前页面中的信息收集完毕并且编码之后就会设置成图片的 src 属性,我们的分析服务端就会收到并解析这些信息
- 分析服务解析完成,把这条信息存入数据库,然后返回一个1像素的gif图片
下面是交互图: 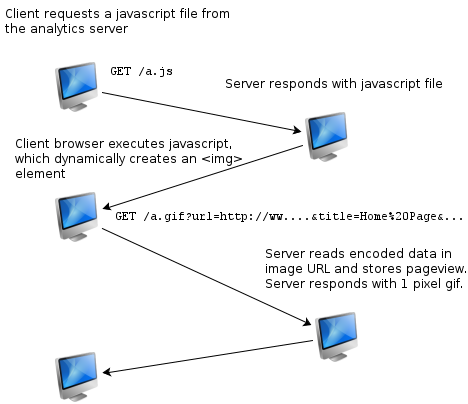
设计考虑
因为要在资源有限的 VPS(可以认为是配置非常低的服务器) 上运行, 我的博客也没有多少流浪,所以要轻量,灵活。不管什么类型的项目我都喜欢使用 Flask,这个项目更是如此。 我们将使用 peewee ORM 来存储PV(页面访问数据) 和查询分析数据。 告诉大家吧,我们的应用不会超过100行代码(包括注释)。
- PV (page view)页面访问
数据库相关
为了能方面的查询数据,我们将使用关系型数据库存储PV数据。 我选择了 BerkeleyDB’s SQLite 接口,因为它是个轻量的嵌入数据库,也不会用多少内存。我曾考虑过 SQLite, 但是 BerkeleyDB 在并发访问时候比 SQLite 性能高很多。 当分析应用遭到某些破坏的时候,仍然可以保持稳定运行。

如果你已经安装了 Postgresql 或者 MySQL, 那么请自由选择。
WSGI Server
虽然有非常多的选择,但是我还是比较喜欢使用 gevent。 Gevent 是一个基于协程的网络库,使用了 libev 的事件机制来实现轻线程(greenlets)。 通过使用 monkey-patching ,不需要特殊的API或者是语法,gevent 会把正常阻塞的 python 程序变成非阻塞的。 Gevent 的 WSGI server,尽管非常基础,但是有着非常高的性能和非常低的资源消耗。 和数据库一样,如果你使用别的库比较顺手,请自由选择。
创建 virtualenv
我们先给这个分析应用创建一个隔离的环境,安装上 flask, peewee(选择安装gevent).
$ virtualenv analyticsNew python executable in analytics/bin/python2Also creating executable in analytics/bin/pythonInstalling setuptools, pip...done.$ cd analytics/$ source bin/activate$ pip install flask peewee......Successfully installed flask peewee Werkzeug Jinja2 itsdangerous markupsafeCleaning up...$ pip install gevent # Optional.如果你想编译 Python SQLite 驱动来支持 BerkeleyDB, 检出 playhouse 模块(lib/python2.7/site-packages/playhouse/berkeley_build.sh) 中的 berkeley_build.sh 脚本。 这个脚本将会下载和编译 BerkeleyDB ,然后再编译 pysqlite,详细的过程请看这篇文章。 你也可以跳过这个步骤,直接使用 peewee 的 SqliteDatabase 类。
实现Flask应用
让我们从整体代码框架开始吧。 正如前面讨论的,我们将会创建2个 view,一个用来返回 JavaScript 文件,另一个用来创建1像素的GIF图片。 在 analytics目录(这是作者开发使用的目录,没有请自行创建),创建 analytics.py 文件,代码在下面列出。 这些代码包括了应用的代码结构,还有基本配置。
#coding:utf-8from base64 import b64decodeimport datetimeimport jsonimport osfrom urlparse import parse_qsl, urlparsefrom flask import Flask, Response, abort, requestfrom peewee import *from playhouse.berkeleydb import BerkeleyDatabase # Optional.# 1 pixel GIF, base64-encoded.BEACON = b64decode('R0lGODlhAQABAIAAANvf7wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==')# Store the database file in the app directory.APP_DIR = os.path.dirname(__file__)DATABASE_NAME = os.path.join(APP_DIR, 'analytics.db')DOMAIN = 'http://127.0.0.1:5000' # TODO: change me.# Simple JavaScript which will be included and executed on the client-side.JAVASCRIPT = '' # TODO: add javascript implementation.# Flask application settings.DEBUG = bool(os.environ.get('DEBUG'))SECRET_KEY = 'secret - change me' # TODO: change me.app = Flask(__name__)app.config.from_object(__name__)database = BerkeleyDatabase(DATABASE_NAME) # or SqliteDatabase(DATABASE_NAME)class PageView(Model): # TODO: add model definition. class Meta: database = database@app.route('/a.gif')def analyze(): # TODO: implement 1pixel gif view.@app.route('/a.js')def script(): # TODO: implement javascript view.@app.errorhandler(404)def not_found(e): return Response('Not found.')if __name__ == '__main__': database.create_tables([PageView], safe=True) app.run()从浏览器获取信息
我们开始写收集客户端信息的 JavaScript 文件, 主要就是抽取一些页面基本信息
- URL信息,包括查询信息(document.location.href)
- 页面的title (document.title)
- 页面的feferring信息,如果有的话 (document.referrer)
下面的一些属性也可以提取出来,如果你感兴趣的话(我:其实可能比列出的多的多,特别是H5),例如:
* cookie信息(document.cookie)
* 文档的最后修改时间(document.lastModified)
* 更多
提取了这些信息之后,我们通过url的查询字符串传给 analyze 这个view。 为了简单,这个 js 将在页面加载的时候立即触发,我们把所有的代码封装到一个匿名函数中。 最后使用 encodeURIComponent 方法对所有参数进行转义,确保所有参数安全:
(function() { var img = new Image, url = encodeURIComponent(document.location.href), title = encodeURIComponent(document.title), ref = encodeURIComponent(document.referrer); img.src = '%s/a.gif?url=' + url + '&t=' + title + '&ref=' + ref;})();我们预留Python中的占位符 %s,用来读取 DOMAIN 配置并插入到其中,组成完整的JS代码
在py文件中我们定义一个 JAVASCRIPT 变量来存储上面的 js代码:
# Simple JavaScript which will be included and executed on the client-side.JAVASCRIPT = """(function(){ var d=document,i=new Image,e=encodeURIComponent; i.src='%s/a.gif?url='+e(d.location.href)+'&ref='+e(d.referrer)+'&t='+e(d.title); })()""".replace('\n', '')在view中这样处理
@app.route('/a.js')def script(): return Response( app.config['JAVASCRIPT'] % (app.config['DOMAIN']), mimetype='text/javascript')保存PV信息
上面的脚本将会传3个值给 analyze 这个view, 包括页面的URL,title,和 referring page。 现在我们来定义一个 PageView 模型来存储这些数据。
在服务端,我们也可以读取到 访问者的IP和请求头信息,所以我们也为这些信息创建字段,还要加上请求的时间戳字段。
因为每个浏览器有着不同的请求头,每个页面请求的查询参数也不尽相同,我们将把他们用 JSON 格式存储到 TextField字段中。 如果你使用 Postgresql, 可以用 HStore 或者 native JSON data-type。
下面是 PageView 模型的定义,还定义了一个 JSONField 用来存储 查询参数和请求头信息:
class JSONField(TextField): """Store JSON data in a TextField.""" def python_value(self, value): if value is not None: return json.loads(value) def db_value(self, value): if value is not None: return json.dumps(value)class PageView(Model): domain = CharField() url = TextField() timestamp = DateTimeField(default=datetime.datetime.now, index=True) title = TextField(default='') ip = CharField(default='') referrer = TextField(default='') headers = JSONField() params = JSONField() class Meta: database = database先我们给 PageView 添加一个方法,让它可以从请求中提取所有需要的值,并存到数据库。 urlparse 模块中包含了很多提取 request 信息的方法,我们用这些方法来获取 访问URL和请求参数:
class PageView(Model): # ... field definitions ... @classmethod def create_from_request(cls): parsed = urlparse(request.args['url']) params = dict(parse_qsl(parsed.query)) return PageView.create( domain=parsed.netloc, url=parsed.path, title=request.args.get('t') or '', ip=request.headers.get('X-Forwarded-For', request.remote_addr), referrer=request.args.get('ref') or '', headers=dict(request.headers), params=params)analyze view 最后一步是返回一个1像素的GIF图片,为了安全起见,我们将检查下 URL是否存在,确保不会再数据库插入一个空白记录。
@app.route('/a.gif')def analyze(): if not request.args.get('url'): abort(404) with database.transaction(): PageView.create_from_request() response = Response(app.config['BEACON'], mimetype='image/gif') response.headers['Cache-Control'] = 'private, no-cache' return response启动应用
这个时候如果你想测试下应用,可以先在命令行设置下 DEBUG=1 来启动debug模式
(analytics) $ DEBUG=1 python analytics.py * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with reloader访问 http://127.0.0.1:5000/a.js 可以看到js文件。 如果本地有其他的web应用,可以把这段js嵌入到它的页面中,测试下 分析应用
<script src="http://127.0.0.1:5000/a.js" type="text/javascript"></script>为了把应用部署到生产环境,建议使用专用的 WSGI 服务器。我喜欢用 gevent,非常轻量和高性能。你可以修改 analytics.py 文件,使用 gevent 代替原来的 Flask server。 下面是使用 gevent 来运行应用在 5000端口的写法:
if __name__ == '__main__': from gevent.wsgi import WSGIServer WSGIServer(('', 5000), app).serve_forever()因为 gevent 是使用 monkey-patching 来实现高并发的,需要在 analytics.py 加上下面一行:
from gevent import monkey; monkey.patch_all()查询数据
真正感觉到快乐的是收集了几天数据,查询的时候。这部分我们将看看怎样从收集的数据中查询出来一些有意思的信息。
下面使用我博客的数据,我们将会对最近7天的数据进行一些查询
>>> from analytics import *>>> import datetime>>> week_ago = datetime.date.today() - datetime.timedelta(days=7)>>> base = PageView.select().where(PageView.timestamp >= week_ago)首先,我们来看看过去一周的PV
>>> base.count()1133有多少不同的IP访问过我的网站
>>> base.select(PageView.ip).group_by(PageView.ip).count()850访问最多的10个页面?
print (base .select(PageView.title, fn.Count(PageView.id)) .group_by(PageView.title) .order_by(fn.Count(PageView.id).desc()) .tuples())[:10]# Prints...[('Postgresql HStore, JSON data-type and Arrays with Peewee ORM', 88), ("Describing Relationships: Django's ManyToMany Through", 73), ('Using python and k-means to find the dominant colors in images', 66), ('SQLite: Small. Fast. Reliable. Choose any three.', 58), ('Using python to generate awesome linux desktop themes', 54), ("Don't sweat the small stuff - use flask blueprints", 51), ('Using SQLite Full-Text Search with Python', 48), ('Home', 47), ('Blog Entries', 46), ('Django Patterns: Model Inheritance', 44)]4个小时为单位,一天中哪个时间访问的人最多呢?
hour = fn.date_part('hour', PageView.timestamp) / 4id_count = fn.Count(PageView.id)print (base .select(hour, id_count) .group_by(hour) .order_by(id_count.desc()) .tuples())[:][(3, 208), (2, 201), (0, 194), (1, 183), (4, 178), (5, 169)]基于这些数据,看起来每天午餐时间访问的人最多,网上午夜前访问的人数最少,总得流量比较平均。
哪些 user-agents 最流行呢?
from collections import Counterc = Counter(pv.headers.get('User-Agent') for pv in base)print c.most_common(5)[(u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36', 81), (u'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36', 70), (u'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:32.0) Gecko/20100101 Firefox/32.0', 50), (u'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit/537.78.2 (KHTML, like Gecko) Version/7.0.6 Safari/537.78.2', 37), (u'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0', 37)]你想要什么数据全看你。 一个有意思的就是查询某个IP访问所有页面的次序列表。 这也就能看到人们怎么再你的网站上一页一页的访问
inner = base.select(PageView.ip, PageView.url).order_by(PageView.timestamp)query = (PageView .select(PageView.ip, fn.GROUP_CONCAT(PageView.url).alias('urls')) .from_(inner.alias('t1')) .group_by(PageView.ip) .order_by(fn.Count(PageView.url).desc())print {pv.ip: pv.urls.split(',') for pv in query[:10]}# Prints something like the following:{ u'xxx.xxx.xxx.xxx': [ u'/blog/peewee-was-baroque-so-i-rewrote-it/', u'/blog/peewee-was-baroque-so-i-rewrote-it/', u'/blog/', u'/blog/postgresql-hstore-json-data-type-and-arrays-with-peewee-orm/', u'/blog/search/', u'/blog/the-search-for-the-missing-link-what-lies-between-sql-and-django-s-orm-/', u'/blog/how-do-you-use-peewee-/'], u'xxx.xxx.xxx.xxx': [ u'/blog/dont-sweat-small-stuff-use-flask-blueprints/', u'/', u'/blog/', u'/blog/migrating-to-sqlite/', u'/blog/', u'/blog/saturday-morning-hacks-revisiting-the-notes-app/'], u'xxx.xxx.xxx.xxx': [ u'/blog/using-python-to-generate-awesome-linux-desktop-themes/', u'/', u'/blog/', u'/blog/customizing-google-chrome-s-new-tab-page/', u'/blog/-wallfix-using-python-to-set-my-wallpaper/', u'/blog/simple-botnet-written-python/'], # etc...}提升应用的想法
- 建立一个web接口或者是API来查询pv数据
- 使用表或者是类似 Postgresql HStore 来标准化请求头数据
- 收集用户cookies 跟踪用户访问路径
- 使用 GeoIP 来确定用户的地理位置
- 使用 canvas 指纹来更好的确定用户的唯一性
- 更多更酷的查询来研究数据
感谢阅读
感谢阅读,有什么问题请联系我。 项目的 gist地址在这
- [Python]Flask构建网站分析应用
- python应用部署--flask
- python应用部署--flask
- 项目实战 | Python Flask 构建微电影视频网站视频教程 百度云盘
- Flask构建微电影视频网站
- python flask搭建web应用
- 如何部署python + flask应用
- Python Flask(六) 大型网站架构
- python使用flask和bootstrap制作网站
- Python+Flask搭建一个电影下载网站
- python flask make_response的应用示例
- Python 的 Flask 框架安装应用
- python flask,file structure ,blueprint简单应用
- 使用python下的Flask应用
- 利用Flask-AppBuilder 快速构建Web后台管理应用
- flask(python)
- Python Flask
- python+flask
- 协议森林09 爱的传声筒 (TCP连接)
- C#读取本机IP
- 八皇后问题
- flask-hello 程序
- memcached的基础知识
- [Python]Flask构建网站分析应用
- HTTP请求过程
- MurmurHash算法
- Android项目依赖与直接导入Jar包
- Jquery easyui switchbutton简单使用
- AndroidStudio单元测试——instrumentation
- 利用第三方异步网路加载库AsyncHttpClient
- swift 1.0更新为2.0后的变化
- Python 基础


