Stanford UFLDL教程 可视化自编码器训练结果
来源:互联网 发布:mycard点数卡 淘宝 编辑:程序博客网 时间:2024/05/02 13:24
可视化自编码器训练结果
训练完(稀疏)自编码器,我们还想把这自编码器学到的函数可视化出来,好弄明白它到底学到了什么。我们以在10×10图像(即n=100)上训练自编码器为例。在该自编码器中,每个隐藏单元i对如下关于输入的函数进行计算:
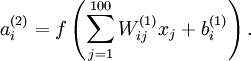
我们将要可视化的函数,就是上面这个以2D图像为输入、并由隐藏单元i计算出来的函数。它是依赖于参数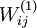 的(暂时忽略偏置项bi)。需要注意的是,
的(暂时忽略偏置项bi)。需要注意的是,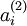 可看作输入
可看作输入 的非线性特征。不过还有个问题:什么样的输入图像可让得到最大程度的激励?(通俗一点说,隐藏单元
的非线性特征。不过还有个问题:什么样的输入图像可让得到最大程度的激励?(通俗一点说,隐藏单元 要找个什么样的特征?)。这里我们必须给加约束,否则会得到平凡解。若假设输入有范数约束
要找个什么样的特征?)。这里我们必须给加约束,否则会得到平凡解。若假设输入有范数约束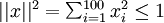 ,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素
,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素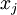 给出(共需计算100个像素,j=1,…,100):
给出(共需计算100个像素,j=1,…,100):
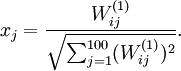
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们面前之时,隐藏单元所追寻特征的真正含义也渐渐明朗起来。
假如我们训练的自编码器有100个隐藏单元,可视化结果就会包含100幅这样的图像——每个隐藏单元都对应一幅图像。审视这100幅图像,我们可以试着体会这些隐藏单元学出来的整体效果是什么样的。
当我们对稀疏自编码器(100个隐藏单元,在10X10像素的输入上训练 )进行上述可视化处理之后,结果如下所示:

上图的每个小方块都给出了一个(带有有界范数 的)输入图像,它可使这100个隐藏单元中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。
显而易见,这些特征对物体识别等计算机视觉任务是十分有用的。若将其用于其他输入域(如音频),该算法也可学到对这些输入域有用的表示或特征。
中英文对照
- 可视化 Visualizing
- 自编码器 Autoencoder
- 隐藏单元 hidden unit
- 非线性特征 non-linear feature
- 激励 activate
- 平凡解 trivial answer
- 范数约束 norm constrained
- 稀疏自编码器 sparse autoencoder
- 有界范数 norm bounded
输入域 input domains
- from: http://ufldl.stanford.edu/wiki/index.php/%E5%8F%AF%E8%A7%86%E5%8C%96%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8%E8%AE%AD%E7%BB%83%E7%BB%93%E6%9E%9C
0 0
- Stanford UFLDL教程 可视化自编码器训练结果
- 可视化自编码器训练结果
- 可视化自编码器训练结果
- 可视化自编码器训练结果
- Stanford UFLDL教程 稀疏自编码器符号一览表
- UFLDL教程(一)---稀疏自编码器
- UFLDL稀疏自编码器练习第一步:生成训练集
- Stanford UFLDL教程 白化
- UFLDL教程(六)之栈式自编码器
- UFLDL 教程学习笔记:1.稀疏自编码器
- Stanford UFLDL教程 自编码算法与稀疏性
- Stanford UFLDL教程 栈式自编码算法
- Stanford UFLDL教程 微调多层自编码算法
- Stanford UFLDL教程 稀疏编码自编码表达
- 【UFLDL】稀疏自编码器AE
- Stanford UFLDL教程 池化Pooling
- Stanford UFLDL教程 Exercise:Vectorization
- Stanford UFLDL教程 Softmax回归
- LibGDX_8.1: LibGDX 项目实战: 开发跨平台 2048 游戏
- Stanford UFLDL教程 自编码算法与稀疏性
- DOSBOX 0.74模拟器安装Windows 95
- 计算两条直线之间的距离
- CSS中margin和padding的区别
- Stanford UFLDL教程 可视化自编码器训练结果
- 人人都能开发物联网(三.究竟想玩些什么呢?)
- Stanford UFLDL教程 稀疏自编码器符号一览表
- POJ-2606
- Swift中使用presentViewController跳转页面后模拟器显示黑屏问题
- Stanford UFLDL教程 Exercise:Sparse Autoencoder
- 2003
- Stanford UFLDL教程 矢量化编程
- xUtils解析json数据


