ResourceManager High Availability
来源:互联网 发布:郑州网络维修 编辑:程序博客网 时间:2024/06/06 01:14
Apache 官方原文地址:http://hadoop.apache.org/docs/r2.5.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
- 一 简介
- 二 架构
- 1 RM 切换
- 11 手工故障切换
- 22 自动故障切换
- 23 在 RM 故障切换中的客户端ApplicationMaster 和 NodeManager
- 2 恢复之前 Active-RM 的状态
- 1 RM 切换
- 三 部署
- 1 配置
- 11 配置样例
- 2 管理命令
- 3 ResourceManager 网页界面服务
- 4 网页服务
- 1 配置
一. 简介
这篇指南提供关于 YARN’s ResourceManager 的 High Availability 的概述,并详细介绍了如何配置和使用该特性。ResourceManager (RM) 负责追踪集群资源的使用情况,并且调度应用程序(例如,MapReduce 任务)。在 Hadoop 2.4 之前,ResourceManager 在 YARN 集群中是单点故障。 High Availability 特性以一对 Active/Standby ResourceManager 的形式增加 redundancy 以消除单点故障。
二. 架构
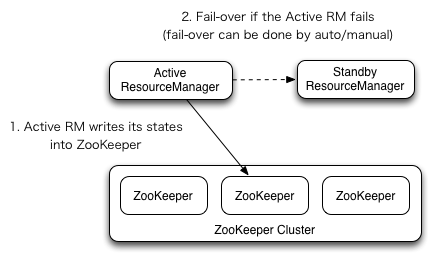
2.1 RM 切换
ResourceManager HA 是通过 Active/Standby 架构来实现的。在任何时刻,其中一个 RMs 是 Active 状态,其余的一个或多个 RMs 是 Standby 模式在 Active 节点发生不幸时随时切换。转换到 active 的触发点那么来自管理员(通过 CLI)或来内置的自动故障切换(这个需保证 automatic-failover 是开启的)
2.1.1 手工故障切换
当 automatic-failover 没有启动时,管理员必须手动将其中一个 RMs 切换到 Active 状态。当将一个 RM 切换到其他状态,首先要切换的是将 Acive 的RM 状态切换到 Standby 的状态和将 Standby 的RM 切换到 Active 状态。所有这些操作可以使用 “yarn rmadmin” CLI。
2.2.2 自动故障切换
有个嵌入到 RMs 中的选项是基于 ZooKeeper 的 ActiveStandbyElector ,它将决定哪个 RM 应该是 Active 状态。当 Active 节点失效或者无法响应了,另一个 RM 就自动被选举为 Active 并接管工作。注意到,没有必要像在 HDFS 中那样需要单独运行 ZKFC 的进程,因为内嵌在 RMs 中的 ActiveStandbyElector 扮演着故障检测器和 leader 选举器的角色,而并非是单独的 ZKFC 进程。
2.2.3 在 RM 故障切换中的客户端,ApplicationMaster 和 NodeManager
当有多个 RMs 存在时, clients 和节点所使用的配置文件 (yarn-site.xml) 应该需要列出所有的 RMs。Clients, ApplicationMasters (AMs) and NodeManagers (NMs) 将以轮询调度方法(Round-Robin fashion) 尝试连接 RMs直到它们连接到 Active RM。如果 Active 失效了,它们将继续采用轮询调度的方式直到联系到新的 “Active”。这个默认重试的逻辑是 org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider 的实现。你也可以通过实现 org.apache.hadoop.yarn.client.RMFailoverProxyProvider 来覆写逻辑。
2.2 恢复之前 Active-RM 的状态
伴随着 ResourceManger Restart 生效, 被选举未新的 active 状态的 RM 将装载内部状态并尽可能继续从之前故障失效的地方操作,这取决于 RM 的 restart 特性。新的尝试被用于每个先前提交到 RM 的所管理的应用。应用可以周期性地 checkpoint 以避免丢失任何任务。状态-存储 都必须对 Active/Standby RMs 可见。目前,有 persistence - FileSystemRMStateStore 和 ZKRMStateStore 这两种的方式实现 RMStateStore 。ZKRMStateStore 在任何时刻毫无疑问只允许向一个 RM 写操作,也因此被推荐用于 HA 集群的存储。当使用 ZKRMStateStore 时就没有独立地隔离机制来解决潜在的多个 RMs 都可以承担 Active 角色所引发的 ” split-brain” 情况。
三. 部署
3.1 配置
大部分的故障切换功能都可以在使用不同的配置属性调整的。以下是一系列 必须/重要 的配置属性。yarn-default.xml carries a full-list of knobs。查看 yarn-default.xml 更多包括默认值在内的信息。查看 the document for ResourceManger Restart 也可以作为启动 state-store 的启动指南。
3.1.1 配置样例
以下是一个启动 RM 故障切换所需最小样例
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property>3.2 管理命令
yarn rmadmin 有一些关于检查 RM 健康/状态、切换到 Active/Standby 状态的 HA-specific 命令。HA 命令将由 yarn.resourcemanager.ha.rm-ids 所设置的 RM 的服务 id 作为参数。
$ yarn rmadmin -getServiceState rm1 active $ yarn rmadmin -getServiceState rm2 standby如果自动故障切换生效,你不能手工故障切换命令。
$ yarn rmadmin -transitionToStandby rm1 Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag.重点在于这句: it may cause a split-brain scenario or other incorrect state。
查看 YarnCommands 中更多相关信息。
3.3 ResourceManager 网页界面服务
假设一个 standby RM 已经启动并且正在运行中,那么 Standby 将所有的 web 请求自动重定向到 Active,除了 “About” 界面。
3.4 网页服务
假设一个 standby RM 已经启动并且正在运行中,当援引一个 standby RM ,在 ResourceManager REST APIs 中所描述RM 网页服务将自动重定向到 Active RM。
- ResourceManager High Availability
- ResourceManager High Availability
- YARN (MRv2) ResourceManager High Availability
- 【Hadoop】Hadoop官方文档翻译—— YARN ResourceManager High Availability 2.7.3
- Hadoop官方文档翻译—— YARN ResourceManager High Availability 2.7.3
- High Availability PostgreSQL HOWTO
- Dell High Availability Clustering
- EverON High Availability Clustering
- Clustering and High Availability
- 6.High availability
- About High Availability
- Neo4j High Availability 配置
- Neo4j High Availability 配置
- Configuring HDFS High Availability
- HA(High Availability)简介
- Kafka High Availability
- Kafka High Availability(1)
- Kafka High Availability(2)
- 经验之谈—initWithFrame;initWithCoder;awakeFromNib
- Eclipse 新建Servlet出错问题
- 好友列表
- 懒加载异常的解决办法
- Linux 常用快捷键
- ResourceManager High Availability
- 神经网络入门
- react 资料链接
- git配置用户名密码
- LeetCode(109) Convert Sorted List to Binary Search Tree
- centos7 mysql-server 安装
- java多态的理解
- bootstrap按钮组(二)
- servlet以及spring mvc实现bigpipe技术分享


