(数据挖掘-入门-7)朴素贝叶斯
来源:互联网 发布:扫条码的软件 编辑:程序博客网 时间:2024/06/04 19:40
主要内容:
1、动机
2、贝叶斯定理
3、朴素贝叶斯分类器
4、NB与KNN比较
5、python实现
一、动机
1、前面提到的最近邻、K近邻作为分类器来说,只是说新样本更大可能性地属于某一类,并不能准确地给出一个确信度;
2、最近邻、K近邻分类器中,每次为新样本做分类都需要将所有训练样本全盘托出,计算一遍,这样的计算复杂度确实太大了。
为了解决上述两个问题,本文就介绍一种新的分类器——朴素贝叶斯。
朴素贝叶斯能够给出某个样本以多大的概率属于某一类别,而且不需要对训练样本进行重复计算。
二、贝叶斯定理
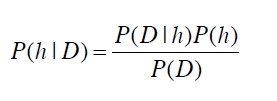
贝叶斯定理就是基于上述公式:h是hypothesis space假设空间,D表示data数据。
P(h|D):后验概率,表示在给定数据的情况下,该假设空间成立的概率;
P(h):先验概率,表示该假设空间的概率;
P(D|h):条件概率,表示在某个假设空间中,数据出现的概率;
三、朴素贝叶斯分类器
利用贝叶斯定理,我们就可以设计一种新的分类器。
如下图,共5列。前四列为数据表示,即特征,最后一列为数据样本属于的类别。
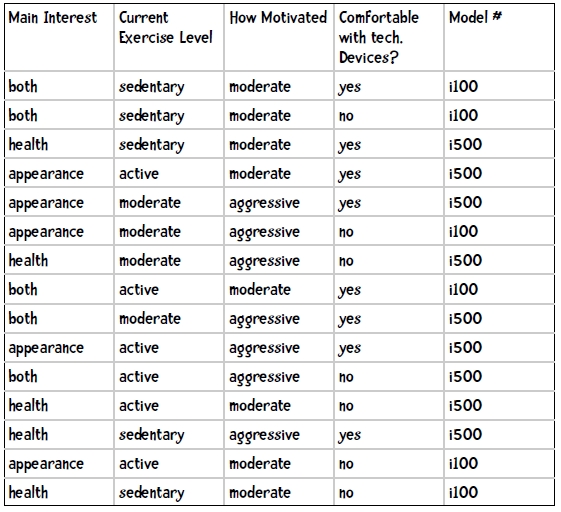
对应公式,h即代表类别,而Data即是这里的数据特征。
p(h):即类别h的先验概率
p(h|D):即在某个类别内,该数据出现的概率。
在这里,给一样本(health, moderateExercise, moderateMotivation, techComfortable),有两个类别,因此我们需要计算一下两个式子:
P1=P(i100 | health, moderateExercise, moderateMotivation, techComfortable)
P5=P(i500 | health, moderateExercise, moderateMotivation, techComfortable)
如果P1大于P5,那么该样本属于i100,否则则属于i500;
那么如何计算呢?
P1=P(health, moderateExercise, moderateMotivation, techComfortable | i100)*P(i100)
=P(health|i100)*P(moderateExercise|i100)*P(moderateMotivated|i100)*P(techComfortable|i100)P(i100)
P5=P(health, moderateExercise, moderateMotivation, techComfortable | i500)*P(i500)
=P(health|i500)*P(moderateExercise|i500)*P(moderateMotivated|i500)*P(techComfortable|i500)P(i500)
P(A|B)=P(A,B)/P(B)
注意红色部分,为什么它们是等价的?其实它们是不相等的,只是在朴素贝叶斯中,有个前提假设:
条件独立性假设:在已知类别下,特征之间是独立的。(这也是成为“朴素”的原因,因为这样计算非常简单,所有的概率计算均基于统计而已)
计算结果如下:很明显,该样本属于i500.
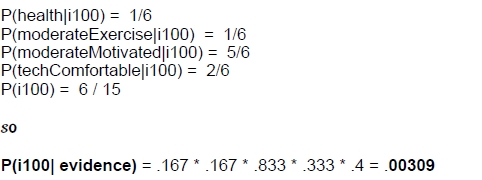

平滑问题:
如果某个特征或属性在训练集中没有出现或没有与类别共存,那么按照上述的计算方法将出现0概率,这样就严重地影响了分类器的正确性。
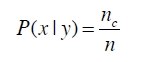
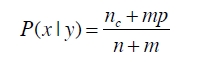
如上式所示,在原来的统计基础上,为每个概率分量添加一个先验,比如假设某个特征有k个选择,假设有均匀分布,则m=k,p=1/k.
关于特征:
有没有发现在朴素贝叶斯中,我们的特征分量都是离散的可数的选项,而不是任意数值,因为朴素贝叶斯是基于简单的统计,需要的是离散的可统计的数值。
因此在利用朴素贝叶斯时,需要将特征量化,如映射为少数区间;如果数据满足某种分布,则可以直接转化为某种分布的概率。

四、NB与KNN的比较

五、python实现
数据集:
- iHealth data: iHealth.zip
- Republicans or Democrats: house-votes.zip
- Pima Indian Diabetes Small Data Set pimaSmall.zip
- Pima Indian Diabetes Small Data Set pima.zip
- Final Code It challenge: mpgData.zip
1、基本的朴素贝叶斯


# # Naive Bayes Classifier #class Classifier: def __init__(self, bucketPrefix, testBucketNumber, dataFormat): """ a classifier will be built from files with the bucketPrefix excluding the file with textBucketNumber. dataFormat is a string that describes how to interpret each line of the data files. For example, for the iHealth data the format is: "attr attr attr attr class" """ total = 0 classes = {} counts = {} # reading the data in from the file self.format = dataFormat.strip().split('\t') self.prior = {} self.conditional = {} # for each of the buckets numbered 1 through 10: for i in range(1, 11): # if it is not the bucket we should ignore, read in the data if i != testBucketNumber: filename = "%s-%02i" % (bucketPrefix, i) f = open(filename) lines = f.readlines() f.close() for line in lines: fields = line.strip().split('\t') ignore = [] vector = [] for i in range(len(fields)): if self.format[i] == 'num': vector.append(float(fields[i])) elif self.format[i] == 'attr': vector.append(fields[i]) elif self.format[i] == 'comment': ignore.append(fields[i]) elif self.format[i] == 'class': category = fields[i] # now process this instance total += 1 classes.setdefault(category, 0) counts.setdefault(category, {}) classes[category] += 1 # now process each attribute of the instance col = 0 for columnValue in vector: col += 1 counts[category].setdefault(col, {}) counts[category][col].setdefault(columnValue, 0) counts[category][col][columnValue] += 1 # # ok done counting. now compute probabilities # # first prior probabilities p(h) # for (category, count) in classes.items(): self.prior[category] = count / total # # now compute conditional probabilities p(h|D) # for (category, columns) in counts.items(): self.conditional.setdefault(category, {}) for (col, valueCounts) in columns.items(): self.conditional[category].setdefault(col, {}) for (attrValue, count) in valueCounts.items(): self.conditional[category][col][attrValue] = ( count / classes[category]) self.tmp = counts def testBucket(self, bucketPrefix, bucketNumber): """Evaluate the classifier with data from the file bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber) f = open(filename) lines = f.readlines() totals = {} f.close() loc = 1 for line in lines: loc += 1 data = line.strip().split('\t') vector = [] classInColumn = -1 for i in range(len(self.format)): if self.format[i] == 'num': vector.append(float(data[i])) elif self.format[i] == 'attr': vector.append(data[i]) elif self.format[i] == 'class': classInColumn = i theRealClass = data[classInColumn] classifiedAs = self.classify(vector) totals.setdefault(theRealClass, {}) totals[theRealClass].setdefault(classifiedAs, 0) totals[theRealClass][classifiedAs] += 1 return totals def classify(self, itemVector): """Return class we think item Vector is in""" results = [] for (category, prior) in self.prior.items(): prob = prior col = 1 for attrValue in itemVector: if not attrValue in self.conditional[category][col]: # we did not find any instances of this attribute value # occurring with this category so prob = 0 prob = 0 else: prob = prob * self.conditional[category][col][attrValue] col += 1 results.append((prob, category)) # return the category with the highest probability return(max(results)[1]) def tenfold(bucketPrefix, dataFormat): results = {} for i in range(1, 11): c = Classifier(bucketPrefix, i, dataFormat) t = c.testBucket(bucketPrefix, i) for (key, value) in t.items(): results.setdefault(key, {}) for (ckey, cvalue) in value.items(): results[key].setdefault(ckey, 0) results[key][ckey] += cvalue # now print results categories = list(results.keys()) categories.sort() print( "\n Classified as: ") header = " " subheader = " +" for category in categories: header += "% 10s " % category subheader += "-------+" print (header) print (subheader) total = 0.0 correct = 0.0 for category in categories: row = " %10s |" % category for c2 in categories: if c2 in results[category]: count = results[category][c2] else: count = 0 row += " %5i |" % count total += count if c2 == category: correct += count print(row) print(subheader) print("\n%5.3f percent correct" %((correct * 100) / total)) print("total of %i instances" % total)tenfold("house-votes/hv", "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")#c = Classifier("house-votes/hv", 0,# "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")#c = Classifier("iHealth/i", 10,# "attr\tattr\tattr\tattr\tclass")#print(c.classify(['health', 'moderate', 'moderate', 'yes']))#c = Classifier("house-votes-filtered/hv", 5, "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")#t = c.testBucket("house-votes-filtered/hv", 5)#print(t)
2、使用概率密度函数的朴素贝叶斯
# # Naive Bayes Classifier#import mathclass Classifier: def __init__(self, bucketPrefix, testBucketNumber, dataFormat): """ a classifier will be built from files with the bucketPrefix excluding the file with textBucketNumber. dataFormat is a string that describes how to interpret each line of the data files. For example, for the iHealth data the format is: "attr attr attr attr class" """ total = 0 classes = {} # counts used for attributes that are not numeric counts = {} # totals used for attributes that are numereric # we will use these to compute the mean and sample standard deviation for # each attribute - class pair. totals = {} numericValues = {} # reading the data in from the file self.format = dataFormat.strip().split('\t') # self.prior = {} self.conditional = {} # for each of the buckets numbered 1 through 10: for i in range(1, 11): # if it is not the bucket we should ignore, read in the data if i != testBucketNumber: filename = "%s-%02i" % (bucketPrefix, i) f = open(filename) lines = f.readlines() f.close() for line in lines: fields = line.strip().split('\t') ignore = [] vector = [] nums = [] for i in range(len(fields)): if self.format[i] == 'num': nums.append(float(fields[i])) elif self.format[i] == 'attr': vector.append(fields[i]) elif self.format[i] == 'comment': ignore.append(fields[i]) elif self.format[i] == 'class': category = fields[i] # now process this instance total += 1 classes.setdefault(category, 0) counts.setdefault(category, {}) totals.setdefault(category, {}) numericValues.setdefault(category, {}) classes[category] += 1 # now process each non-numeric attribute of the instance col = 0 for columnValue in vector: col += 1 counts[category].setdefault(col, {}) counts[category][col].setdefault(columnValue, 0) counts[category][col][columnValue] += 1 # process numeric attributes col = 0 for columnValue in nums: col += 1 totals[category].setdefault(col, 0) #totals[category][col].setdefault(columnValue, 0) totals[category][col] += columnValue numericValues[category].setdefault(col, []) numericValues[category][col].append(columnValue) # # ok done counting. now compute probabilities # # first prior probabilities p(h) # for (category, count) in classes.items(): self.prior[category] = count / total # # now compute conditional probabilities p(h|D) # for (category, columns) in counts.items(): self.conditional.setdefault(category, {}) for (col, valueCounts) in columns.items(): self.conditional[category].setdefault(col, {}) for (attrValue, count) in valueCounts.items(): self.conditional[category][col][attrValue] = ( count / classes[category]) self.tmp = counts # # now compute mean and sample standard deviation # self.means = {} self.totals = totals for (category, columns) in totals.items(): self.means.setdefault(category, {}) for (col, cTotal) in columns.items(): self.means[category][col] = cTotal / classes[category] # standard deviation self.ssd = {} for (category, columns) in numericValues.items(): self.ssd.setdefault(category, {}) for (col, values) in columns.items(): SumOfSquareDifferences = 0 theMean = self.means[category][col] for value in values: SumOfSquareDifferences += (value - theMean)**2 columns[col] = 0 self.ssd[category][col] = math.sqrt(SumOfSquareDifferences / (classes[category] - 1)) def testBucket(self, bucketPrefix, bucketNumber): """Evaluate the classifier with data from the file bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber) f = open(filename) lines = f.readlines() totals = {} f.close() loc = 1 for line in lines: loc += 1 data = line.strip().split('\t') vector = [] numV = [] classInColumn = -1 for i in range(len(self.format)): if self.format[i] == 'num': numV.append(float(data[i])) elif self.format[i] == 'attr': vector.append(data[i]) elif self.format[i] == 'class': classInColumn = i theRealClass = data[classInColumn] classifiedAs = self.classify(vector, numV) totals.setdefault(theRealClass, {}) totals[theRealClass].setdefault(classifiedAs, 0) totals[theRealClass][classifiedAs] += 1 return totals def classify(self, itemVector, numVector): """Return class we think item Vector is in""" results = [] sqrt2pi = math.sqrt(2 * math.pi) for (category, prior) in self.prior.items(): prob = prior col = 1 for attrValue in itemVector: if not attrValue in self.conditional[category][col]: # we did not find any instances of this attribute value # occurring with this category so prob = 0 prob = 0 else: prob = prob * self.conditional[category][col][attrValue] col += 1 col = 1 for x in numVector: mean = self.means[category][col] ssd = self.ssd[category][col] ePart = math.pow(math.e, -(x - mean)**2/(2*ssd**2)) prob = prob * ((1.0 / (sqrt2pi*ssd)) * ePart) col += 1 results.append((prob, category)) # return the category with the highest probability #print(results) return(max(results)[1]) def tenfold(bucketPrefix, dataFormat): results = {} for i in range(1, 11): c = Classifier(bucketPrefix, i, dataFormat) t = c.testBucket(bucketPrefix, i) for (key, value) in t.items(): results.setdefault(key, {}) for (ckey, cvalue) in value.items(): results[key].setdefault(ckey, 0) results[key][ckey] += cvalue # now print results categories = list(results.keys()) categories.sort() print( "\n Classified as: ") header = " " subheader = " +" for category in categories: header += "% 10s " % category subheader += "-------+" print (header) print (subheader) total = 0.0 correct = 0.0 for category in categories: row = " %10s |" % category for c2 in categories: if c2 in results[category]: count = results[category][c2] else: count = 0 row += " %5i |" % count total += count if c2 == category: correct += count print(row) print(subheader) print("\n%5.3f percent correct" %((correct * 100) / total)) print("total of %i instances" % total)def pdf(mean, ssd, x): """Probability Density Function computing P(x|y) input is the mean, sample standard deviation for all the items in y, and x.""" ePart = math.pow(math.e, -(x-mean)**2/(2*ssd**2)) print (ePart) return (1.0 / (math.sqrt(2*math.pi)*ssd)) * ePart#tenfold("house-votes/hv", "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")#c = Classifier("house-votes/hv", 0,# "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")tenfold("pimaSmall/pimaSmall/pimaSmall", "num num num num num num num num class")tenfold("pima/pima/pima", "num num num num num num num num class")#c = Classifier("iHealth/i", 10,# "attr\tattr\tattr\tattr\tclass")#print(c.classify([], [3, 78, 50, 32, 88, 31.0, 0.248, 26]))#c = Classifier("house-votes-filtered/hv", 5, "class\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr\tattr")#t = c.testBucket("house-votes-filtered/hv", 5)#print(t)
- (数据挖掘-入门-7)朴素贝叶斯
- (数据挖掘-入门-8)基于朴素贝叶斯的文本分类器
- 数据挖掘4---朴素贝叶斯算法
- 数据挖掘经典算法复现:朴素贝叶斯
- 数据挖掘经典算法--朴素贝叶斯分类
- 数据挖掘——贝叶斯公式与朴素贝叶斯分类
- SQL Server 数据挖掘系列(二) - 微软朴素贝叶斯算法
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据挖掘(8):朴素贝叶斯分类算法原理与实践
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据挖掘(8):朴素贝叶斯分类算法原理与实践
- 【数据挖掘】文档分类之朴素贝叶斯算法
- 数据挖掘之朴素贝叶斯算法的实现
- 数据挖掘经典算法之朴素贝叶斯分类器
- 数据挖掘分类方法探究----朴素贝叶斯方法
- 数据挖掘回顾三:分类算法之 朴素贝叶斯 算法
- 数据挖掘经典算法总结-朴素贝叶斯分类器
- 基于.NET实现数据挖掘--朴素贝叶斯算法
- iOS-在Xcode中使用Git进行源码版本控制(二:提交更改)
- 1021. 个位数统计 (15)
- ios 监听文本框文字的变化
- Storm 提交拓扑后UI中spout、bolt的Num都显示为0
- 第15周项目2 用哈希法组织关键字
- (数据挖掘-入门-7)朴素贝叶斯
- 第十六周——【项目1 - 验证算法】
- 1010 一元多项式求导 PAT
- 第四周项目6 多项式求和
- 第14周1-(2)验证分块查找算法
- 第十五周项目7—选择排序之堆排序
- (第十六周项目4)英文单词的基数排序
- HDU 2577 dp 输入法切换最小次 两数组维护两种状态
- 第十六周实践项目--排序


