JobControl的实现原理
来源:互联网 发布:java中类型转换 编辑:程序博客网 时间:2024/05/04 11:32
前面仅是介绍了单一作业的编写方法,很多情况下,用户编写的作业比较复杂,相互之间存在依赖关系,这种依赖关系可以用有向图表示,我们称之为“工作流”。本节将介绍Hadoop工作流的编写方法、设计原理以及实现。
3.5.1 JobControl的实现原理
1. JobControl编程实例
我们以第2章中的贝叶斯分类为例介绍。一个完整的贝叶斯分类算法可能需要4个有依赖关系的MapReduce作业完成,传统的做法是:为每个作业创建相应的JobConf对象,并按照依赖关系依次(串行)提交各个作业,如下所示:
- //为4个作业分别创建JobConf对象
- JobConf extractJobConf = new JobConf(ExtractJob.class);
- JobConf classPriorJobConf = new JobConf(ClassPriorJob.class);
- JobConf conditionalProbilityJobConf = new JobConf(ConditionalProbilityJob.class);
- JobConf predictJobConf = new JobConf(PredictJob.class);
- ...//配置各个JobConf
- //按照依赖关系依次提交作业
- JobClient.runJob(extractJobConf);
- JobClient.runJob(classPriorJobConf);
- JobClient.runJob(conditionalProbilityJobConf);
- JobClient.runJob(predictJobConf);
- 如果使用JobControl,则用户只需使用addDepending()函数添加作业依赖关系接口,JobControl会按照依赖关系调度各个作业,具体代码如下:
- Configuration extractJobConf = new Configuration();
- Configuration classPriorJobConf = new Configuration();
- Configuration conditionalProbilityJobConf = new Configuration();
- Configuration predictJobConf = new Configuration();
- ...//设置各个Configuration
- //创建Job对象。注意,JobControl要求作业必须封装成Job对象
- Job extractJob = new Job(extractJobConf);
- Job classPriorJob = new Job(classPriorJobConf);
- Job conditionalProbilityJob = new Job(conditionalProbilityJobConf);
- Job predictJob = new Job(predictJobConf);
- //设置依赖关系,构造一个DAG作业
- classPriorJob.addDepending(extractJob);
- conditionalProbilityJob.addDepending(extractJob);
- predictJob.addDepending(classPriorJob);
- predictJob.addDepending(conditionalProbilityJob);
- //创建JobControl对象,由它对作业进行监控和调度
- JobControl JC = new JobControl("Native Bayes");
- JC.addJob(extractJob);//把4个作业加入JobControl中
- JC.addJob(classPriorJob);
- JC.addJob(conditionalProbilityJob);
- JC.addJob(predictJob);
- JC.run(); //提交DAG作业
在实际运行过程中,不依赖于其他任何作业的extractJob会优先得到调度,一旦运行完成,classPriorJob和conditionalProbilityJob两个作业同时被调度,待它们全部运行完成后,predictJob被调度。
对比以上两种方案,可以得到一个简单的结论:使用JobControl编写DAG作业更加简便,且能使多个无依赖关系的作业并行运行。
2. JobControl设计原理分析
JobControl由两个类组成:Job和JobControl。其中,Job类封装了一个MapReduce作业及其对应的依赖关系,主要负责监控各个依赖作业的运行状态,以此更新自己的状态,其状态转移图如图3-26所示。作业刚开始处于WAITING状态。如果没有依赖作业或者所有依赖作业均已运行完成,则进入READY状态。一旦进入READY状态,则作业可被提交到Hadoop集群上运行,并进入RUNNING状态。在RUNNING状态下,根据作业运行情况,可能进入SUCCESS或者FAILED状态。需要注意的是,如果一个作业的依赖作业失败,则该作业也会失败,于是形成“多米诺骨牌效应”,后续所有作业均会失败。
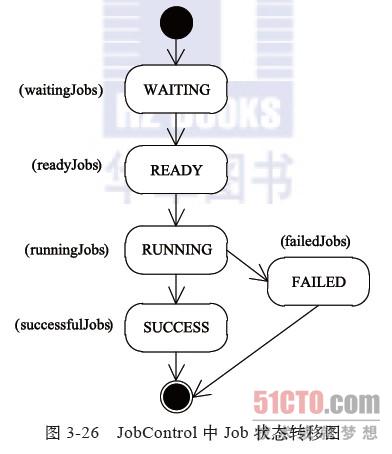
JobControl封装了一系列MapReduce作业及其对应的依赖关系。它将处于不同状态的作业放入不同的哈希表中,并按照图3-26所示的状态转移作业,直到所有作业运行完成。在实现的时候,JobControl包含一个线程用于周期性地监控和更新各个作业的运行状态,调度依赖作业运行完成的作业,提交处于READY状态的作业等。同时,它还提供了一些API用于挂起、恢复和暂停该线程。
- JobControl的实现原理
- jobcontrol
- 如何使用Hadoop的JobControl
- Hadoop的JobControl设计及用法
- JobControl的使用及获取计数器
- Hadoop中JobControl的用法,关于Job迭代
- Hadoop使用JobControl设置job之间的依赖关系
- jobcontrol类
- Hadoop JobControl Job迭代
- Hadoop工作流引擎之JobControl
- WM_COPYDATA的实现原理
- JBPM的实现原理
- XIo的实现原理
- 搜索引擎的实现原理
- 搜索引擎的实现原理
- udev的实现原理
- udev的实现原理
- Random的实现原理
- MapReduce的模式、算法和用例
- Android常见的几种RuntimeException
- SIFT特征提取:SIFT Feature Extraction
- 得到classpath和当前类的绝对路径的一些方法
- [Swift]:快速学习笔记3 类和结构体
- JobControl的实现原理
- 深度卷积网络CNN与图像语义分割
- ion-content 滚动到底部会遮住一部分视图的解决办法
- R语言的科学编程与仿真 chapter 4 答案
- google大牛Jeffrey Dean
- ChainMapper/ChainReducer实现原理
- K近邻算法
- Hadoop工作流引擎
- 关于FPGA中Speed Grade的说明


