Redis源码分析二、Redis简单动态字符串
来源:互联网 发布:数据精灵后台授权 编辑:程序博客网 时间:2024/04/29 00:51
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构建了一种名为简单动态字符串(Simple dynamic string, SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。
1、Redis的使用:
在Redis里面,C字符串只会作为字符串字面量(string literal)用在一些无须对字符串值进行修改的地方,比如打印日志等:
redisLog(REDIS_WARING, "Redis is now ready to exit, bye bye...");
当Reids需要的不仅仅是一个字符串字面量,而是一个可以被修改的字符串值时,Redis就会用SDS来表示字符串值,比如在Redis的数据库里面,包含字符串值的键值对在底层都是由SDS实现的。
举个例子:redis> SET msg "hello world"
OK
那么Redis将子啊数据库中创建一个新的键值对,其中:
- 键值对的键是一个字符串对象,对象的底层实现是一个保存着字符串“msg”的SDS
- 键值对的值也是一个字符串对象,对象的底层实现是一个保存着字符串“hello world”的SDS
redis> RPUSH fruits "apple" "banana" "cherry"
(integer)3
那么Redis将在数据库中创建一个新的键值对,其中:
- 键值对的键是一个字符串对象,对象的底层实现是一个保存了字符串“fruits”的SDS
- 键值对的值是一个列表对象,列表对象包含了三个字符串对象,这是那个字符串对象分别由三个SDS实现:第一个SDS保存着字符串“apple”,第二个SDS保存着字符串“banana”。。。
除了用来保存数据库中的字符串值之外,SDS还用作缓冲区(buffer):AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的,在之后介绍AOF持久化和客户端状态的时候,我们会看到SDS在这两个模块中的应用。
2、SDS的定义:
每个sds.h/sdshdr结构表示一个SDS值:
struct sdshdr { // 记录buf数组中已使用字节的数量 // 等于SDS所保存字符串的长度 int len; // 记录buf数组中未使用字节的数量 int free; // 字节数组,用于保存字符串 char buf[];}; 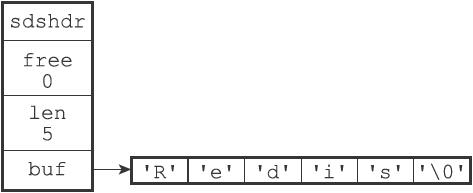
- free属性的值为0,表示这个SDS没有分配任何未使用空间。
- len属性的值为5,表示这个SDS保存了一个五字节长的字符串。
- buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而
- 最后一个字节则保存了空字符'\0'。
SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配
额外的1字节空间,以及添加空字符到字符串末尾等操作,都是由SDS函数自动完成的,所以这个空字符对于SDS
的使用者来说是完全透明的。遵循空字符结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的
函数。
3、SDS与C字符串的区别

3.1常数复杂度获取字符串长度
3.2杜绝缓冲区溢出
除了获取字符串长度的复杂度高之外,C字符串不记录自身长度带来的另一个问题是容易造成缓冲区溢出
(buffer over-flow)。举个例子,<string.h>/strcat函数可以将src字符串中的内容拼接到dest字符串的末尾:
char *strcat(char *dest, const char *src);
因为C字符串不记录自身的长度,所以strcat假定用户在执行这个函数时,已经为dest分配了足够多的内存,可以
容纳src字符串中的所有内容,而一旦这个假定不成立时,就会产生缓冲区溢出。
与C字符串不同,SDS的空间分配策略完全杜绝了发生缓冲区溢出的可能性:当SDS API需要对SDS进行修改时,
API会先检查SDS的空间是否满足修改所需的要求,如果不满足的话,API会自动将SDS的空间扩展至执行修改
所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现前面所
说的缓冲区溢出问题。
3.3减少修改字符串时带来的内存重分配次数
正如前两个小节所说,因为C字符串并不记录自身的长度,所以对于一个包含了N个字符的C字符串来说,这
个C字符串的底层实现总是一个N+1个字符长的数组(额外的一个字符空间用于保存空字符)。因为C字符串
的长度和底层数组的长度之间存在着这种关联性,所以每次增长或者缩短一个C字符串,程序都总要对保存这
个C字符串的数组进行一次内存重分配操作:
在一般程序中,如果修改字符串长度的情况不太常出现,那么每次修改都执行一次内存重分配是可以接受的。
但是Redis作为数据库,经常被用于速度要求严苛、数据被频繁修改的场合,如果每次修改字符串的长度都
需要执一次内存重分配的话,那么光是执行内存重分配的时间就会占去修改字符串所用时间的一大部分,如果
这种修改频繁地发生的话,可能还会对性能造成影响。通过未使用空间,SDS实现了空间预分配和惰性空间释放
两种优化策略。
1)空间预分配
空间预分配用于优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展
的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空间。
其中,额外分配的未使用空间数量由以下公式决定:
- 如果对SDS进行修改之后,SDS的长度(也即是len属性的值)将小于1MB,那么程序分配和len属性同样大小
- 未使用空间,这时SDS len属性的值将和free属性的值相同。举个例子,如果进行修改之后,SDS的len将变成
- 13字节,那么程序也会分配13字节的未使用空间,SDS的buf数组的实际长度将变成13+13+1=27字节(额外的一字节用于保存空字符)。
- 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。举个例子,如
- 果进行修改之后,SDS的len将变成30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际长度将
- 为30MB+1MB+1byte。
2)惰性空间释放
3.4二进制安全
- Redis源码分析二、Redis简单动态字符串
- Redis源码剖析和注释(二)--- 简单动态字符串
- redis源码分析(二)、sds动态字符串学习总结
- redis源码分析之简单动态字符串sds
- Redis源码剖析--简单动态字符串sds
- Redis源码剖析--简单动态字符串sds
- 【redis源码分析】动态字符串--sds
- redis 学习笔记二 (简单动态字符串)
- Redis-简单动态字符串
- Redis 简单动态字符串
- redis 简单动态字符串
- Redis-简单动态字符串
- Redis源码分析(五)——简单动态字符串(sds)
- redis源码分析(二)、redis源码分析之sds字符串
- Redis源码解析:01简单动态字符串SDS
- redis源码学习之sds简单动态字符串
- Redis中的简单动态字符串
- Redis之简单动态字符串
- UIPickerView内容居中显示,设置初始默认值
- 如何一次退出多个Activity
- 获取当前系统时间作为文件名
- 两个链表的交叉——值得注意的错误
- Heritrix3.3.0源码阅读 允许重复下载
- Redis源码分析二、Redis简单动态字符串
- sqlite3.OperationalError: unable to open database file
- 使用FMS 4.5(Flash Media Server 4.5) 搭建视频直播(HLS)
- 各类demo链接
- PostgreSQL学习手册(函数和操作符<三>)
- Spring事务配置的五种方式
- Java集合:树
- Spark API 详解/大白话解释 之 map、mapPartitions、mapValues、mapWith、flatMap、flatMapWith、flatMapValues
- jenkins安装插件后,页面找不到效果


