【源】从零自学Hadoop(08):第一个MapReduce
来源:互联网 发布:淘宝关键词广告 编辑:程序博客网 时间:2024/05/08 23:26
- 序
- 数据准备
- wordcount
- Yarn
- 新建MapReduce
- 示例下载
- 系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们的Eclipse插件搞定,那开始我们的MapReduce之旅。
在这里,我们先调用官方的wordcount例子,然后再手动创建个例子,这样可以更好的理解Job。
数据准备
一:说明
wordcount这个类是对不同的word进行统计个数,所以这里我们得准备数据,当然也不需要很大的数据量,毕竟是自己做试验对吧。
二:造数据
打开记事本,输入各种word,有相同的,不同的。然后保存为words_01.txt。
三:上传
打开eclipse,然后在DFS location 中将我们准备的数据源上传到tmp/input。
这样我们的数据就准备好了。


wordcount
一:官网示例
wordcount是hadoop的一个官网试例,打包在hadoop-mapreduce-examples-<ver>.jar。
2.7.1版本的地址:http://hadoop.apache.org/docs/r2.7.1/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
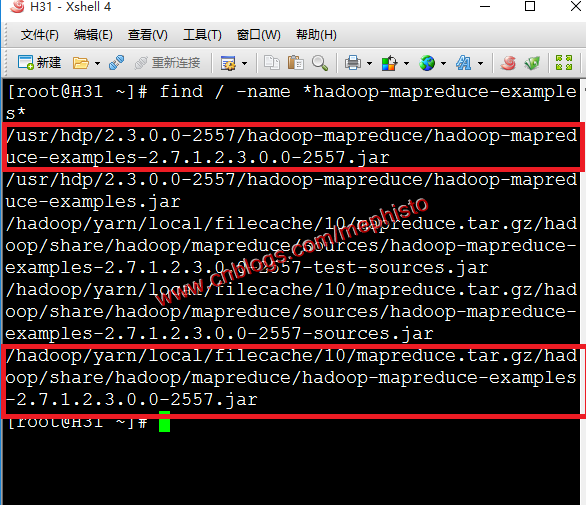
二:找到示例
我们在结果中看到两个地方有,那就找个近一点的地方吧。
find / -name *hadoop-mapreduce-examples*
四:进入目录
我们选择进入/usr/hdp/下面的这个例子。
cd /usr/hdp/2.3.0.0-2557/hadoop-mapreduce五:执行
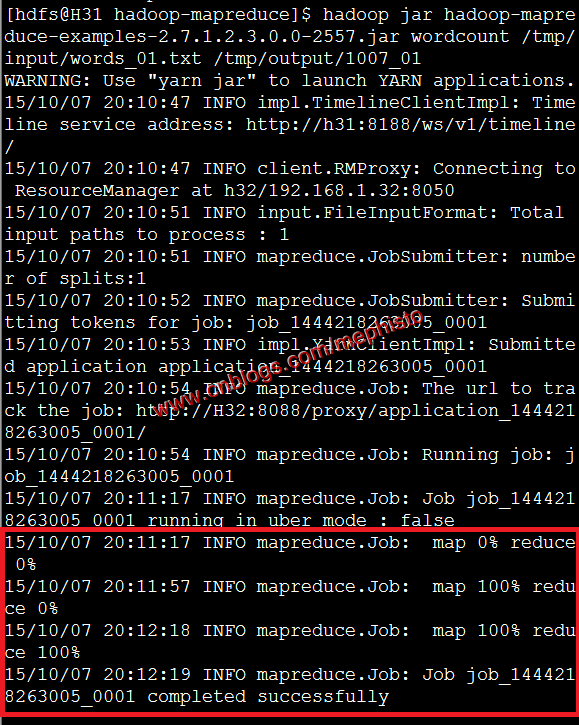
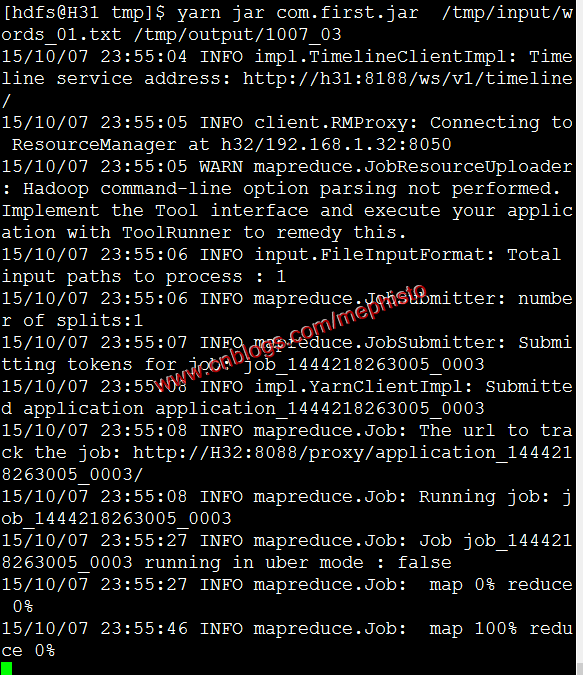
我们先使用hadoop jar这个命令执行。
命令说明:hadoop jar 包名称 方法 输入文件/目录 输出目录
#切换用户su hsfs#执行hadoop jar hadoop-mapreduce-examples-2.7.1.2.3.0.0-2557.jar wordcount /tmp/input/words_01.txt /tmp/output/1007_01命令执行结果
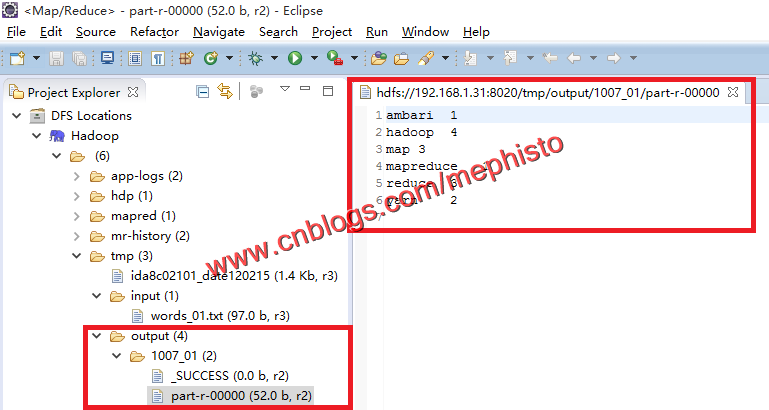
插件结果
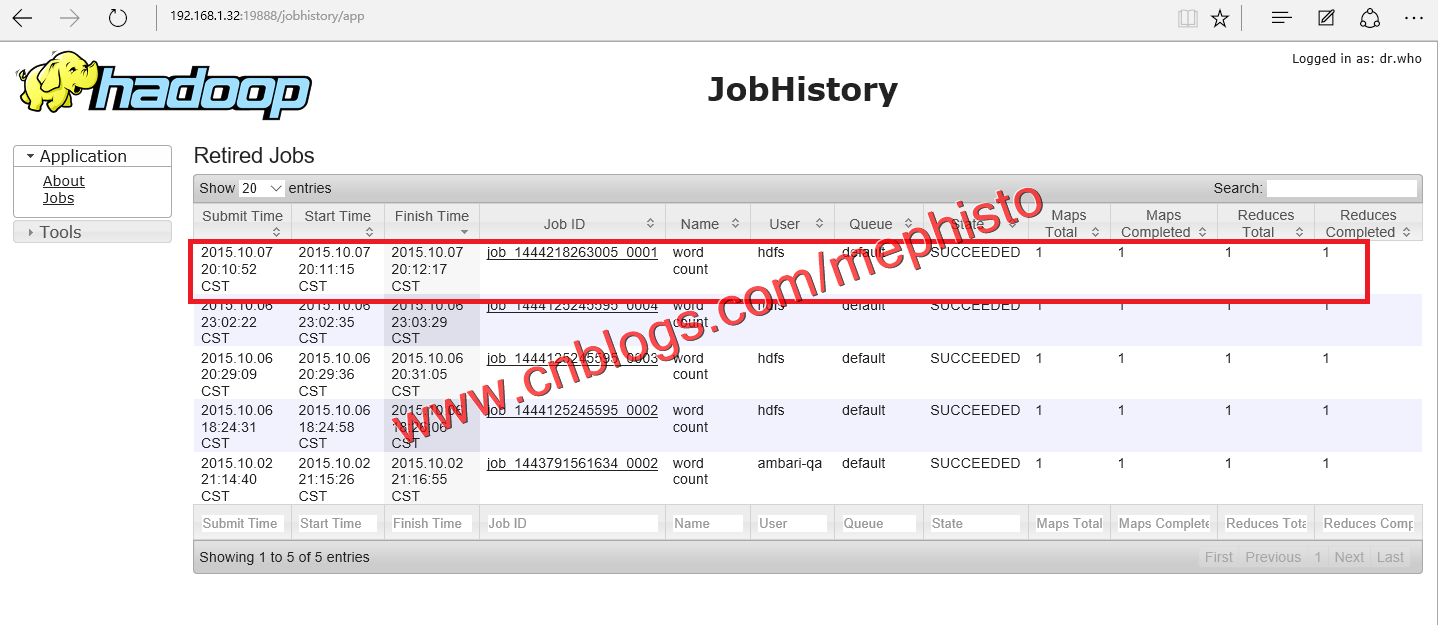
job页面结果
这样我们的第一个job就这样顺利的执行完成了。
Yarn
一:介绍
Hadoop2.X和Hadoop1.X有两个最大的变化,也是根本性变化。
其中一个是Namenode的单点问题解决,然后就是Yarn的引入。在这里我们就不做展开的讲了,后面会安排章节进行讲述。
二:Yarn命令
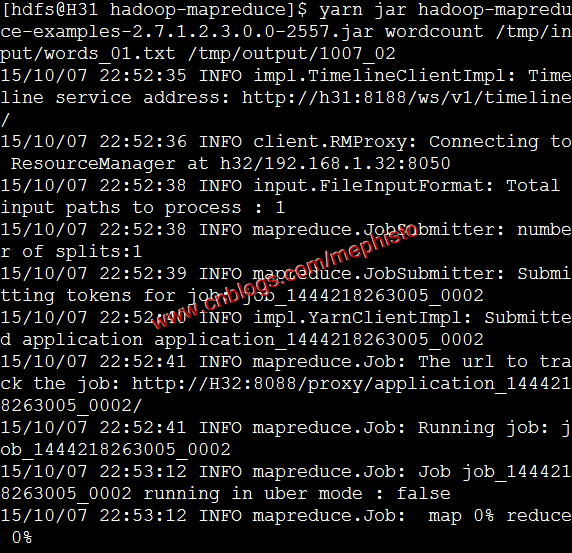
如果仔细看的话,我们可以发现在上面hadoop jar这个命令执行后,会有一个警告。
yarn jar hadoop-mapreduce-examples-2.7.1.2.3.0.0-2557.jar wordcount /tmp/input/words_01.txt /tmp/output/1007_02
新建MapReduce
一:通过插件新建工程
这里就不详说了,在上一篇我们通过插件建立了一个工程,我们直接使用那个工程“com.first”。
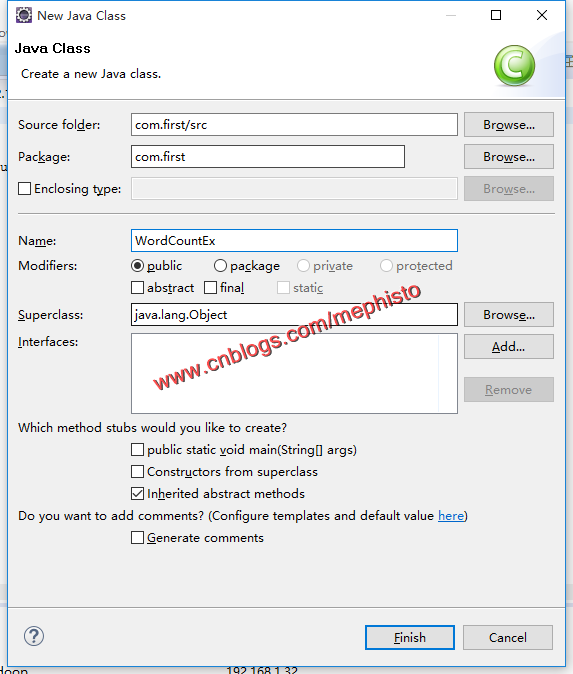
二:新建WordCountEx类
这个是我们的自定义的wordcount类,仿照官网例子写的,做了点DIY,方便大家理解。
完成后
三:新建Mapper
在WordCountEx类中建一个内部类MyMapper。
在这里我们做了点DIY,排除了字母长度小于5的数据,方便大家对比理解程序。
View Codestatic class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 分割字符串 StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { // 排除字母少于5个的 String tmp = itr.nextToken(); if (tmp.length() < 5) continue; word.set(tmp); context.write(word, one); } } }四:新建Reduce
同上,我们将map的结果乘以2,然后输出的内容的key加了个前缀。
View Codestatic class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); private Text keyEx = new Text(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { // 将map的结果放大,乘以2 sum += val.get() * 2; } result.set(sum); // 自定义输出key keyEx.set("输出:" + key.toString()); context.write(keyEx, result); } }五:新建Main
在main方法中我们得定义一个job,配置它。
View Codepublic static void main(String[] args) throws Exception { //配置信息 Configuration conf = new Configuration(); //job名称 Job job = Job.getInstance(conf, "mywordcount"); job.setJarByClass(WordCountEx.class); job.setMapperClass(MyMapper.class); // job.setCombinerClass(IntSumReducer.class); job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //输入、输出path FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //结束 System.exit(job.waitForCompletion(true) ? 0 : 1); }六:导出jar包
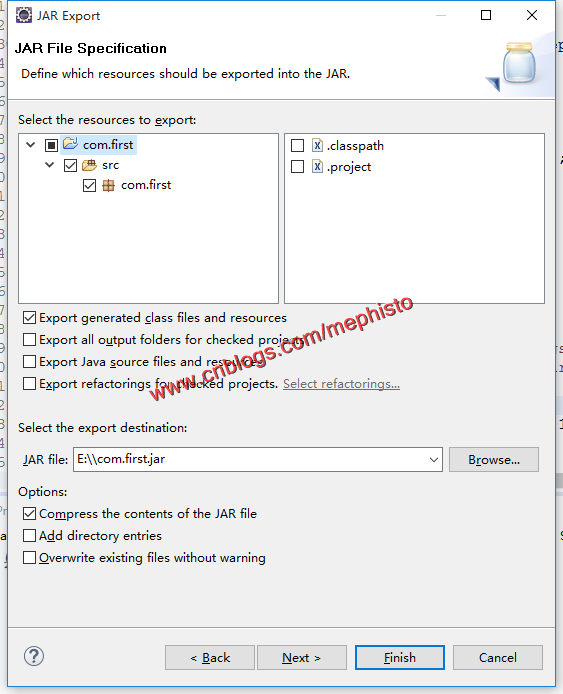
导出我们写好的jar包。命名为com.first.jar
七:放入Linux
将导出的jar包放到H31的/var/tmp下
cd /var/tmp
ls八:执行
大家仔细看下命令和结果会发现有什么不同
yarn jar com.first.jar /tmp/input/words_01.txt /tmp/output/1007_03
如果是仔细看了,发现少个wordcount对吧,为什么列,因为在导出jar包的时候制定的main函数。
九:导出不指定main入口的jar包
我们在导出的时候,不指定main的入口。
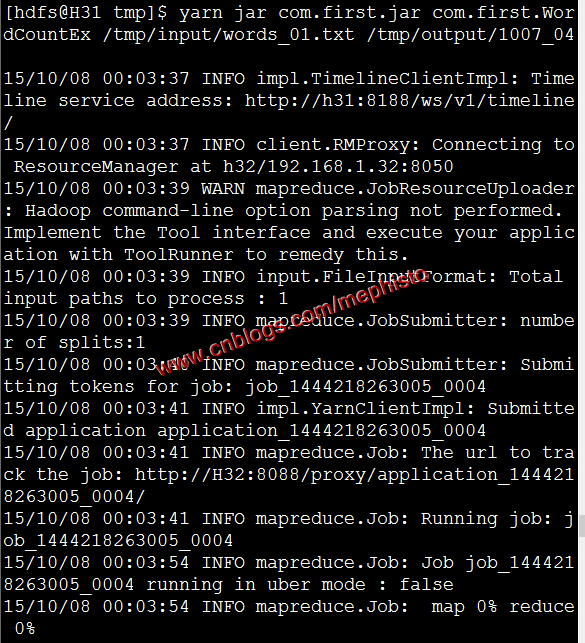
十:执行2
我们发现这里就得多带一个参数了,就是方法的入口,这里得全路径。
yarn jar com.first.jar com.first.WordCountEx /tmp/input/words_01.txt /tmp/output/1007_04
十一:结果
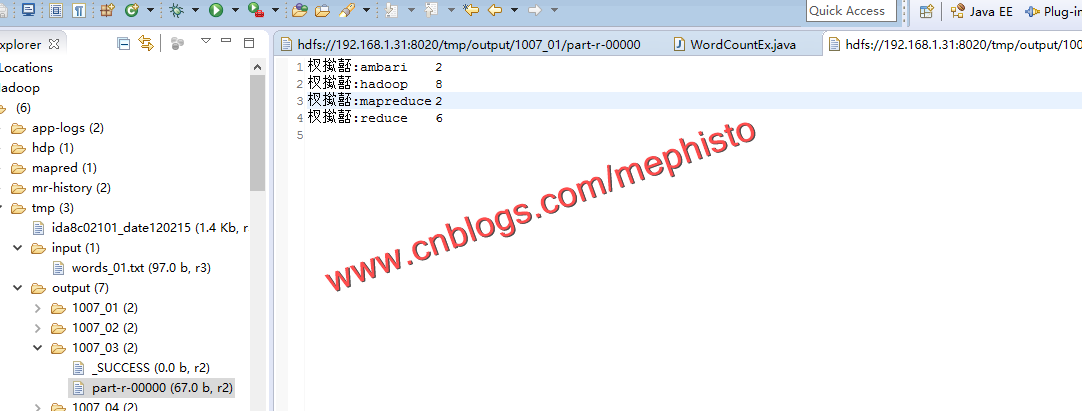
我们看下输出的结果,可以明显的看到少于5个长度的被排除了,而且结果的count都乘以了2。前缀乱码的不要纠结了,换个编码方式就好了。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。


示例下载
Github:https://github.com/sinodzh/HadoopExample/tree/master/2015/com.first
系列索引
【源】从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
- 【源】从零自学Hadoop(08):第一个MapReduce
- 【源】从零自学Hadoop(05):Ambari
- 【源】从零自学Hadoop(01):认识Hadoop
- 【源】从零自学Hadoop(11):Hadoop命令上
- 【源】从零自学Hadoop(12):Hadoop命令中
- 【源】从零自学Hadoop(13):Hadoop命令下
- 【源】从零自学Hadoop(07):Eclipse插件
- 【源】从零自学Hadoop(02):环境准备
- 【源】从零自学Hadoop(03):Linux准备上
- 【源】从零自学Hadoop(04):Linux准备下
- 【源】从零自学Hadoop(06):集群搭建
- 【源】从零自学Hadoop(07):Eclipse插件
- 【源】从零自学Hadoop(14):Hive介绍及安装
- 【源】从零自学Hadoop(15):Hive表操作
- [置顶]【源】从零自学Hadoop系列索引
- 【源】从零自学Hadoop(09):使用Maven构建Hadoop工程
- 从零自学Hadoop(11):Hadoop命令上
- 从零自学Hadoop(12):Hadoop命令中
- 关于以dll调用dll的几个小问题
- 【源】从零自学Hadoop(06):集群搭建
- 希尔塔网络科技(外包)公司开技术博客啦!
- 【源】从零自学Hadoop(07):Eclipse插件
- 关于“闭包”的杂文
- 【源】从零自学Hadoop(08):第一个MapReduce
- 【源】从零自学Hadoop(09):使用Maven构建Hadoop工程
- 【源】从零自学Hadoop(10):Hadoop1.x与Hadoop2.x
- 【源】从零自学Hadoop(11):Hadoop命令上
- 【源】从零自学Hadoop(12):Hadoop命令中
- 【源】从零自学Hadoop(13):Hadoop命令下
- 【源】从零自学Hadoop(14):Hive介绍及安装
- 【源】从零自学Hadoop(15):Hive表操作
- Ubuntu 64位adb无法使用问题的解决


