机器学习算法-Mean-shift
来源:互联网 发布:我是未来 阿里云 编辑:程序博客网 时间:2024/05/16 19:42
mean-shift算法是一种在一组数据的密度分布中寻找局部极值的稳定的无参特征空间估计方法(non-parametric feature-space analysis)。
“稳定”是指统计意义上的稳定,因为mean-shift忽略了数据中的outlier,即忽略原理数据峰值的点。mean-shift只对数据局部窗口中的点进行处理,处理完成后再移动窗口。
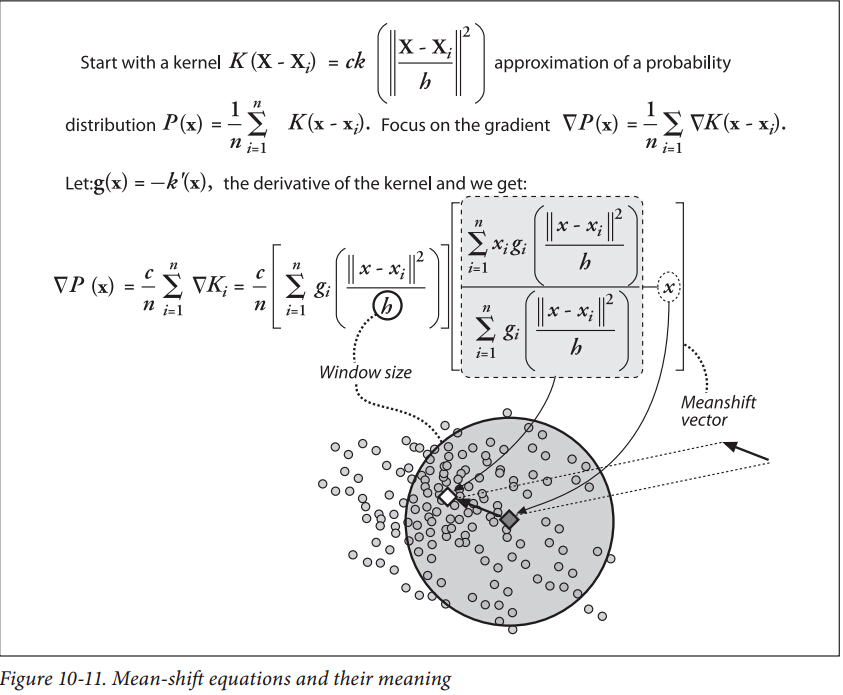
Kernel Density Estimation(核密度估计)
核密度估计是在概率中用来估计未知的密度函数,又名Parzen窗(Parzen window),由Rosenblatt (1955)和Emanuel Parzen(1962)提出,基本思想是利用一定范围内各点密度的平均值对总体密度函数进行估计。
在贝叶斯统计中,概率密度函数(probability density function)的核:the form of the pdf in which any factors that are not functions of any of the variables in the domain are omitted。这些factors是pdf参数的函数,组成了概率分布的归一化因子。
比如,正态分布的pdf和对应的核分别为(
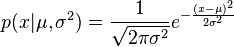 ;
; 
一般而言,设
其中,
核函数的选取
一般可以选择的核函数有方窗、正态窗,指数窗函数等。正态窗函数为
则概率密度的估计为
一个一维数据的实验:
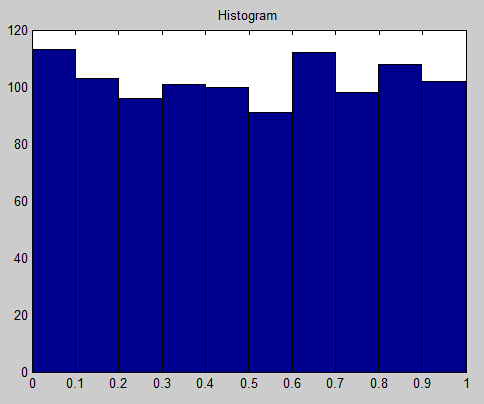
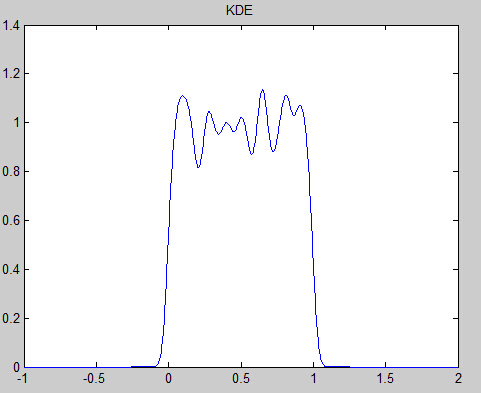
对于mean-shift,将数据表示为点。我们认为这些数据采样于一个概率分布,KDE采用平滑的峰值函数(“核”)来拟合观察到的数据点,从而对真实的概率分布曲线进行模拟。

“核”是一个局部函数(例如高斯分布)。如果在足够的点处有足够合适的带权重和尺度的核,数据的分布便可以完全根据这些核来表示。将这些分布的核叠加组成一个概率表面(probability surface),取决于选取的核带宽参数,相应的密度函数会发生变化。
下图所示为点集使用核带宽为2的高斯核的KDE surface及等高线图。


Mean shift
将每个点迭代地进行爬山算法直到其到达一个局部最优解(peak)。极端情况下,采用非常tall and tinny kernels(即很小的核带宽),KDE surface对于每一个点都有一个peak,也就是每个点都属于其自身的聚类。同理,采用extremely short fat kernels (e.g., 即很大的核带宽),会导致所有的点爬山到同一个peak,从而只有一个聚类。如下图,上面的仿真结果会形成3个KDE surface peaks即三个聚类中心,采用较小的核带宽,会产生更多的聚类中心。


爬山算法
一种简单的贪心搜索算法,该算法每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解。爬山算法实现很简单,其主要缺点是会陷入局部最优解,而不一定能搜索到全局最优解。如图1所示:假设C点为当前解,爬山算法搜索到A点这个局部最优解就会停止搜索,因为在A点无论向那个方向小幅度移动都不能得到更优的解。

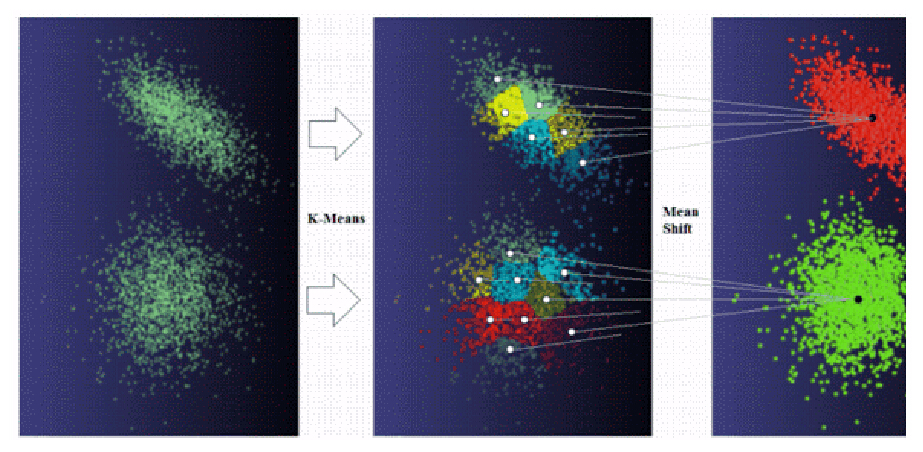
K-means 与Mean Shift Clustering的结合
K-means算法应用非常广泛,而mean-shift的应用比较局限(比如在图像分割领域)。
Mean Shift算法的缺陷:
- calculation intensive,一般需要
O(kN2 的计算复杂度(主要用于计算欧式距离),N 为样本数,k 为每个数据点的平均迭代次数。 - Rely on sufficient high data density with clear gradient to locate the cluster centers。因而其对一些data outliers 无法找到合适的聚类。即一些小的不确定的聚类。
K-means算法没有以上缺陷,其通常只需要
- 其需要实现确定聚类数目,实际应用中很难操作,所以一般只能选足够大的聚类数目,这就导致一些自然的聚类会被多个聚类所表示
- K-means无法找到non-convex cluster,k-means的聚类会对数据空间形成voronoi 分割。所以限制了k-means对于一些复杂的非线性数据的适用性。
但是,我们可以将它们结合起来来克服先前提到的问题。首先对数据集做K-means;然后我们在找到的聚类中心上做mean shift操作,由于现在的输入数据远小于原始数据,mean-shift可以较快地完成。
K-means并不知道正确的聚类数目,所以会选择一个较大的聚类数目。Mean Shift将合适的聚类中心合并来匹配自然的聚类。
K-means算法产生的聚类一般位于高密度空间,所以Mean Shift也就不会产生一些小的不确定的聚类。
同时,两者的结合可以解决非凸聚类的寻找问题。
- 机器学习算法-Mean-shift
- 机器学习(十)Mean Shift 聚类算法
- 机器学习-Mean shift算法详解和实现
- 机器学习(十)Mean Shift 聚类算法
- 简单易学的机器学习算法——Mean Shift聚类算法
- 简单易学的机器学习算法——Mean Shift聚类算法
- 简单易学的机器学习算法——Mean Shift聚类算法
- Mean Shift算法(CamShift)
- Mean Shift 算法总结
- Mean Shift算法
- mean shift 跟踪算法
- Mean-Shift算法
- Mean Shift算法
- Mean Shift算法介绍
- Mean shift 算法
- Mean Shift算法
- mean shift算法详细
- Mean-Shift算法
- 安卓初学一之布局RelativeLayout和linearlayout
- Android 4.4KK系统关机流程分析
- Masonry
- BouncyCastle产生一个PKCS#12规范的PFX/p12证书【自用笔记】
- ROS_OpenCV_socket传送图像_结果不对
- 机器学习算法-Mean-shift
- unity开发相关环境(vs、MonoDevelop)行结尾符不一致解决办法
- oracle 求两个时间点直接的分钟、小时数
- 游戏中常见的洗牌算法
- SLRequest
- git学习笔记(一)
- UTF-8和GBK互转
- spring巧用继承解决bean的id相同的问题
- Realm简单入门(转载)


