图知识
来源:互联网 发布:淘宝网图标图片大全 编辑:程序博客网 时间:2024/05/18 15:30
图的基本知识
版权声明:本文为博主原创文章,未经博主允许不得转载。
=================================图的定义和术语=============================
图是一种基本的数据结构,表示为 ,其中
,
表示图的顶点集;
,
表示边(弧)集,
连接顶点
,当
为无序对时,表示无向图; 若
为有序对,则
表示以顶点
为起始点指向
的一条边,此时的图称为有向图;当每条边关联一个非负权重
时,称为加权图。顶点的度:
,表示和顶点
相关联的边的权重之和,当是无权图时表示和顶点
相关联的边的数目,则图的degree matrix
,
为对角阵,对角元素为
;在有向图中,顶点的度又分为出度
和入度
,其中出度表示以顶点
为起始点的所有相关联边的权重之和,入度表示以顶点
为终点的所有相关联边的权重之和。
子图:若存在图,且
,则称
是
的子图。
完全图:图的任意两个不同顶点之间都存在一条边则称为完全图,无向完全图的边数目为,有向完全图的边数为
。
路径、回路:若从顶点到顶点
存在一个顶点序列
,其中
,则称
,
间存在路径,路径长度就是路径上边的数目。当图是有向图时,顶点序列也必须是有向的。当第一个顶点和最后一个相同时,则称此路径为回路。
连通图:若图中的任意两个顶点都存在路径,则称为联通图,在有向图中,若从到
以及从
到
都存在路径,则称为强连通图
PS.
以下都是按加权图进行介绍,当为无权图时,若 则令
,否则
。
=============================图的存储====================================
1. 邻接矩阵表示
邻接矩阵用表示,是一个
的矩阵,其中每个元素表示为
。
2. 邻接表
对每个顶点,建立一个单链表,链表中的节点表示和此顶点相关联的边,可有效解决稀疏邻接矩阵的问题。
其基本数据结构:
定义头结点:vexdata | firstarc ,定义邻接点:adjdata | inf | nextarc :
对于有向图,通常按顶点的出度进行构建的邻接表(每个顶点的链表结点数是顶点的初度),若按顶点的入度进行构建,则称为逆邻接表。分别用无向图和有向图构建邻接表,如下图所示:
(1) 无向加权图

对应的邻接表为:

(2) 有向加权图

对应的邻接表为:

逆邻接表为:

3. 十字链表
专门为有向图设计的一种链式存储结构,融合了邻接表和逆邻接表的结构, 可方便的求取某个顶点的出度和入度:
定义顶点:data | firstin| firstout ,定义边:tailvex |headvexz | inf | hlink | tlink
在顶点结点中有三个域:data域存储和顶点相关的信息,如顶点编号等;firstin和firstout为两个链域,分别指向以该结点为弧头和弧尾的第一个结点。
在边结点中有五个域:尾域(tailvex)和头域(headvex)分别表示弧尾和弧头这两个顶点在图中的的编号,inf包含边的信息如权重,链域hlink指向弧头相同的下一条弧,而链域tlink指向弧尾相同的下一条弧。
对于上述的有向加权图,其对应的十字链表表示为:

4. 邻接多重图
邻接多重图是无向图的一种存储结构,类似于有向图的十字链表表示方式,也是采用顶点与边的链表结构进行存储:
定义顶点: data | firstedge , 定义边: mark | ivex | ilink | jvex | jlink | inf
在顶点结点中有两个域:data域存储和顶点相关的信息,如顶点编号等;firstedge为链域,指向以和该结点相关联的第一条边。
在边结点中有六个域:mark为标记域,指示此边是否被搜索过,ivex和jvex分别表示和此边关联的两个顶点在图中的的编号,ilink指向和顶点ivex相关联的下一条边,ilink指向和顶点jvex相关联的下一条边,inf包含边的信息如权重。
================================图的遍历===================================
1. 深度优先搜索(Depth Fisrst Search)
从图中某个顶点 出发,访问此顶点,然后依次从
的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和
有路径相通的顶点都被访问到。
- //顶点Structure
- struct VexNode{
- int vexdata;
- struct EdgeNode *firstarc;
- }EdgeNode;
- //邻接点Structure
- struct EdgeNode{
- int adjdata;
- float inf;
- struct EdgeNode *nextarc;
- }EdgeNode;
采用邻接表表示的无向图的DFS遍历:
- void DFSTraverse(Graph *G)
- {
- int v = 0;
- for (v = 0; v < G.vexnum; v++)
- visited[v] = FALSE; // 访问标志数组初始化
- for (v=0; v<G.vexnum; ++v)
- {
- if (!visited[v])
- DFS_Recursive(G, v) ; // 对尚未访问的顶点调用DFS_Recursive
- }
- }
递归遍历:
- //从顶点v出发,递归遍历所有和v连通的顶点
- void DFS_Recursive(Graph *G, int v, bool visited[])
- {
- VisitFunc(v); //访问顶点v
- visited[v] = true;
- EdgeNode *p= G[v].firstarc;
- while(p != NULL)
- {
- if(!visited[p->adjdata])
- DFS_Recursive(G, p, visited); //访问未被访问的邻接顶点
- p = p->nextarc;
- }
- }
非递归遍历:
- //采用辅助栈实现非递归DFS遍历
- void DFS_Non_Recursive(Graph *G, int v, bool visited[])
- {
- stack<int> s;
- s.push(v);
- while(!s.empty())
- {
- int node = s.top();
- s.pop();
- if(!visited[node])
- {
- VisitFunc(node);
- visited[node] = true;
- EdgeNode *p= G[node].firstarc;
- while(p != NULL)
- {
- if(!visited[p->adjdata]) //将所有未被访问的邻接顶点压栈
- s.push(p->adjdata);
- p = p->nextarc;
- }
- }
- }
- }
2. 广度优先搜索(Breadth_First Search)
从某个顶点出发,访问此顶点,之后依次访问
的所有未被访问过的邻接点,之后按这些顶点被访问的先后次序依次访问它们的邻接点,直至图中所有和
有路径相通的顶点都被访问到。
- //采用辅助队列实现非递归BFS遍历
- void DFS_Non_Recursive(Graph *G, int v, bool visited[])
- {
- queue <int> q;
- VisitFunc(v);
- visited[v] = true;
- q.push(v);
- while(!q.empty())
- {
- int node = q.front();
- q.pop();
- EdgeNode *p= G[node].firstarc;
- while(p != NULL)
- {
- if(!visited[p->adjdata]) //将所有未被访问的邻接顶点加入队列
- {
- VisitFunc(p->adjdata);
- visited[p->adjdata] = true;
- q.push(p->adjdata);
- }
- p = p->nextarc;
- }
- }
- }
- void BFSTraverse(Graph *G)
- {
- int v = 0;
- for (v = 0; v < G.vexnum; v++)
- visited[v] = FALSE; // 访问标志数组初始化
- for (v=0; v<G.vexnum; ++v)
- {
- if (!visited[v])
- BFS_Non_Recursive(G, v) ; // 对尚未访问的顶点调用BFS_Non_Recursive
- }
- }
参考文献
[1] http://www.xinx.sdnu.edu.cn/sfzx/jpsykc/zzh/zzh07.html#(28)
[2] http://comic.sjtu.edu.cn/thucs/GD_jsj_002b/text/chapter07/
最近看了一些矩阵和谱聚类的知识,特在此简单记录一下。详细可以先看下参考文献。
首先看到的是孟岩写的三篇<理解矩阵>.
一:理解矩阵(一)
1:传统书籍空间的定义:存在一个集合,在这个集合上定义某某概念,然后满足某些性质”,就可以被称为空间。孟的空间包含四点:(1). 由很多(实际上是无穷多个)位置点组成;(2). 这些点之间存在相对的关系;(3). 可以在空间中定义长度、角度;4.这个空间可以容纳运动,这里我们所说的运动是从一个点到另一个点的移动(变换),而不是微积分意义上的“连续”性的运动。其中第四点最为重要,容纳运动时空间的本质。
2:“空间”是容纳运动的一个对象集合,而变换则规定了对应空间的运动。
3:线性空间中的任何一个对象,通过选取基和坐标的办法,都可以表达为向量的形式。
4:在线性空间中,当你选定一组基之后,不仅可以用一个向量来描述空间中的任何一个对象,而且可以用矩阵来描述该空间中的任何一个运动(变换)。而使某个对象发生对应运动的方法,就是用代表那个运动的矩阵,乘以代表那个对象的向量。矩阵的本质是运动的描述。
二:理解矩阵(二)
1:所谓变换,其实就是空间里从一个点(元素/对象)到另一个点(元素/对象)的跃迁。矩阵是线性空间里的变换的描述
2:对于一个线性变换,只要你选定一组基,那么就可以找到一个矩阵来描述这个线性变换。换一组基,就得到一个不同的矩阵。所有这些矩阵都是这同一个线性变换的描述,但又都不是线性变换本身。
3:所谓相似矩阵,就是同一个线性变换的不同的描述矩阵。如同对同一对象的多个引用。
三:理解矩阵(三)
1:对象的变换等价于坐标系的变换。或者说:固定坐标系下一个对象的变换等价于固定对象所处的坐标系变换。
三篇矩阵系列让我们从直觉上再度理解了矩阵,形象深刻。第一篇可以说是初谈空间与矩阵;第二篇相当于矩阵再描述;第三篇则为矩阵等价于坐标系。
四:谱聚类
在谈及谱聚类的问题时,首先需要回顾一些数学知识。
1:正交矩阵。ATA=E,则A为正交矩阵。也就是A的行或者列向量为两两垂直的单位向量
2:正定矩阵。如果对于任意向量f,都有fTMf> 0, 则称M为正定矩阵。如果为大于等于0,则为半正定矩阵。
3:拉普拉斯矩阵:Laplace矩阵为图的度矩阵-图的邻近矩阵。它也是谱理论的基础。
其中:

定义:
方阵的谱: 方阵作为线性算子,它的所有特征值的集合成为方阵的谱。
3:谱聚类最初用于解决图的分割为题,图分割的目的是类间相似性最小,类内相似性最大。它是一个NP难解问题,它可以转换为最小化图的Laplace矩阵的特征值的问题,这个可以通过公式进行证明。如果分两类的话,此时最小的特征值所对应的特征向量中大于0的归属于一类,小于0的归属于另一类,就可以将图分割成为两部分了。
如果进行k分类,则需要得到k个最小的特征值所对应的特征向量(N×k),每列为一个特征向量,每行代表一个样本点,此时对它进行k-means聚类,就可以将N个点聚成k类了。
4:谱聚类用于实际样本空间,只需将每个样本看做图的一个顶点,再将样本点的距离通过高斯核函数(径向基核函数)映射为相似性,每个点与其它点相似和为度就可以进行谱聚类了。
5:优点:(1)谱聚类能在任意形状的样本空间上进行聚类,且收敛于全局最优点。而像k-means算法和EM算法是建立在凸球形的样本空间上,当样本空间不凸时,算法会陷入“局部”最优。
(2) 谱聚类只需要数据之间的相似度矩阵就可以了,而不必像K-means那样要求数据必须是 N 维欧氏空间中的向量。
(3)RatioCut方法只考虑了类间相似性最小,而normalizedCut不仅考虑了类间还考虑了类内的相似性。
五:谱哈希
待续.....
参考文献:
1:理解矩阵(一)http://blog.csdn.net/myan/article/details/647511
2:理解矩阵(二) http://blog.csdn.net/myan/article/details/649018
3:理解矩阵(三) http://blog.csdn.net/myan/article/details/1865397
4:july的http://blog.csdn.net/v_july_v/article/details/40738211从拉普拉斯矩阵说到谱聚类
5:机器学习中谱聚类方法的研究:http://lamda.nju.edu.cn/conf/MLA07/files/YuJ.pdf;
从谱聚类说到拉普拉斯矩阵
0 引言
11月1日上午,机器学习班第7次课,邹博讲聚类(PPT),其中的谱聚类引起了自己的兴趣,他从最基本的概念:单位向量、两个向量的正交、方阵的特征值和特征向量,讲到相似度图、拉普拉斯矩阵,最后讲谱聚类的目标函数和其算法流程。
课后自己又琢磨了番谱聚类跟拉普拉斯矩阵,打算写篇博客记录学习心得, 若有不足或建议,欢迎随时不吝指出,thanks。
1 矩阵基础
在讲谱聚类之前,有必要了解一些矩阵方面的基础知识。
1.0 理解矩阵的12点数学笔记
如果对矩阵的概念已经模糊,推荐国内一人写的《理解矩阵by孟岩》系列,其中,抛出了很多有趣的观点,我之前在阅读的过程中做了些笔记,如下:
“1、事实上,简而言之:矩阵是线性空间里的变换的描述,相似矩阵则对同一个线性变换的不同描述。那,何谓空间?本质而言,”空间是容纳运动的一个对象集合,而变换则规定了对应空间的运动”by孟岩。在线性空间选定基后,向量刻画对象的运动,运动则通过矩阵与向量相乘来施加。然,到底什么是基?坐标系也。
3、前面说了基,坐标系也,形象表述则为角度,看一个问题的角度不同,描述问题得到的结论也不同,但结论不代表问题本身,同理,对于一个线性变换,可以选定一组基,得到一个矩阵描述它,换一组基,得到不同矩阵描述它,矩阵只是描述线性变换非线性变换本身,类比给一个人选取不同角度拍照。
4、前面都是说矩阵描述线性变换,然,矩阵不仅可以用来描述线性变换,更可以用来描述基(坐标系/角度),前者好理解,无非是通过变换的矩阵把线性空间中的一个点给变换到另一个点上去,但你说描述基(把一个坐标系变换到另一个坐标系),这可又是何意呢?实际上,变换点与变换坐标系,异曲同工!
(@坎儿井围脖:矩阵还可以用来描述微分和积分变换。关键看基代表什么,用坐标基就是坐标变换。如果基是小波基或傅里叶基,就可以用来描述小波变换或傅里叶变换)
5、矩阵是线性运动(变换)的描述,矩阵与向量相乘则是实施运动(变换)的过程,同一个变换在不同的坐标系下表现为不同的矩阵,但本质/征值相同,运动是相对的,对象的变换等价于坐标系的变换,如点(1,1)变到(2,3),一者点动,二者让X轴单位度量长度变成原来1/2,让Y轴单位度量长度变成原来1/3。
6、Ma=b,点动则是向量a经过矩阵M所描述的变换,变成了向量b;变坐标系则是有一个向量,它在坐标系M的度量下结果为a,在坐标系I(I为单位矩阵,主对角为1,其它为0)的度量下结果为b,本质上点运动与变换坐标系两者等价。为何?如(6)所述,同一个变换,不同坐标系下表现不同矩阵,但本质相同。
7、Ib,I在(6)中说为单位坐标系,其实就是我们常说的直角坐标系,如Ma=Ib,在M坐标系里是向量a,在I坐标系里是向量b,本质上就是同一个向量,故此谓矩阵乘法计算无异于身份识别。且慢,什么是向量?放在坐标系中度量,后把度量的结果(向量在各个坐标轴上投影值)按顺序排列在一起,即成向量。
8、b在I坐标系中-〉Ib,a在M坐标系中-〉Ma,故而矩阵乘法MxN,不过是N在M坐标系中度量得到-〉MN,而M本身在I坐标系中度量出。故Ma=Ib,M坐标系中的a转过来在I坐标系中一量,却成了b。如向量(x,y)在单位长度均为1的直角坐标系中一量-〉(1,1),在X轴单位长度为2.Y轴单位长度为3一量-〉(2,3)。
9、何谓逆矩阵? Ma=Ib,之前已明了点变换a-〉b等价于坐标系变换M-〉I,但具体M如何变为I呢,答曰让M乘以M的逆矩阵。以坐标系


1.1 一堆基础概念
 的方形矩阵,其主对角线元素为1,其余元素为0。单位矩阵以
的方形矩阵,其主对角线元素为1,其余元素为0。单位矩阵以 表示;如果阶数可忽略,或可由前后文确定的话,也可简记为
表示;如果阶数可忽略,或可由前后文确定的话,也可简记为 (或者E)。 如下图所示,便是一些单位矩阵:
(或者E)。 如下图所示,便是一些单位矩阵:


 。单位向量同时也是单位矩阵的特征向量,特征值皆为1,因此这是唯一的特征值,且具有重数
。单位向量同时也是单位矩阵的特征向量,特征值皆为1,因此这是唯一的特征值,且具有重数  。
。  的正规化向量(即单位向量)
的正规化向量(即单位向量) 就是平行于
就是平行于 的单位向量,记作:
的单位向量,记作:
这里
 是
是 的范数(长度)。
的范数(长度)。
 = [a1, a2,…, an]和
= [a1, a2,…, an]和 = [b1, b2,…, bn]的点积定义为:
= [b1, b2,…, bn]的点积定义为:



 指示矩阵
指示矩阵
除了上面的代数定义外,点积还有另外一种定义:几何定义。在欧几里得空间中,点积可以直观地定义为 :
:

这里| |
|表示
 的模(长度),θ表示两个向量之间的角度。 根据这个定义式可得:两个互相垂直的向量的点积总是零。若和
的模(长度),θ表示两个向量之间的角度。 根据这个定义式可得:两个互相垂直的向量的点积总是零。若和 都是单位向量(长度为1),它们的点积就是它们的夹角的余弦。
都是单位向量(长度为1),它们的点积就是它们的夹角的余弦。
正交是垂直这一直观概念的推广,若内积空间中两向量的内积(即点积)为0,则称它们是正交的,相当于这两向量垂直,换言之,如果能够定义向量间的夹角,则正交可以直观的理解为垂直。而正交矩阵(orthogonal matrix)是一个元素为实数,而且行与列皆为正交的单位向量的方块矩阵(方块矩阵,或简称方阵,是行数及列数皆相同的矩阵。)


 ,则
,则
 的一个特征向量,
的一个特征向量, 沿其对做了手脚,使得向量变长或变短了,但本身的方向不变。
沿其对做了手脚,使得向量变长或变短了,但本身的方向不变。 的对角线元素之和,也是其
的对角线元素之和,也是其
2 拉普拉斯矩阵
2.1 Laplacian matrix的定义
 ,其拉普拉斯矩阵被定义为:
,其拉普拉斯矩阵被定义为:


 ,可得拉普拉斯矩阵为:
,可得拉普拉斯矩阵为:
2.2 拉普拉斯矩阵的性质
- L 是对称半正定矩阵;
- L 的最小特征值是0,相应的特征向量是

- L 有n个非负实特征值

- 且对于f,有以下式子成立

更多拉普拉斯矩阵的性质请参考参考文献6:“A Tutorial on Spectral Clustering”。

3 谱聚类
- 无向图G=(V,E)
- 邻接矩阵W
- 顶点的度d,形成一个度矩阵D (对角阵)

- 子图A的指示向量如下:

- A组与B租之间所有边的权值之和定义如下:

 定义为节点
定义为节点 到节点
到节点 的权值,如果两个节点不是相连的,权值为零。
的权值,如果两个节点不是相连的,权值为零。3.1 目标函数

其中k表示分成k个组,Ai表示第i个组, 表示第Ai的补集,W(A,B)表示第A组与第B组之间的所有边的权重之和(换言之,如果要分成K个组,那么其代价就是进行分割时去掉的边的权值的总和)。
表示第Ai的补集,W(A,B)表示第A组与第B组之间的所有边的权重之和(换言之,如果要分成K个组,那么其代价就是进行分割时去掉的边的权值的总和)。
为了让被切断边的权值之和最小,便是要让上述目标函数最小化。但很多时候,最小化cut 通常会导致不好的分割。以分成2类为例,这个式子通常会将图分成了一个点和其余的n-1个点。为了让每个类都有合理的大小,目标函数应该显示的要求A1,A2...Ak足够大。
改进后的目标函数为:

其中|A|表示A组中包含的顶点数目。
或:

其中, 。
。
4 参考文献与推荐阅读
- 孟岩之理解矩阵系列:http://blog.csdn.net/myan/article/details/1865397;
- 理解矩阵的12点数学笔记:http://www.51weixue.com/thread-476-1-1.html;
- 一堆wikipedia,比如特征向量:https://zh.wikipedia.org/wiki/%E7%89%B9%E5%BE%81%E5%90%91%E9%87%8F;
- wikipedia上关于拉普拉斯矩阵的介绍:http://en.wikipedia.org/wiki/Laplacian_matrix;
- 邹博之聚类PPT:http://pan.baidu.com/s/1i3gOYJr;
- 关于谱聚类的一篇非常不错的英文文献,“A Tutorial on Spectral Clustering”:http://engr.case.edu/ray_soumya/mlrg/Luxburg07_tutorial_spectral_clustering.pdf;
- 知乎上关于矩阵和特征值的两个讨论:http://www.zhihu.com/question/21082351,http://www.zhihu.com/question/21874816;
- 谱聚类:http://www.cnblogs.com/fengyan/archive/2012/06/21/2553999.html;
- 谱聚类算法:http://www.cnblogs.com/sparkwen/p/3155850.html;
- 漫谈 Clustering 系列:http://blog.pluskid.org/?page_id=78;
图的拉普拉斯矩阵(Graph Laplacians)
版权声明:本文为博主原创文章,未经博主允许不得转载。
Definition
如前述文章“图的基本知识”中所述,对于一个具有个顶点的图
,用对角阵
描述图各顶点的度,矩阵
为其邻接矩阵,则定义Laplacian matrix
为:
对于一个无向加权图( ),
是对称阵且每个元素表示为:
其中 为顶点
的度,且
。
【以下均针对无向加权图进行描述】
Properties
1. 是对称的半正定矩阵;
2. 具有
个非负的实数特征值:
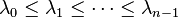 ,且
,且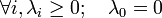 ,其对应的特征向量
,其对应的特征向量![\mathbf{v_0}=[1,1,\dots,1]](http://upload.wikimedia.org/math/1/9/8/198a0eddd6adb3a5bba237e099cb17ad.png) ;
;
3. 特征值为0的个数等于图
连通分支的数目;
4. 对于任一为的向量
,有:
具体证明过程可参见文献[2].
Normalized laplacian matrix
有两种Normalized 拉普拉斯矩阵:
(1) Symmetric normalized Laplacian
(2) Random walk normalized Laplacian
Applications
Spectral graph theory图谱论,就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质,当前视觉领域的Spectral Clustering, Spectral Hashing,Graph Cut, Normalized Cut, Min-Cut等等技术都是通过Spectral graph theory来实现的。
参考文献
[1] http://en.wikipedia.org/wiki/Laplacian_matrix
[2]http://www.kyb.mpg.de/fileadmin/user_upload/files/publications/attachments/Luxburg07_tutorial_4488%5b0%5d.pdf
谱聚类Spectral Clustering
版权声明:本文为博主原创文章,未经博主允许不得转载。
Definition
spectral clustering techniques make use of thespectrum (eigenvalues) of thesimilarity matrix of the data to performdimensionality reduction before clustering in fewer dimensions. The goal of spectral clustering is to partition the dataset into disjoint subsets with high intra-cluster similarity and low inter-cluster similarity.
由此可见,谱聚类就是一个图分割问题。用无向图 描述
维空间的数据点集
,
,其中每条边
关联一个权值
,描述点
和
之间的相似度,则图的邻接矩阵可用相似度矩阵
且
表示。
Similarity graph&matrix
在维空间中,用一个相似度函数
描述两点之间的相似度,如用高斯核
计算相似度。相似度矩阵的构建过程就是描述数据点集
中各数据点局部邻域关系图的过程,常用的构建方法有:
1. K-Nearest Neighbor
若是
的KNN邻接点,则
和
之间存在一条边
,with
=
,由于KNN不是相互的,即
是
的KNN邻接点但
不一定是
的KNN邻接点,由此产生的图就是一个有向图,为使其变为无向图常采用:(1) 直接忽略边的方向,即
和
只要存在一个方向的KNN邻接点对,则
和
就连接一条边,称为KNN-Graph;(2) 只有在
和
互为KNN邻接点时,
和
才连接一条边,称为Mutual KNN-Graph。
2. -Neighborhood
用阈值来描述一个点的邻域关系,即当
与
的距离小于
时,
和
之间就存在一条边
。
3. Full connected
任意的两点之间都存在一条边,与边关联的权值能够反映点之间的邻域关系,如高斯核 中的
就能控制邻域的大小。
基于上述3种邻域图的构建方法,相应的邻接矩阵 也可随之产生。
Spectral clustering
基于上述构建的图和相似度矩阵,可采用拉普拉斯矩阵来执行谱聚类,具体过程如下:
(1) Unnormalized spectral clustering
Input: Dataset and the similarity matrix
, number k of clusters to construct.
• Construct a similarity graph by one of the ways described in the above section. Let be its weighted adjacency matrix.
• Compute the unnormalized Laplacian .
• Compute the first k eigenvalue of and the corresponding eigenvectors
.
• Let be the eigenvector matrix containing the vectors
as columns.
• For , let
be the vector corresponding to the i-th row of
thus
is
dimensions.
• Cluster the points (
)with the k-means algorithm into clusters
.
Output: Clusters with
By “the first k eigenvectors” we refer to the eigenvectors corresponding to the k smallest eigenvalues (exclude as it always be zero).
(2) Normalized spectral clustering with
Input: Dataset and the similarity matrix
, number k of clusters to construct.
• Construct a similarity graph by one of the ways described in the above section. Let be its weighted adjacency matrix.
• Compute the unnormalized Laplacian .
• Compute the first k generalized eigenvectors of the generalized eigenproblem
.
• Let be the eigenvector matrix containing the vectors
as columns.
• For , let
be the vector corresponding to the i-th row of
thus
is
dimensions.
• Cluster the points (
)with the k-means algorithm into clusters
.
Output: Clusters with
As the normalized Laplacian Matrix , thus
====》
. So in fact the alogrithm works with normalized Laplacian Matrix
.
(3) Normalized spectral clustering with
Input: Dataset and the similarity matrix
, number k of clusters to construct.
• Construct a similarity graph by one of the ways described in the above section. Let be its weighted adjacency matrix.
• Compute the normalized Laplacian ,
.
• Compute the first k eigenvalue of andthe corresponding eigenvectors
.
• Let be the eigenvector matrix containing the vectors
as columns.
• Normalize each row of to norm 1 by
• For , let
be the vector corresponding to the i-th row of
thus
is
dimensions.
• Cluster the points (
)with the k-means algorithm into clusters
.
Output: Clusters with
参考文献
[1] http://en.wikipedia.org/wiki/Spectral_clustering
[2]http://www.kyb.mpg.de/fileadmin/user_upload/files/publications/attachments/Luxburg07_tutorial_4488%5b0%5d.pdf
[3] http://csustan.csustan.edu/~tom/Lecture-Notes/Clustering/GraphLaplacian-tutorial.pdf
[4] https://cwiki.apache.org/MAHOUT/spectral-clustering.html
谱哈希spectral hashing
版权声明:本文为博主原创文章,未经博主允许不得转载。
请先阅读有关图的基本知识,图的拉普拉斯矩阵分析以及谱聚类相关内容,谱哈希基于上述技术基础。
谱哈希对图像特征向量的编码过程可看做是图分割问题,借助于对相似图的拉普拉斯矩阵特征值和特征向量的分析可对图分割问题提供一个松弛解。由谱聚类可知,相似图拉普拉斯矩阵的特征向量实际上就是原始特征降维后的向量,但其并不是0-1的二值向量,可通过对特征向量进行阈值化产生spectral hashing的二值编码(The bits in spectral hashing are calculated by thresholding a subset of eigenvectors of Laplacians of the similar graph).
若原始特征向量空间用高斯核度量相似度 ,则令
为二值化后的特征向量矩阵即经Spectral Hashing后的二值特征向量,则在低维Hamming空间的平均Hamming距离可表示为
。此外,What makes good code?
(1) each bit has 50% chance of being 0 or 1;
(2) the bits are independent of each other(always relaxed to uncorrelated).
因此,spectral hashing的编码过程可描述为下述的优化问题(为了求解问题的方便,将二值中的0表示为-1):
用Spectral 理论描述为:
若没有二值的约束 ,则上述优化问题就简化为
是拉普拉斯矩阵
的
个最小特征值所对应的特征向量构成的矩阵,通过简单的Thresholding可获取Binary Code。
但上述的编码过程仅适用于训练集,而我们需要的是能够泛化到任意给定的out-of-example特征向量,因此引入来描述原始特征空间中数据点的概率分布,则上述的优化问题可表述为:
当暂不考虑二值化约束时,上述优化问题的解即是eigenfunctions of weighted Laplace-Beltramician operactor with
minimal eigenvalue. And with proper normalization, the eigenvectors of the discrete Laplacian defined by
points sampled from
coverges to eigenfunctions of
as
.
因此,就转化为如何利用服从分布的
个离散的数据点求取
的特征方程的问题:
当是separable distribution时,即
,亦即各维之间相互独立时,
的特征方程具有outer product 形式:
即若 是特征值
对应的一维空间
的特征方程,则
是特征值
对应的
维空间的特征方程。特别的,针对
区间内均匀可分离的分布
,一维空间的特征值和特征向量可通过下式求得:
----------function (1)
,
----------function (2)
Summarize the spectral hashing alogrithm:
Input: data points
and the hashed bits
- Finding the
principal components of the data using PCA;
- Calculating the
smallest single-dimension analytical eigenfunctions of
along every PCA direction. This is done by evaluating the
eigenvalues, and then sorting this list to find the
- Thresholding the analytical eigenfunctions at zero, to obtain binary codes.
分析:
Step1中PCA的主要作用是align the axes for data points, 也就是使数据点各维之间相互独立,符合seperate distribution;
Step2个人理解应该是先求取维数据点每一维
均匀分布区间
,然后利用方程(2)求取每一维对应的最小的
个特征值
,因此总计有
个特征值。然后在
个特征值中选取最小的
个,并记录其所对应的向量维度
及其特征值序号
,即
对;针对选取的
各最小特征值,计算其对应的一维特征方程
。
Step3是采用符号函数,对选取的特征方程进行二值化,产生二值码
由此可见,对图的次分割,每次都是选取
维空间的某一维,并没有利用特征方程的outer-product的特性,paper 中的解释是二值化编码采用的是符号函数,且
,因此一个bit的取值可由其它bits确定,失了去独立性。但其前提是建立在每一个bit对应的特征方程是由其它bits对应特征方程的outer-product,若bits之间不包含相同的特征方程,则还会继续保留各bits之间的独立性。因此outer-product的特征方程应该也可以利用。这仅是个人理解,具体效果还有待验证。
训练集的作用主要是产生每维对应的分布区间,利用记录的
个最小特征值对应的维度与特征值序号对
扩展至out-of-example。
参考文献
[1] http://www.cs.huji.ac.il/~yweiss/SpectralHashing/ 包含了paper和matlab源码
- 图知识
- 知识的图化
- NOSQL数据库知识图
- 图的知识归纳
- 技术知识图
- 技术知识图
- 知识框架图 存档
- 技术知识图
- 二分图相关知识
- JAVA知识导图
- 各种知识图
- 第一章 知识导图
- 第一节知识导图
- 第一章知识导图
- 第一章知识导图
- 第一章知识导图
- 第一章知识导图
- Android知识框架图
- linux 查看磁盘容量,文件,文件内容,分析日志等常用命令
- Sublime插件
- 【完美解决】android开发 自定义字体安装包过大的问题
- 【SSH】——ORM基础
- ubuntu忘记密码 修改密码报错 Authentication token manipulation error解决
- 图知识
- Hello world
- PAT_乙级1016
- Poj1845
- eclipse中查找文件
- java日志记录的5条规则
- EMR、EHR和PHR的定义与对比
- poj3641
- 类加载


