CPU 的 cache 和 latency_立华软件园_游戏开发->程序设计->优化调试
来源:互联网 发布:品牌网络销售授权书 编辑:程序博客网 时间:2024/04/28 01:09
文档内容简介:
这篇文章主要是探讨现在的 CPU 的 cache 和内存系统之间的关系。
目录:
[Part 1]
[Part 2]
文档内容:
[Part 1]
CPU 速度的进展,一直比内存的速度进展要来得快。在 IBM PC XT 的时代,CPU 和内存的速度是差不多的。不过,后来 CPU 的速度就愈来愈快。再加上 DRAM 需要 refresh 才能保存数据的特性,DRAM 很快就跟不上 CPU 的速度了。现在的 CPU 都利用了 pipeline 的方式,可以每个 cycle 都 issue 一个(甚至多个)指令,再加上现在的 CPU 频率也比内存的频率高,内存的速度可说是远远落在 CPU 之后了。
为了避免内存成为 CPU 速度的瓶颈,现在的 CPU 都有 cache 的设计,甚至还有多层的 cache。Cache 的原理,主要是利用到大部分的程序,在处理数据时,都有一定程度的区域性。所以,我们可以用一小块快速的内存,来暂存目前需要的数据。
例如,几乎所有的程序,大部分的执行时间是花在一些循环中。这些循环通常都不大,可能只占整个程序空间的百分之一。如果一个程序经常要执行这段程序数千、甚至数万次,那就可以把这一小段程序放在 cache 中,CPU 就不需要每次都到很慢的主存储器中读取这段程序了。很多一般用途的程序,在存取数据时,也有类似的特性。因此,cache 的帮助非常大。如果没有 cache 的话,我们就不需要这么快的 CPU 了,因为系统的速度会卡在内存的速度上面。
现在的 CPU 往往也有多层的 cache。例如,Intel 的 Pentium III 500Mhz CPU,有 32KB 的 L1 cache,和 512KB 的 L2 cache。其中,L1 cache 内建在 CPU 内部,速度非常快,而且它是 Harvard 式,即指令用的空间和数据用的空间是分开的。Pentium III 500Mhz CPU 的 L1 cache 是分成 16KB 的 I-cache 和 16KB 的 D-cache。而 L2 cache 则是在 CPU 外面,以 250Mhz 的速度运作。另外,它和 CPU 之间的 bus 也只有 64 bits 宽。L2 cache 通常就不会区分指令和数据的空间,也就是 unified cache。
Cache 对速度有什么影响呢?这可以由 latency 来表示。CPU 在从内存中读取数据(或程序)时,会需要等待一段时间,这段时间就是 latency,通常用 cycle 数表示。例如,一般来说,如果数据已经在 L1 cache 中,则 CPU 在读取数据时(这种情形称为 L1 cache hit),CPU 是不需要多等的。但是,如果数据不在 L1 cache 中(这种情形称为 L1 cache miss),则 CPU 就得到 L2 cache 去读取数据了。这种情形下,CPU 就需要等待一段时间。如果需要的数据也不在 L2 cache 中,也就是 L2 cache miss,那么 CPU 就得到主存储器中读取数据了(假设没有 L3 cache)。这时候,CPU 就得等待更长的时间。
另外,cache 存取数据时,通常是分成很多小单位,称为 cache line。例如,Pentium III 的 cache line 长度是 32 bytes。也就是说,如果 CPU 要读取内存地址 0x00123456 的一个 32 bits word(即 4 bytes),且 cache 中没有这个资料,则 cache 会将 0x00123440 ~ 0x0012345F 之间的 32 bytes 数据(即一整个 cache line 长度)都读入 cache 中。所以,当 CPU 读取连续的内存地址时,数据都已经读到 cache 中了。
我写了一个小程序,用来测试 cache 的行为。这个程序会连续读取一块内存地址,并量测平均读取时间。这个程序的执行结果如下:
测试平台:
- Pentium III 500Mhz, PC100 SDRAM, 440BX chipset
- Celeron 466Mhz, PC100 SDRAM, VIA Apollo Pro 133 chipset

程序的执行文件和原始码可在这里下载。
由上面的结果可以看出,当测试的区块大小在 16KB 以下时,平均的 latency 都在 1 ~ 3 cycles 左右。这显示出 16KB 的 L1 D-cache 的效果。在测试区块为 1KB 和 2KB 时,因为额外的 overhead 较高,所以平均的 latency 变得较高,但是在 4KB ~ 16KB 的测试中,latency 则相当稳定。在这个范围中,由于 Pentium III 和 Celeron 有相同的 L1 cache,所以测试结果是几乎完全相同的。
在区块超过 16KB 之后,就没办法放入 L1 D-cache 中了。但是它还是可以放在 L2 cache 中。所以,在 Pentium III 的情形下,从 32KB ~ 512KB,latency 都在 10 cycles 左右。这显示出当 L1 cache miss 而 L2 cache hit 时,所需要的 latency。而 Celeron 的 L2 cache 只有 128KB,但是 Celeron 的 L2 cache 的 latency 则明显的比 Pentium III 为低。这是因为 Celeron 的 L2 cache 是 on-die,以和 CPU 核心相同的速度运作。而 Pentium III 的 L2 cache 则是分开的,且以 CPU 核心速度的一半运作。
在区块超过 512KB 之后,L2 cache 就不够大了(Pentium III 500Mhz 只有 512KB 的 L2 cache)。这时,显示出来的就是 L1 cache miss 且 L2 cache miss 时,所需要的 latency。在 1024KB 或更大的区块中,Pentium III 的 latency 都大约是 28 cycles 左右,而 Celeron 的 latency 则超过 70 cycles。这是 CPU 读取主存储器时,平均的 latency。而 Celeron 的 latency 较高,应该是因为其外频较低,而倍频数较高的缘故(Pentium III 500Mhz 为 5 倍频,而 Celeron 466 为 7 倍频)。另外,芯片组的差异也可能是原因之一。
Cache 的效果十分明显。不过,有时候 cache 是派不上用场的。例如,当数据完全没有区域性,或是数据量太大的时候,都会让 cache 的效果降低。例如,在进行 MPEG 压缩时,存取的数据量很大,而且数据的重复利用率很低,所以 cache 的帮助就不大。另外,像是 3D 游戏中,如果每个 frame 的三角面个数太多,也会超过 cache 能够处理的范围。
现在的计算机愈来愈朝向「多媒体应用」,需要处理的资料量也愈来愈大,因此,要如何善用 cache 就成了一个重要的问题。一个非常重要的方法,就是把读取主存储器的 latency 和执行运算的时间重迭,就可以把 latency「藏」起来。通常这会需要 prefetch 的功能,也就是 AMD 在 K6-2 及之后的 CPU,和 Intel 在 Pentium III 之后的 CPU 加入的新功能。在下一篇文章中,我们会讨论 prefetch 的原理和用途。
[Part 2]
在上一篇文章中,已经简单讨论过 CPU 的 cache 和其对 latency 的影响。在这篇文章中,我们就以一个较为实际的例子,并说明 prefetch 的原理和用途。
这里要用的「实际例子」,其实还是很理想化的。为了和 3D 绘图扯上一点关系,这里就用「4x4 的矩阵和 4 维向量相乘」做为例子。不过,一般在 3D 绘图中,都是用 single precision 的浮点数(每个数需要 32 bits),而这里为了让内存的因素更明显,我们使用 double precision 的浮点数(每个数需要 64 bits),也就是一个 4 维向量刚好需要 32 bytes。
在这个例子中,我们采取一个 3D 绘图中,相当常见的动作,也就是把一大堆 4 维向量,乘上一个固定的 4x4 矩阵。如果向量的个数非常多,超过 CPU 的 cache 所能负担,那么 CPU 的表现就会大幅下降。
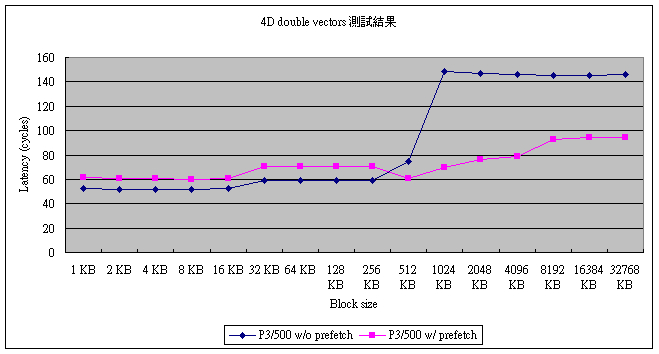
为了让大家心里有个底,这里先把执行的结果列出来:
测试平台: Pentium III 500Mhz, PC100 SDRAM, 440BX chipset
在程序集可以下载程序的原始码和执行档。
首先,我们来看没有使用 prefetch 指令的结果。事实上,结果相当符合预测。在 L1 D-cache 的范围内(即小于 16KB 的情形),平均的运算时间相当的稳定,约在 51 ~ 52 cycles 左右。这也是 Pentium III 在计算一个 4x4 矩阵和 4 维向量相乘时(使用 double precision 浮点数),可能达到的最快速度。当然,这个程序是用 C 写成的。如果直接用手写汇编语言,可能还可以再快个 5 ~ 10 cycles。
当数据量超过 L1 D-cache 的范围,但是还在 L2 cache 的范围之内时,所需的时间提高到约 60 cycles 左右。在 Part 1 中,我们已经知道 Pentium III 500Mhz 的 L2 cache 大约有 10 cycles 的 latency,所以这个结果也是相当合理的。
当资料量超过 L2 cache 的范围时,所有的数据就需要从主存储器中取得了。从图上可以很容易的看到,每次运算所需的时间增加到 145 ~ 150 cycles。这有点出乎意料之外:在 Part 1 中,读取主存储器的 latency 只有 30 cycles 左右,但是在这里,latency 增加了约 100 cycles。不过,这个结果并不奇怪。因为在运算结束后,运算的结果必须要写回内存中,而写回内存的动作,需要很多时间。
从这里可以看到,在数据量超过 L2 cache 的范围时,CPU 可说是被内存的速度限制住了。事实上,如果内存的速度不变,那即使是用两倍快的 CPU,速度的增加也会非常有限。以 3D 游戏的角度来说,1024KB 或 2048KB 这样的数据量并不算少见,因为一个 single precision 浮点数的 4 维向量,就需要 16 bytes 的空间。65,536 个 4 维向量就需要 1MB 的空间了。
事实上,内存的速度虽慢,但是要完成一个 32 bytes(一个四维向量的大小)的读写动作,也只需要 60 ~ 70 cycles 而已(以 Pentium III 500Mhz 配合 PC100 SDRAM 的情形来算)。而在不用 prefetch 的情形下,CPU 的动作类似下图所示:
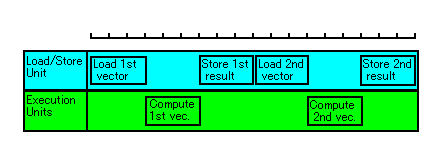
在上图中,CPU 的运算单元(即图中的 Execution Units)大部分的时间都在等待数据输入。而 Load/Store Unit 也有不少时间是不动作的。这显然不是最好的方法,因为 CPU 的两个单元都不是全速运作。
如果我们在 CPU 的运算单元进行计算工作时,就把下一个要计算的数据先加载到 CPU 的 cache 中,那么,CPU 的动作就会变成类似下图所示:
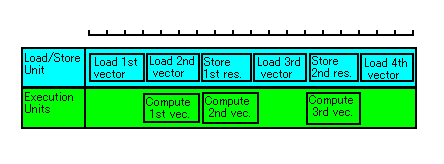
现在,Load/Store Unit 变成全速运作了。Execution Units 还是没有全速运作,但是这是没办法的。这种情形,就表示出瓶颈是在 Load/Store Unit,也就是在主存储器的速度。已经没有任何方法可以加快执行的速度了(除非加快内存的速度)。
要注意的一点是,上面的情形是很少发生的真实世界中的。实际的程序,通常瓶颈都是在运算单元。不过,我们的例子则刚好不是这样(因为矩阵和向量相乘是很简单的运算),而是类似图中的情形。
要怎么告诉 CPU,在计算的同时将下一个数据加载到 cache 中呢?这时就要用到 prefetch 的指令了。在我们的程序中,执行向量运算的程序如下:
- for(i = 0; i < buf_size; i += 4) {
- double r1, r2, r3, r4;
-
- // 执行矩阵乘法
- r1 = m[0] * v[i] + m[1] * v[i+1] + m[2] * v[i+2] + m[3] * v[i+3];
- r2 = m[4] * v[i] + m[5] * v[i+1] + m[6] * v[i+2] + m[7] * v[i+3];
- r3 = m[8] * v[i] + m[9] * v[i+1] + m[10] * v[i+2] + m[11] * v[i+3];
- r4 = m[12] * v[i] + m[13] * v[i+1] + m[14] * v[i+2] + m[15] * v[i+3];
-
- // 写回计算结果
- v[i] = r1;
- v[i+1] = r2;
- v[i+2] = r3;
- v[i+3] = r4;
- }
现在,我们在矩阵乘法的前面插入一个 prefetch 指令,变成:
- for(i = 0; i < buf_size; i += 4) {
- double r1, r2, r3, r4;
-
- // 执行矩阵乘法
- r1 = m[0] * v[i] + m[1] * v[i+1] + m[2] * v[i+2] + m[3] * v[i+3];
- // 前一行执行完后,整个 4 维向量已经加载到 cache 中。
- // 所以,现在用 prefetch 指令加载下一个 4 维向量。
- prefetch(v + i + 4);
- // 继续进行计算
- r2 = m[4] * v[i] + m[5] * v[i+1] + m[6] * v[i+2] + m[7] * v[i+3];
- r3 = m[8] * v[i] + m[9] * v[i+1] + m[10] * v[i+2] + m[11] * v[i+3];
- r4 = m[12] * v[i] + m[13] * v[i+1] + m[14] * v[i+2] + m[15] * v[i+3];
-
- // 写回计算结果
- v[i] = r1;
- v[i+1] = r2;
- v[i+2] = r3;
- v[i+3] = r4;
- }
这段程序中的 prefetch 函式,里面执行的是 SSE 的 prefetchnta 指令。Pentium III 和 Athlon 都支持这个指令(AMD 的 K6-2 中另外有一个 prefetch 指令,是 3DNow! 指令的一部分)。这个指令会将指定的数据加载到离 CPU 最近的 cache 中(在 Pentium III 即为 L1 cache)。
只不过加上这样一行程序,执行结果就有很大的不同。回到前面的测试结果,我们可以看出,prefetch 指令,在数据已经存在 cache 中的时候,会有相当程度的 overhead(在这里是大约 10 cycles)。但是,当数据不在 cache 中的时候,效率就有明显的改善。特别是在数据量为 1024 KB 时,所需时间约为 70 cycles,说明了瓶颈确实是在 Load/Store Unit。在 1024 KB 之后,所需的 cycle 的增加,则是因为在多任务系统中难以避免的 task switch 所产生的 overhead。
由此可知,prefetch 指令对于多媒体及 3D 游戏等数据量极大的应用,是非常重要的。也可以预料,将来的程序一定会更加善用这类的功能,以达到最佳的效率。
本文转自
http://www.lihuasoft.net/news/show.php?id=3442
- CPU 的 cache 和 latency_立华软件园_游戏开发->程序设计->优化调试
- CPU 的Cache 和Latency
- CPU 的 cache 和 latency
- CPU CACHE优化 性能优化方法和技巧
- FLASH游戏开发CPU优化11条
- CPU Cache的优化:解决伪共享问题
- 进程和cpu的优化
- 【zz】 现代CPU Cache结构 和 陈首席对CPU Cache的讲解
- 关于CPU的Cache
- CPU的cache基础知识
- 走进 CPU 的 Cache
- CPU的Cache
- cpu cache的魔法
- 关于CPU Cache和Cache Line
- 多级CPU Cache的利用率
- CPU的cache line原理
- C6000系列的C64x+ Cache优化--配置,Cache miss和Cache一致性
- 【转载】C6000系列的C64x+ Cache优化--配置,Cache miss和Cache一致性
- 2008-4-7 Struts 2概述(二)
- InetAddress与String类型的转换,byte[]型与String型转换,编码解码
- 买了个笔记本USB2.0卡却用不了
- 代码解决Oracle in列表过长问题
- J2ee学习流程
- CPU 的 cache 和 latency_立华软件园_游戏开发->程序设计->优化调试
- WinCE中基于Media Player的多媒体开发
- office团队,专业的office培训团体
- 有导师学习与无导师学习
- ExtremeTable的简单配置
- 保护并利用好团队的多样性
- eXtremeTable应用
- linux下软件安装 mplayer 和 realplayer的安装与使用
- 优化调试


